Over the last several years, the field of machine learning has seen a sharp increase in innovation. We can now create pictures from text and films from text with previously unheard-of precision thanks to machine learning algorithms and systems like DALL-E 2 and Whisper AI. Now is an exciting time to practice machine learning and artificial intelligence.
What if you are just starting? It’s easy to feel overpowered and as if you’ll never be able to keep up with the constant introduction of new and improved models. The journey of a thousand miles begins with one step,” regardless of how intimidating a new experience may appear.
A deep understanding of the fundamentals is required to get to the present level of machine learning. The machine learning market is expected to grow at a compound annual growth rate (CAGR) of 39.2% to reach 117.19 billion USD by 2027, according to a new report.
Thus, this blog will provide you with an overview by going over many key machine-learning algorithms that will help in your planning, research, and progress monitoring. So, let’s get started!
What is a Machine Learning Algorithm?
Machine learning algorithms are mathematical and statistical frameworks that let computers see patterns in data and make decisions or predictions on their own without explicit programming. These algorithms form the basis of artificial intelligence and may be used to automate complex tasks like predictive analytics, picture recognition, and natural language processing.
There are four main categories into which machine learning algorithms may be divided:
- Supervised Learning Algorithms: These algorithms are trained using input-output pairs and learn from labeled data. Support vector machines (SVMs), decision trees, and linear regression are a few examples.
- Unsupervised Learning Algorithms: Algorithms for unsupervised learning work with unlabeled data to identify patterns or structures without producing preset results. Autoencoders, principal component analysis (PCA), and k-means clustering are a few examples.
- Semi-Supervised Learning Algorithms: Algorithms for semi-supervised learning combine aspects of supervised and unsupervised learning. To improve learning accuracy, they combine a significant amount of unlabeled data with a small amount of labeled data. This approach is useful when classifying data is expensive or time-consuming. Self-training, co-training, and graph-based semi-supervised learning are a few examples.
- Reinforcement Learning Algorithms: By interacting with an environment and improving decision-making skills, these algorithms learn via a reward-based method. Proximal Policy Optimization (PPO), Deep Q Networks (DQN), and Q-learning are a few examples.
From classifying emails as spam or non-spam to forecasting market prices, each machine-learning algorithm is designed to tackle a specific problem. These algorithms continue to develop as computing power and data availability increase, improving their accuracy and effectiveness in handling real-world scenarios.
Importance of Machine Learning Algorithms in Real-world Applications
Modern technology depends on machine learning (ML) algorithms, which enable automation, improve decision-making, and enhance user experiences in many different fields Their refinement of Several useful applications, including cybersecurity, marketing, finance, and healthcare, clearly shows their impact.
1. Healthcare and Medical Diagnosis
Machine learning systems have revolutionized the medical field by enabling:
- Disease Prediction and Early Diagnosis: Using medical records, genetic data, and imaging, machine learning systems diagnose diseases like cancer, diabetes, and cardiovascular conditions.
- Therapeutic Strategies Customized: AI-driven algorithms provide customized therapy choices guided by patient background and response histories.
- Medical Imaging Analysis: Radiology, pathology, and dermatology use machine learning to very precisely detect problems in X-rays, MRIs, and CT scans.
2. Financial Management and Identity of Fraud
To improve security and efficiency, the financial industry relies heavily on machine learning techniques.
- Fraud Detection: By spotting unusual spending patterns, machine learning systems help to identify fraudulent transactions.
- Algorithmic Trading: Artificial intelligence-driven trading algorithms assess past performance and present market trends to guide investing choices.
- Credit Scoring and Risk Assessment: Machine learning uses behavioral patterns and financial history analysis to evaluate loan applicants’ creditworthiness.
3. E-commerce and Recommendation Systems
Recommendation systems driven by machine learning adapt user experiences in e-commerce and entertainment.
- Product Recommendations: Using machine learning, e-commerce platforms like Amazon suggest products depending on consumers’ browsing and purchase behavior.
- Content Personalization: Streaming platforms like Netflix and Spotify help to study consumer opinions and remarks meant to improve goods and services.

4. Cybersecurity and Threat Identification
Protection of digital environments depends on machine learning methods since:
- Identifying and Mitigating Cyber Threats: AI-powered security solutions instantly identify malware, phishing attempts, and unusual network activity, therefore mitigating cyber threats.
- Anomaly Detection: Machine learning notes anomalies in system access logs, login attempts, and financial transaction data.
- Spam Filtering: Emails are categorized as spam or legitimate using machine learning.
5. Travel and Autonomous Vehicles
Through better automation and safety, machine learning is revolutionizing the transportation industry.
- Autonomous Vehicles: Machine learning models in autonomous vehicles examine real-time data from cameras, sensors, and GPS to safely negotiate.
- Traffic Management: Artificial intelligence improves traffic flow and projects congestion trends to support urban mobility.
- Route Optimization: Ride-sharing companies like Uber and Lyft use machine learning to decide the most effective routes and improve pricing policies.
6. Production and Predictive Maintenance
Machine learning is enhancing operational efficiency in manufacturing by:
- Forecasting Equipment Failures: Machine learning algorithms evaluate performance data to anticipate maintenance requirements, hence minimizing downtime and expenses.
- Quality Control and Defect Detection: AI-driven vision systems identify product flaws instantaneously, guaranteeing quality control.
- Supply Chain Optimization: Machine learning enhances inventory management and demand prediction.
Top 10 Machine Learning Algorithms to Look Out in 2025
Algorithms of machine learning are broadly classified into supervised, unsupervised, and reinforcement learning categories. Below is a list of the most common ML algorithms used in various applications.
