
The blog post provides a comprehensive guide to building private Large Language Models (LLMs) while preserving user privacy in the evolving landscape of AI and language models. It emphasizes the importance of privacy in LLMs due to the processing of vast amounts of sensitive data during training and deployment. Various types of privacy-preserving techniques are discussed, including Differential Privacy, Federated Learning, Secure Multi-Party Computation (SMPC), and Homomorphic Encryption. Each technique offers unique advantages and considerations for building private LLMs. Additionally, strategies for implementing privacy-preserving LLMs are presented, such as Data Minimization, Data Anonymization, and Regular Security Audits. These strategies aim to further enhance the privacy of LLMs by reducing data exposure, removing personally identifiable information, and ensuring compliance with privacy regulations. The blog concludes by highlighting the crucial role of privacy-preserving LLMs in fostering trust, maintaining data security, and enabling the ethical use of AI technology. By employing the techniques and strategies discussed, developers can create LLMs and explore how to build an LLM from scratch that safeguard user privacy while unlocking the full potential of natural language processing. This will contribute to a responsible and secure future for AI and language technology.
Understanding Private Large Language Models
Let’s dive into the basics of Private Large Language Models (LLMs) and why they’re so important for keeping your data safe. We’ll explore how private models are different from regular models and how they put your privacy first.
Definition of Private LLMs
Private Language Models (LLMs) address privacy concerns in advanced language models like GPT-3 and BERT. These models can generate human-like text and perform various language tasks, but they risk compromising sensitive user information. Private LLMs proactively protect user data through robust mechanisms and safeguards, employing techniques like encryption, differential privacy, and federated learning. As LLMs power online services like chatbots, virtual assistants, and content generation platforms, safeguarding user data becomes crucial for trust and security. Private LLMs play a vital role in preserving user privacy through data protection, differential privacy, federated learning, and access control. They empower individuals to use language technologies while maintaining control over their data, fostering trust and responsible innovation in natural language processing. Adopting privacy-centric approaches is essential to safeguard user data and uphold ethical standards in the digital age as the demand for LLMs grows. If you’re interested, consider exploring how to make your own LLM from scratch to create customized solutions that prioritize user privacy and data security.
Types of Large Language Models
The market for language models (LLMs) is diverse and continuously evolving, with new models frequently emerging. However, not all LLMs prioritize user privacy. This article discusses the different types of LLMs available, focusing on their privacy features, to help readers make informed decisions about which models to use. For those interested in a deeper understanding of how to build a LLM from scratch, it is essential to explore both the technical aspects and privacy considerations involved.
Popular LLMs like GPT and BERT, GPT developed by OpenAI and Google AI respectively, lack a strong focus on user privacy. They have been known to collect and store user data without consent. In contrast, privacy-focused LLMs like Themis, Meena, and PaLM 2 utilize decentralized architectures and encrypt user data. These models offer enhanced privacy protection. When selecting an LLM, consider your privacy needs and choose a model that aligns with your preferences.
How to Build a Private LLM
Swoop into the adventure of creating your own Private Language Model (LLM), with expert tips and tricks along the way. Discover the steps you need to take and what to think about when building a language model that keeps your data private without sacrificing performance.
Foundations of Privacy in LLMs
Building a private LLM necessitates a meticulous approach to privacy. Privacy goals should be set, encompassing data handling aspects and user expectations. Understanding data usage implications is crucial, including analyzing data types, purposes, and risks. Ethical standards like transparency and obtaining explicit consent are paramount. Prioritizing user confidentiality involves encryption, access controls, and regular audits. By establishing a solid privacy foundation, private LLMs can provide accurate results while respecting user rights, and fostering trust and confidence in their adoption and use.
Building Blocks of Privacy-Preserving LLMs
Building a private LLM involves robust encryption and secure data handling techniques to ensure privacy and security. Homomorphic encryption allows computations on encrypted data, while federated learning keeps training data decentralized. Differential privacy adds noise to prevent individual identification. Additional considerations include access control, data minimization, regular security audits, and an incident response plan. These measures help maintain user trust, protect sensitive data, and leverage the power of machine learning responsibly.
Read Also: Applications of Natural Language Processing
Private LLM Models in Action
Check out how Private LLMs are used in the real world! We’ll show you some cool examples of how these confidential language models keep your data safe and private.
Real-World Applications:
Private Language Large Models (LLMs) have significant applications that extend beyond traditional boundaries, transforming industries like healthcare and finance while preserving data privacy.
Healthcare:
- Privacy-preserving LLMs enable the development of HIPAA-compliant chatbots that provide empathetic mental health support without compromising privacy.
- LLMs can analyze medical data to aid in diagnosis, treatment planning, and drug discovery while maintaining confidentiality.
Finance:
- LLMs play a crucial role in securing financial data by encrypting messages and transactions and enhancing the security of online banking and financial trading platforms.
- They assist in fraud detection and prevention by analyzing large amounts of financial data and flagging suspicious patterns in real-time.
The applications of private LLMs extend to other domains:
Government and public services:
LLMs can process sensitive government data while maintaining citizen privacy, enabling efficient services like digital identity verification and secure voting.