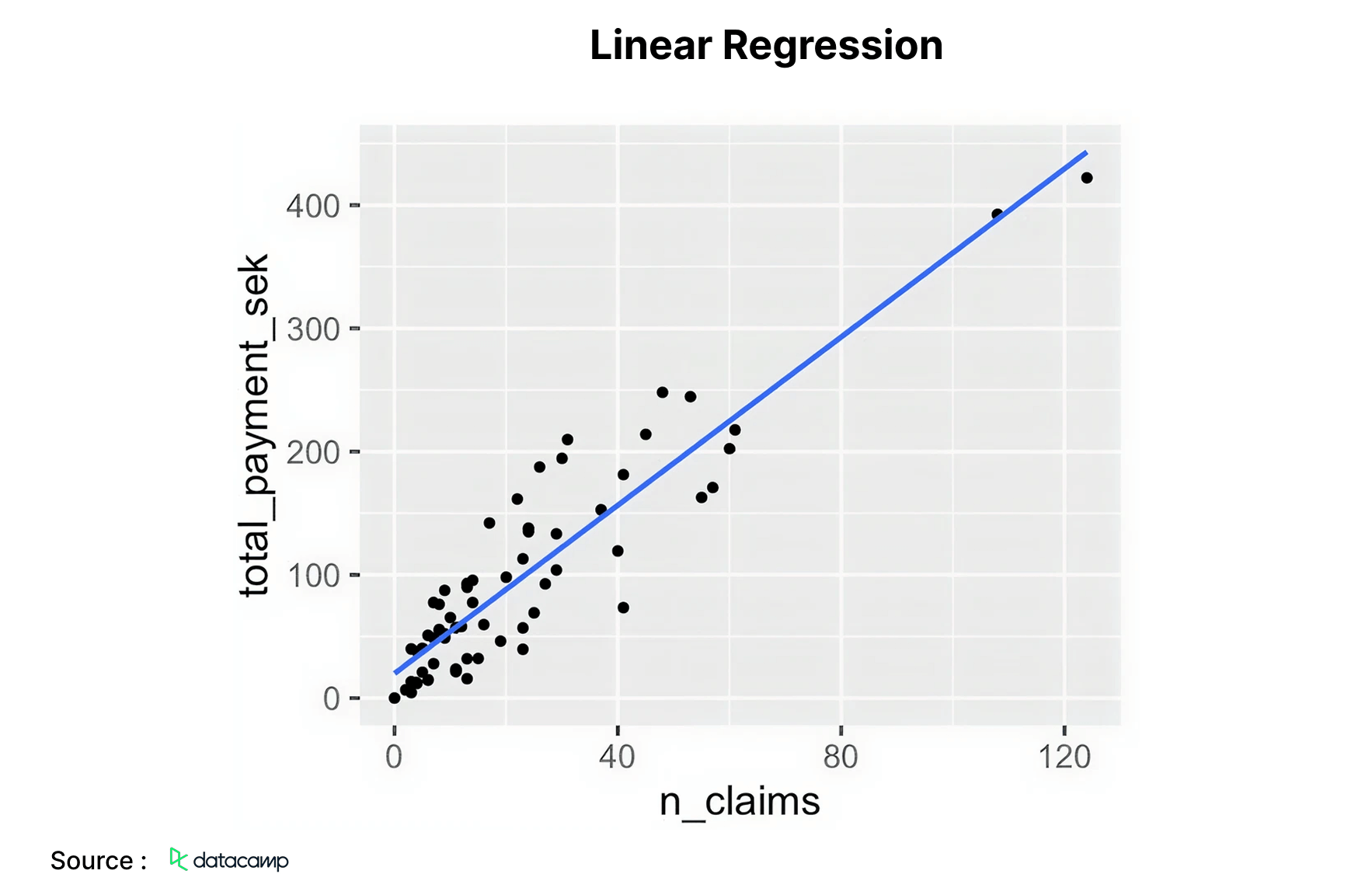
1. Linear Regression
A linear regression algorithm represents a linear correlation between one or several independent variables and a continuous numerical dependent variable. It is more expedient to train than other machine learning methods. The primary benefit resides in its capacity to elucidate and analyze the model predictions. This is a regression technique employed to forecast outcomes such as customer lifetime value, real estate values, and stock valuations.
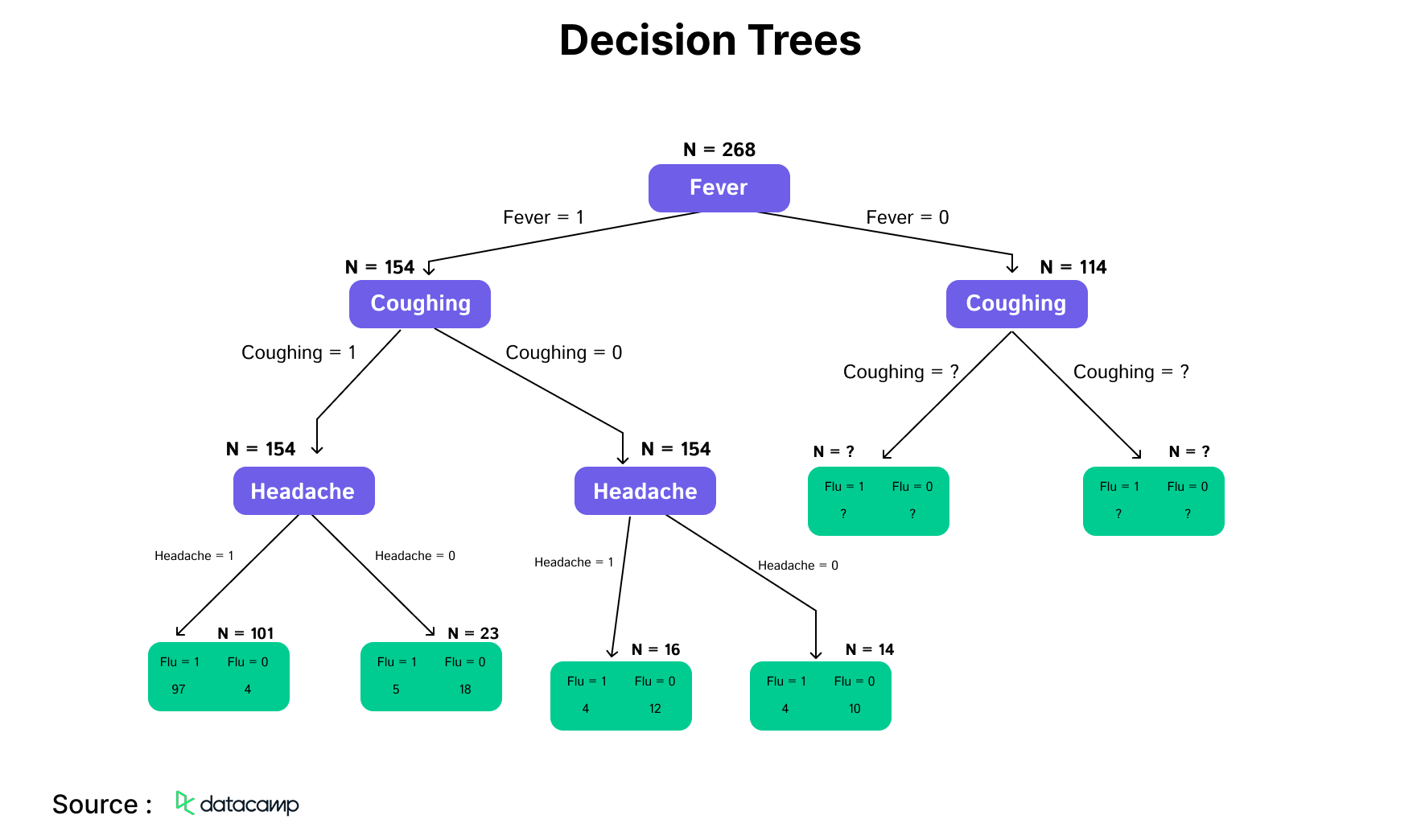
2. Decision Trees
A decision tree algorithm is a hierarchical framework of decision rules utilized to analyze input information for predicting potential outcomes. It may be utilized for classification or regression purposes. Decision tree forecasts serve as a valuable tool for healthcare professionals due to their clarity in illustrating the rationale behind the predictions.
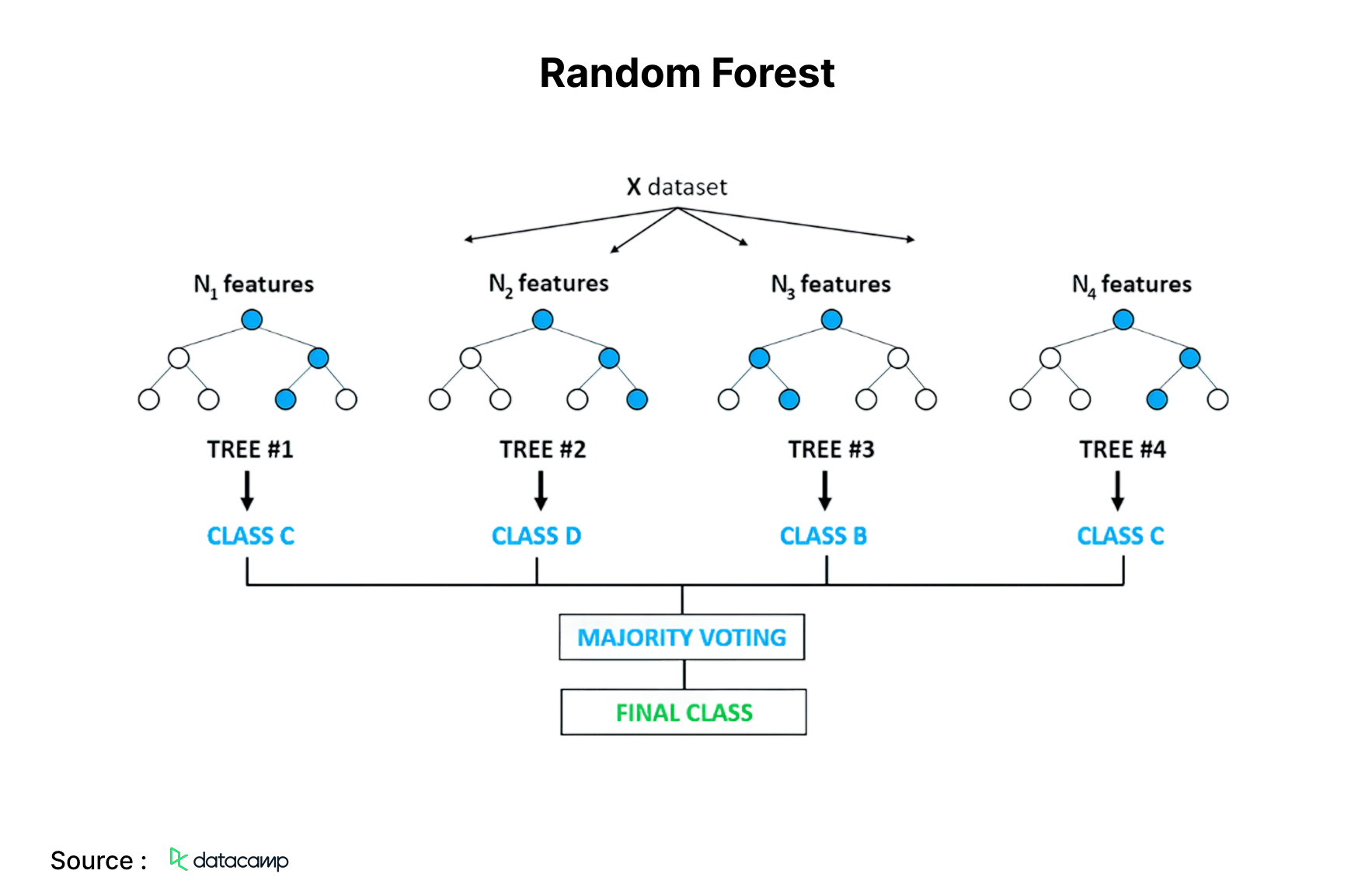
3. Random Forest
This technique is likely one of the most popular ML algorithms and addresses the overfitting issues commonly associated with decision tree models. Overfitting occurs when algorithms are excessively trained on the training data, resulting in an inability to generalize or deliver appropriate predictions on novel data. The random forest algorithm mitigates overfitting by constructing several decision trees based on randomly chosen subsets of the data.
The ultimate result, represented by the most accurate forecast, is obtained by the overall majority judgment of all the trees in the forest. It is utilized for both classification and regression tasks. It is utilized in feature selection, illness identification, and similar areas.