Education:
LLMs can analyze student data to personalize learning experiences, identify areas of improvement, and tailor educational content while safeguarding student privacy.
Legal services:
LLMs can assist legal professionals in reviewing and analyzing vast amounts of legal documents, extracting relevant information, and identifying legal issues, improving efficiency and accuracy.
Private LLMs have the potential to revolutionize various industries by preserving data privacy and creating new possibilities for personalized and trustworthy services that empower individuals and organizations to harness the power of AI responsibly.

Case Studies:
The analysis of case studies offers valuable insights into the successful implementations of Large vision models. A notable example is the deployment of a private LLMin healthcare. This application showcases how LMs can aid in accurate and efficient diagnosis without compromising patient confidentiality. The private LLM leverages specialized knowledge to analyze patient data, enabling healthcare providers to make informed decisions more quickly. Additionally, it acts as a decision-support tool, offering insights based on the latest research. The implementation in a private setting ensures the security and confidentiality of patient data. This case study highlights the tangible advantages of LMs, emphasizing their potential to revolutionize industries and improve daily lives. For those interested in diving deeper into the field, understanding how to make your own LLM from scratchcan offer valuable insights into building customized solutions tailored to specific needs and maintaining high standards of data security.
Challenges and Considerations
Getting through the tough parts of making private LLMs is no joke. Think about how well the model works, how to keep data safe, and ethical issues. Getting the whole picture of how hard it is to do this will help a lot.
Ethical Challenges:
The development of private LLMs poses ethical challenges that require careful consideration. Striking the balance between fostering innovation and safeguarding user privacy is crucial. Key ethical considerations include:
- Transparent Data Usage Policies: Ensuring clarity about data collection, usage, and accessibility builds trust and empowers users.
- Informed Consent: Providing comprehensive information about implications, risks, and benefits enables voluntary and informed decisions.
- Fair Model Deployment: Ensuring fairness involves addressing biases, preventing discrimination, and promoting responsible AI use.
- Addressing Bias and Fairness: Minimizing bias involves examining training data, employing bias mitigation techniques, and continuous monitoring.
- Security and Data Protection: Implementing robust security measures safeguards user data privacy and confidentiality.
- Accountability and Governance: Establishing clear lines of accountability, implementing policies, and conducting audits ensures ethical compliance.
By addressing these considerations, organizations and developers can navigate private LLM development responsibly, fostering innovation while upholding user privacy and trust.
Legal and Regulatory Compliance:
Language models (LLMs) must navigate the legal landscape responsibly, and developers must stay updated on data privacy regulations. The General Data Protection Regulation (GDPR) is a significant international framework that LLMs should comply with to protect individual privacy rights. For those interested in how to build a LLM from scratch, understanding GDPR compliance is crucial.
GDPR imposes strict obligations on organizations handling personal data, including LLMs, and mandates transparent data practices, individual control, and robust security measures. Key considerations for GDPR compliance include obtaining explicit user consent for data collection, implementing strong data security measures, respecting data subject rights, promptly notifying affected parties in case of data breaches, and ensuring adequate safeguards for cross-border data transfers. Adhering to GDPR demonstrates a commitment to user privacy, mitigates legal risks, and fosters trust.
Future Trends in Private LLMs
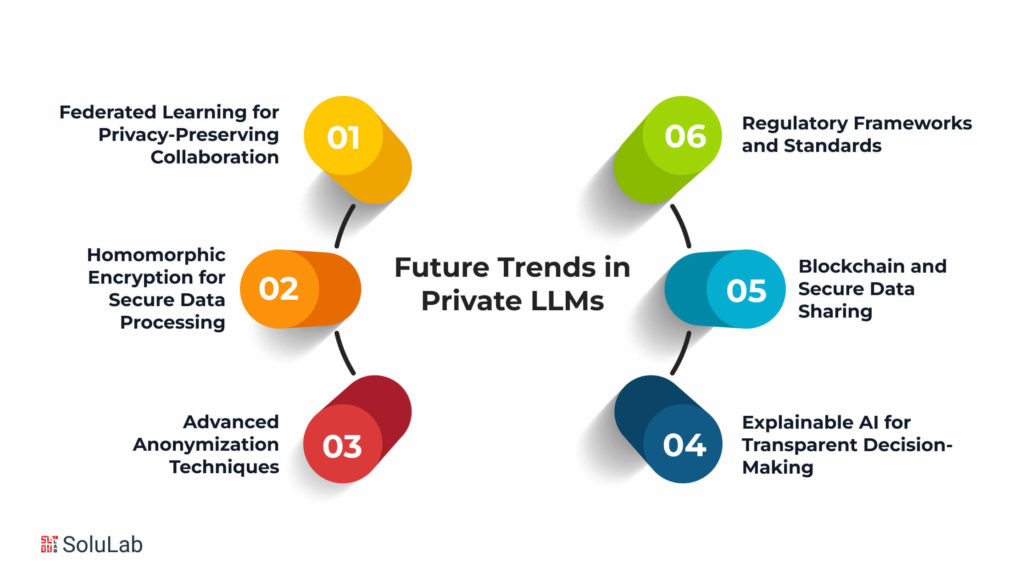
Let’s take a sneak peek into the rad future of language model development. We’ll dive into the cool new trends in Private LLMs (language models). You’ll see how these models are gonna level up, embracing new tech and totally changing the game of confidential language processing. Buckle up for an epic journey!