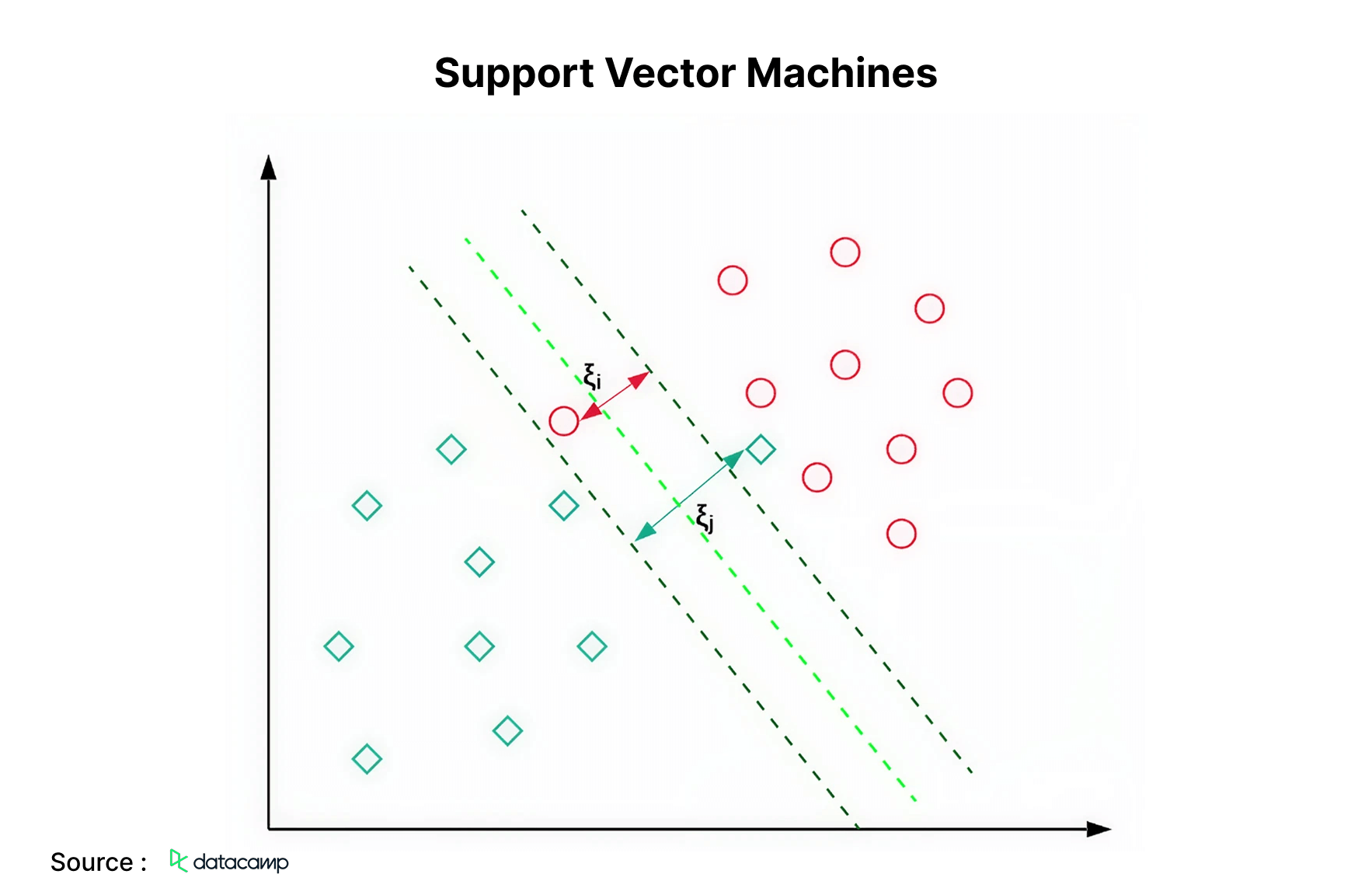
4. Support Vector Machines
Support Vector Machines, abbreviated as SVM, are primarily employed for classification tasks. The machine learning algorithm example below illustrates that an SVM identifies a hyperplane (in this instance, a line) that separates the two classes (red and green) while maximizing the margin (the distance between the dashed lines) between them. Support Vector Machines (SVMs) are mostly utilized for classification tasks, although they may also be applied to regression issues. It is utilized for the classification of news items and handwriting recognition.
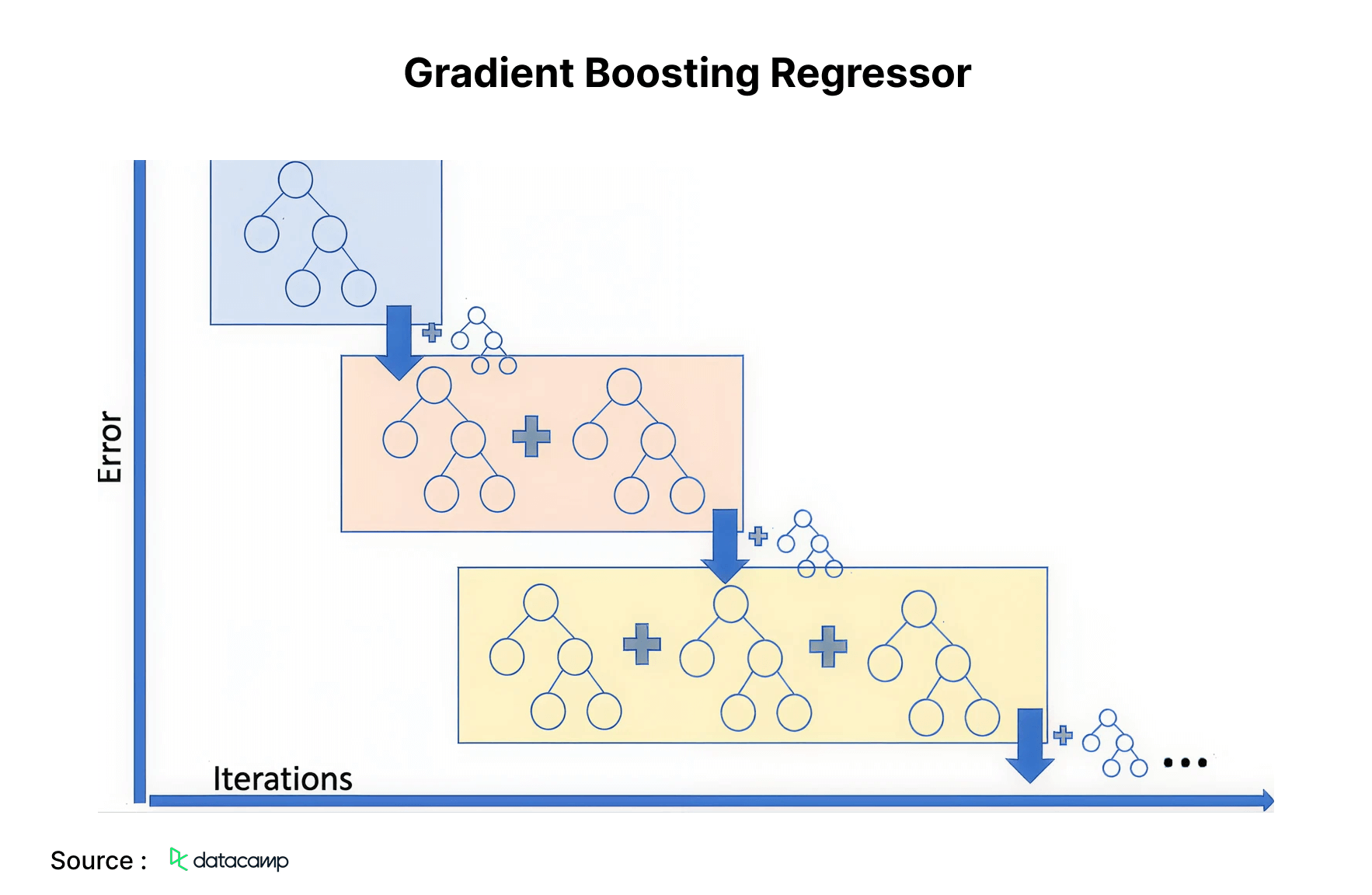
5. Gradient Boosting Regressor
Gradient Boosting Regression is an ensemble model that integrates many weak learners to create a robust prediction framework. It effectively manages non-linearities in the data and addresses multicollinearity concerns. In the ride-sharing industry, to forecast the fare amount, one can employ a gradient-boosting regressor.
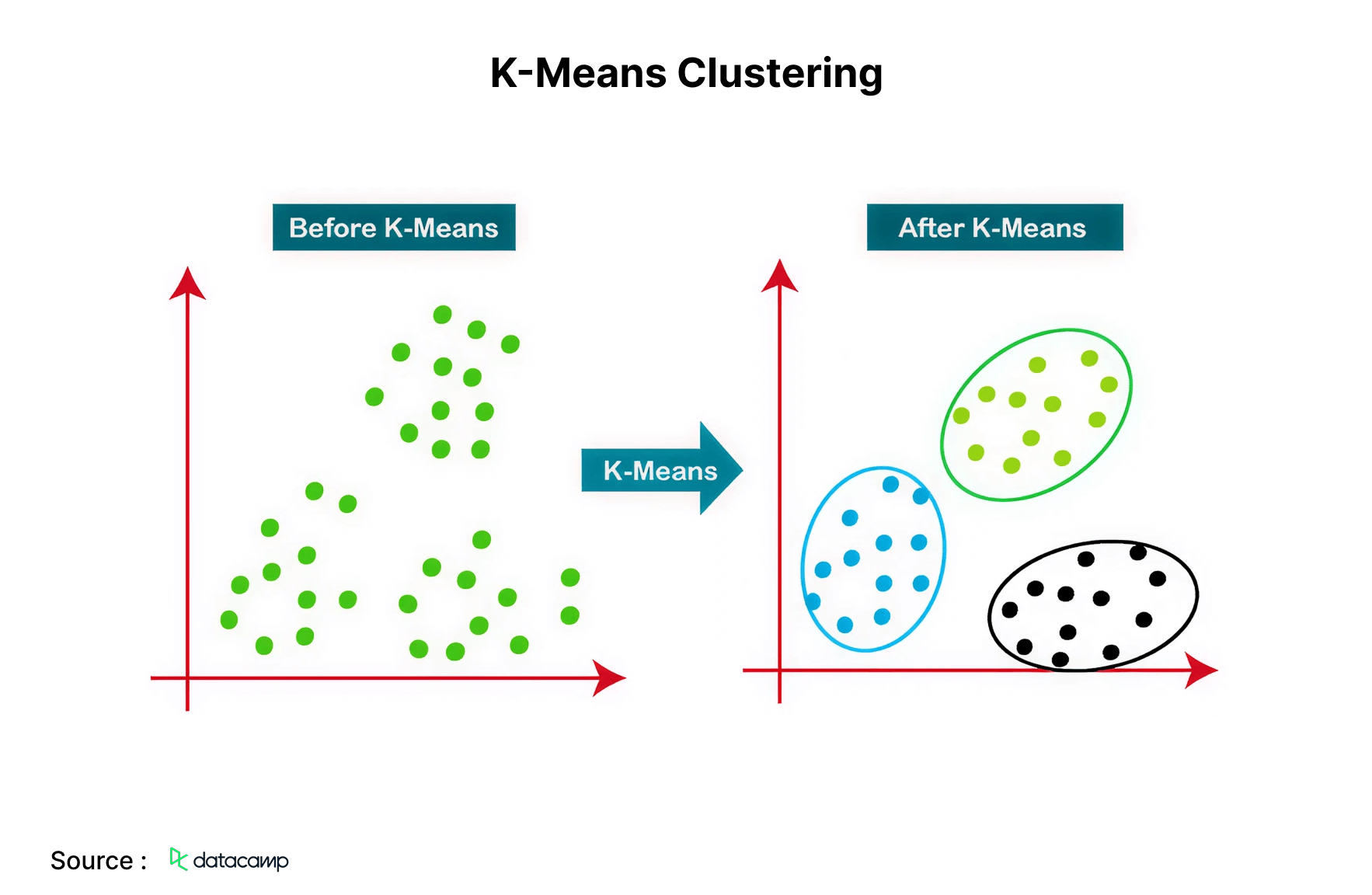
6. K-Means Clustering
K-Means is the predominant clustering method; it identifies K clusters utilizing Euclidean distance. This algorithm is widely utilized for consumer segmentation and recommendation systems.
7. Principal Component Analysis
Next on the machine learning algorithms list is Principal component analysis (PCA). It is a statistical method employed to condense information from an extensive data set by projecting it into a lower-dimensional subspace. It is referred to as a dimensionality reduction strategy that preserves the critical components of the data with more informational value.
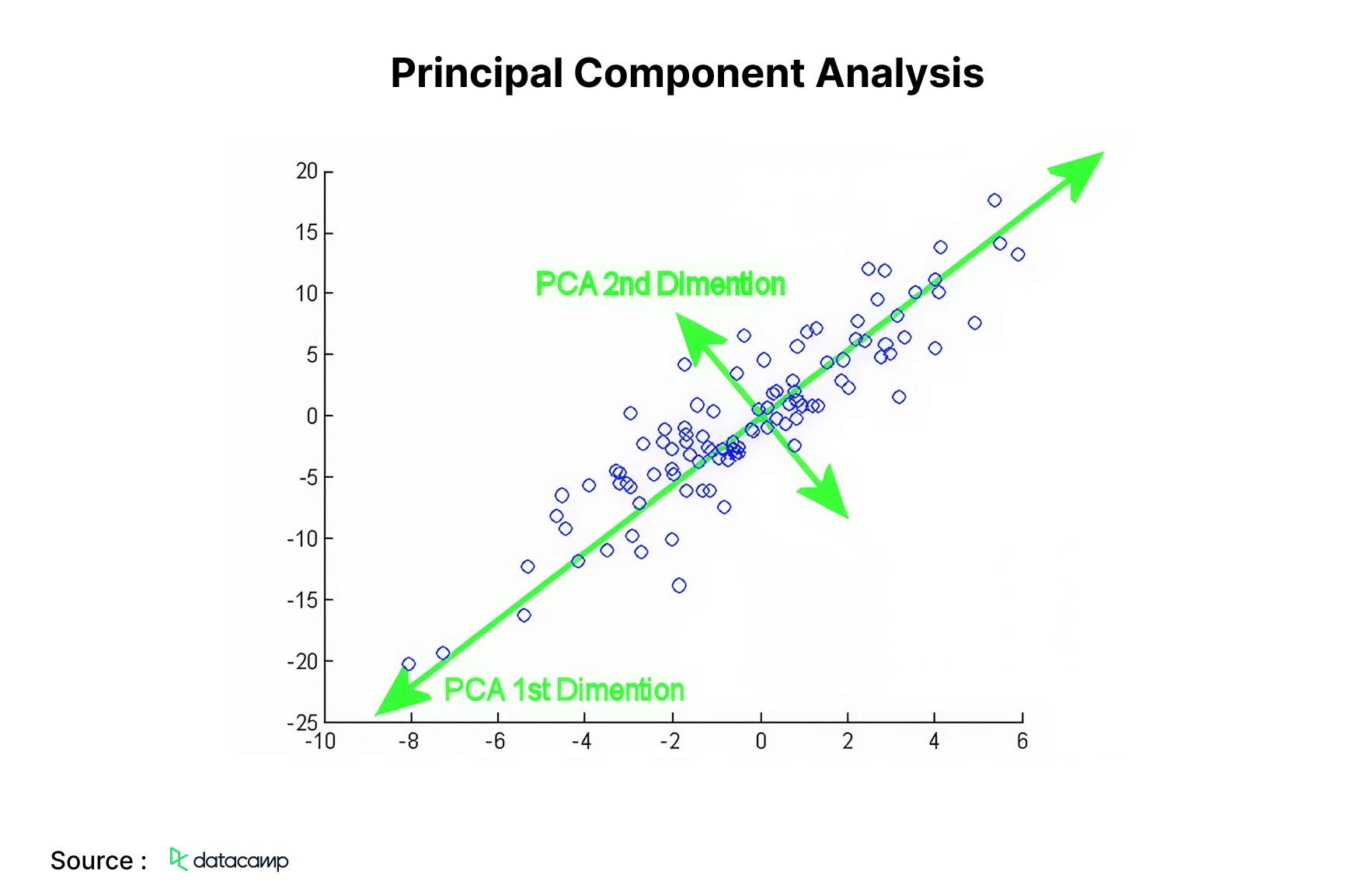
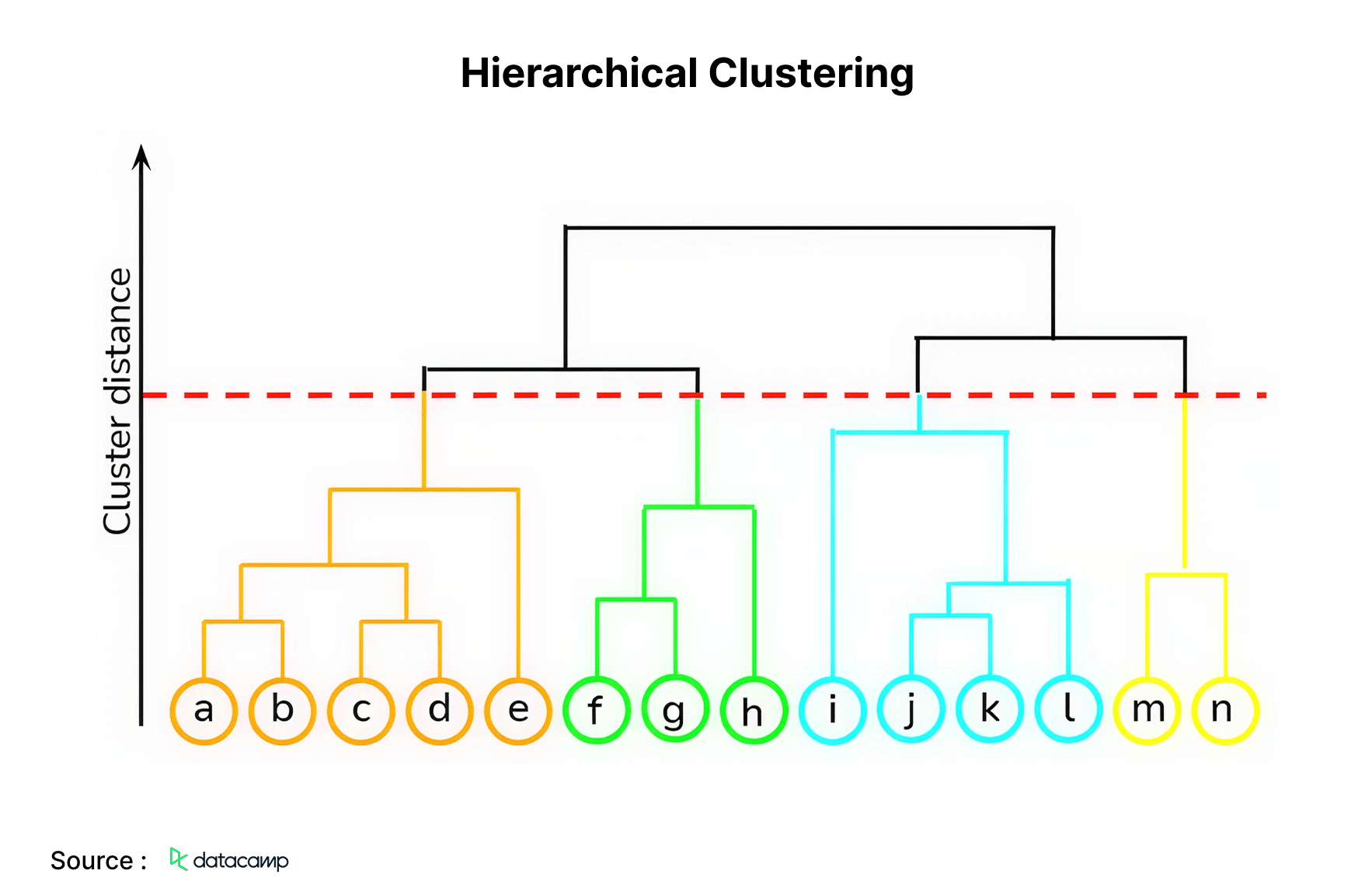
8. Hierarchical Clustering
This is a bottom-up methodology in which each data point is regarded as an individual cluster, thereafter merging the two nearest clusters repeatedly. Its primary benefit over K-means clustering is the fact that it does not necessitate the user to determine the anticipated number of clusters in advance. It is utilized in document clustering to determine similarity.
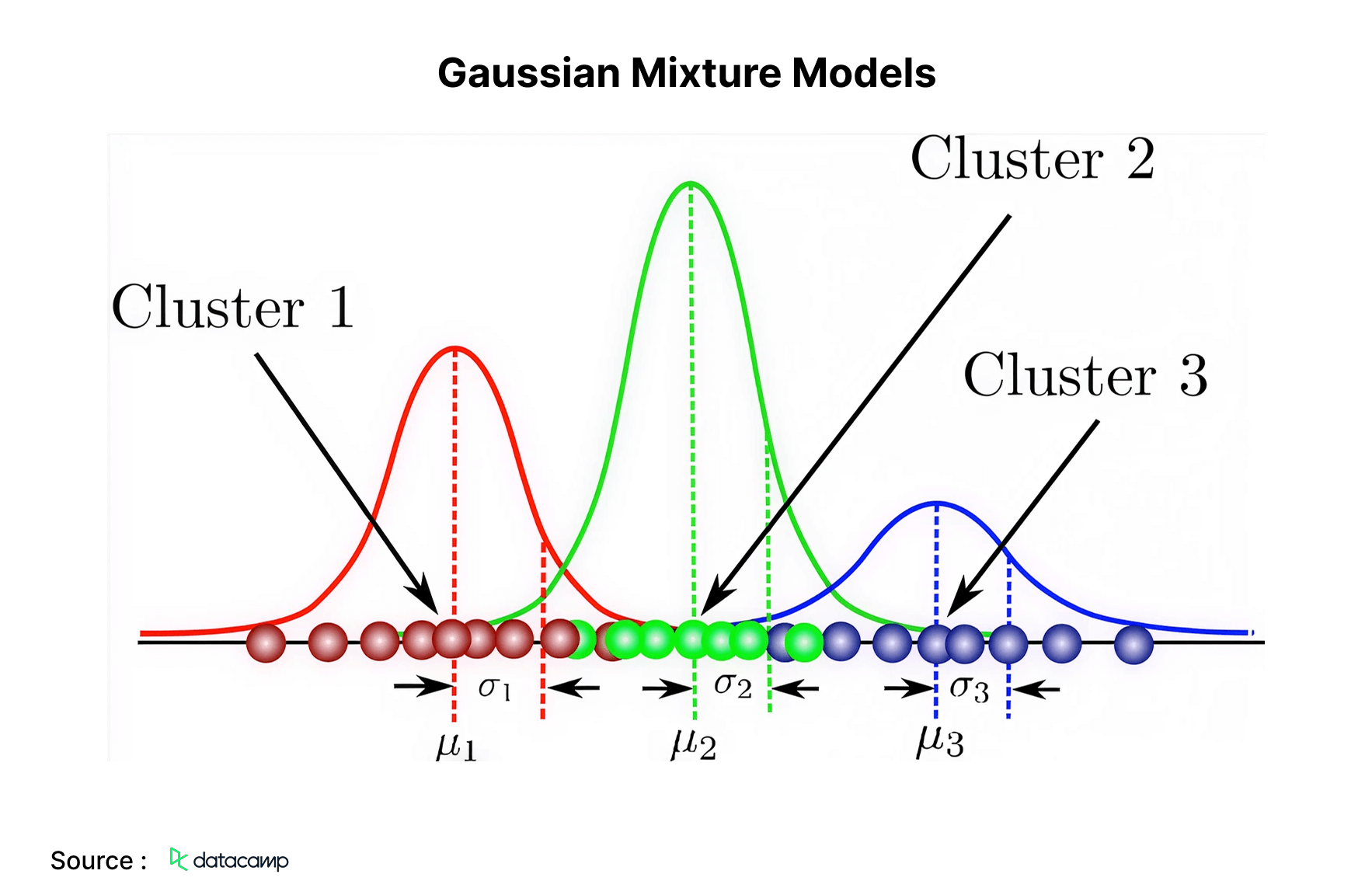
9. Gaussian Mixture Models
Second last on the list of top machine learning algorithms is a probabilistic model for representing evenly distributed clusters within a dataset. It diverges from conventional clustering algorithms by estimating the likelihood of an observation’s association with a certain cluster and then inferring details about its sub-population.
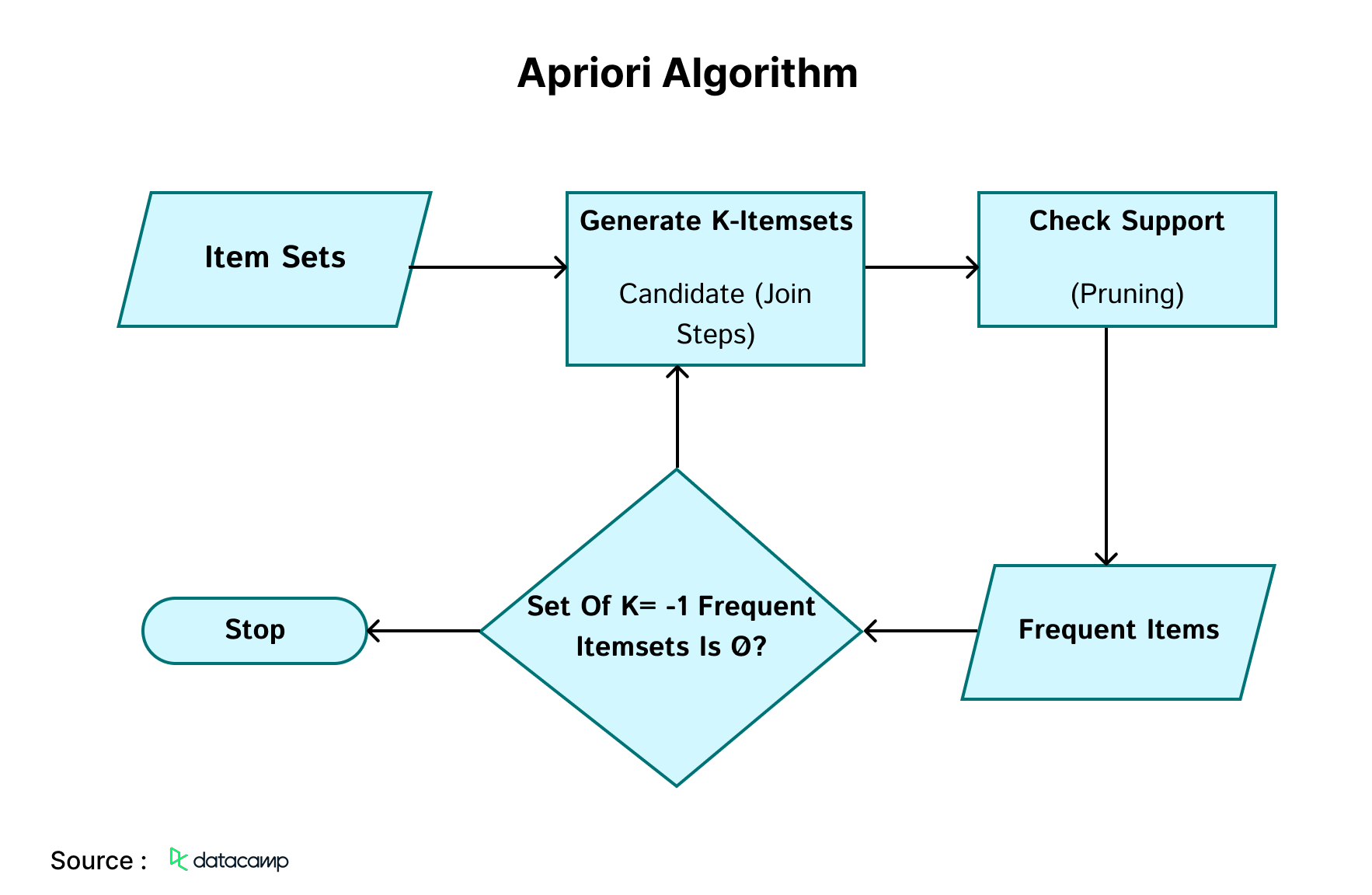
10. Apriori Algorithm
A rule-based methodology that discovers the most prevalent itemsets within a specified dataset, utilizing prior knowledge of the characteristics of frequent itemsets. Market basket analysis utilizes this technique to assist giants such as Amazon and Netflix in converting extensive user data into straightforward product suggestion criteria. It examines the correlations among millions of items and reveals interesting principles.
Factors for Selecting a Machine Learning Algorithm
Let us examine the factors to consider while selecting a machine learning algorithm:
- Data Classification
The next step is to ascertain the type of data at your disposal. Labeled datasets or ones with specified outputs can be assigned to supervised techniques. Conversely, unsupervised methods are necessary to identify concealed structures in unlabeled data. In contexts where learning occurs via interactions, reinforcement learning appears to be a viable option.
- The intricacy of the Issue
Subsequently, assess the intricacy of the issue you are attempting to resolve. In less difficult problems, simpler algorithms suffice. However, when addressing a more difficult topic with intricate linkages, it may be prudent to employ sophisticated methodologies, such as neural networks or ensemble procedures. Be ready for additional work and adjustments.
- Computational Resources
Another significant impact is the computational resources available to you. Certain algorithms, such as deep learning models, can be resource-demanding and need robust hardware. Simple methods such as logistic regression or k-nearest neighbors can yield satisfactory outcomes without excessively taxing your system when operating with constrained resources.
- Interpretability vs Accuracy
Ultimately, consider if you want a comprehensible algorithm or one that emphasizes precision, even if it operates as a black box. Decision trees and linear regression are typically more interpretable, rendering them effective for stakeholder communication. Conversely, more intricate models such as neural networks may yield more accuracy but might be more challenging to explain.

The Bottom Line
Future technology is being changed by machine learning, which is increasing the intelligence and effectiveness of systems in every industry. Deep learning and reinforcement learning are two of the notable advancements driving innovation highlighted in the Top 10 Machine Learning Algorithms of 2025. As AI is continuously integrated into businesses, it is essential to comprehend these algorithms to stay competitive in a more data-driven market.
SoluLab, as a machine learning development company, helps businesses use machine learning to solve complex problems and spur expansion. Sight Machine, a well-known AI-powered company in digital manufacturing, is our most recent initiative. Through our collaboration, they were able to expand their operations, improve industrial processes, and boost efficiency by using generative AI and machine learning technologies. Our team has the expertise to make your idea a reality, whether you’re looking for automation, unique AI solutions, or predictive analytics.
Do you want to remain on top of the AI revolution? Let’s talk about how your company can be transformed by machine learning. Get a free consultation with SoluLab right now to discuss your options!
FAQs
1. Which machine-learning algorithms are most frequently utilized in 2025?
In 2025, prevalent machine learning methods include transformer-based deep learning models, reinforcement learning, federated learning, decision trees, and support vector machines (SVMs). These algorithms facilitate applications in AI-driven automation, natural language processing, and data analytics.
2. In what ways do enterprises get advantages from employing machine learning algorithms?
Machine learning enables enterprises to automate processes, refine decision-making, identify patterns in data, and augment efficiency. Organizations utilize machine learning algorithms for predictive analytics, fraud detection, recommendation systems, and AI-driven automation, resulting in cost reductions and enhanced productivity.
3. Which industries will have the most significant influence from machine learning in 2025?
Industries such as healthcare, banking, e-commerce, cybersecurity, and manufacturing are seeing substantial shifts due to the use of machine learning. Businesses employ machine learning for tailored client experiences, fraud mitigation, predictive maintenance, and automated decision-making, rendering AI a crucial component of contemporary operations.
4. In what ways can enterprises effectively apply machine learning?
For effective machine learning integration, enterprises must establish explicit objectives, select appropriate algorithms, guarantee high-quality data, and engage with AI development specialists. A well-structured AI strategy and the utilization of cloud-based machine learning technologies may expedite processes and enhance results.
5. In what ways may SoluLab assist enterprises in utilizing machine learning?
SoluLab specializes in creating AI-driven solutions customized for corporate requirements. Our proficiency encompasses predictive modeling, automation, generative AI, and bespoke AI applications. Our staff is prepared to assist you in developing intelligent chatbots, optimizing workflows, or integrating AI-driven data. Reach out to us today to investigate the opportunities!