The future of private LLMs holds exciting prospects for advancements in privacy technologies. Ongoing research in various fields will contribute to enhanced data protection and user privacy in the utilization of LLMs. Here are some key areas to watch:
- Federated Learning for Privacy-Preserving Collaboration: Federated learning enables multiple parties to collaboratively train a model without sharing their individual data. This distributed approach preserves data privacy while allowing for the development of vital LLMs.
- Homomorphic Encryption for Secure Data Processing: Homomorphic encryption techniques allow computations to be performed on encrypted data, ensuring that sensitive information remains protected throughout the modeling process. This advancement will empower LLMs to analyze and generate insights from encrypted datasets.
- Advanced Anonymization Techniques: Ongoing research in anonymization methods, such as differential privacy and secure multi-party computation, will further safeguard individual identities and sensitive information when using LLMs. These techniques will minimize the risk of re-identification and protect data privacy.
- Explainable AI for Transparent Decision-Making: The integration of explainable AI (XAI) with private LLMs will enhance transparency and trust in their decision-making processes. XAI techniques will enable users to understand the underlying rationale behind LLM outputs, ensuring accountability and responsible AI practices.
- Blockchain and Secure Data Sharing: Leveraging blockchain technology can provide a secure and transparent framework for sharing data among multiple parties while maintaining privacy. Blockchain-based solutions can offer tamper-proof records of data transactions, enhancing trust and accountability in the use of LLMs.
- Regulatory Frameworks and Standards: As private LLMs continue to evolve, the development of regulatory frameworks and standards will become crucial for ensuring responsible and ethical use. These frameworks will define guidelines for data collection, storage, and processing, aiming to protect user privacy and prevent potential abuses.
By exploring these emerging trends and investing in privacy-enhancing technologies, the future of private LLMs promises to strike a balance between powerful language capabilities and robust data protection, fostering trust and enabling the responsible deployment of LLMs in various industries and applications.
Check Blog Post: What is Retrieval Augmented Generation?
Predictions for the Future:
The future of private LLMs holds immense promise, driven by growing recognition of privacy concerns and the need for more stringent privacy standards. Innovations in secure AI development will usher in a new era of responsible and privacy-centric language models. Here are some key aspects to anticipate:
- Enhanced Privacy Protections: As awareness of privacy risks increases, there will be a greater emphasis on building privacy-preserving LLMs. Techniques such as differential privacy, federated learning, and secure multi-party computation will be employed to protect sensitive information and ensure compliance with privacy regulations.
- Transparent and Explainable Models: Private LLMs will prioritize transparency and explainability to build trust among users. Developers will focus on creating models that can explain their reasoning and decision-making processes, allowing users to understand how their data is being used and to make informed choices about their privacy.
- Collaborative Development: The development of private LLMs will increasingly involve collaboration between researchers, industry experts, and policymakers. This will foster the sharing of best practices, the establishment of industry standards, and the creation of open-source tools and frameworks for privacy-preserving AI.
- Regulation and Compliance: Governments and regulatory bodies will play a more active role in shaping the landscape of private LLMs. Regulations aimed at protecting individual privacy and ensuring responsible AI development will be introduced and enforced. Companies that develop and deploy private LLMs will need to demonstrate compliance with these regulations to operate legally and ethically.
- Integration with Privacy-Enhancing Technologies: Private LLMs will be integrated with other privacy-enhancing technologies to create a comprehensive approach to data protection. This may include technologies such as encryption, access control, and data minimization, which will work in conjunction with the inherent privacy features of the LLMs to provide multiple layers of protection.
By embracing these advancements and prioritizing privacy, private LLMs can become powerful tools that empower individuals while respecting their fundamental right to data privacy. The future of private LLMs is one where privacy is not an afterthought but an integral part of their design and operation.

Conclusion
The development of private Large Language Models (LLMs) is essential for safeguarding user data in today’s digital era. SoluLab, an AI Consulting Company, stands at the forefront of this journey, prioritizing confidentiality, security, and responsible data usage. Their team of skilled AI developers creates state-of-the-art language models aligned with the principles of privacy. SoluLab’s private LLM models incorporate techniques such as homomorphic encryption and federated learning, ensuring technological advancement and ethical robustness. Beyond developing private LLM models, SoluLab offers comprehensive solutions, from conceptualization to implementation across diverse industries. Their proficiency extends to various types of LLMs, including GPT and BERT, tailoring them to meet specific privacy requirements. By championing the development of private LLM models and embracing ethical AI practices, SoluLab sets the stage for a future where innovation and privacy coexist seamlessly.
FAQs
Bhavya is driving growth through data-backed demand generation for AI and Web3 solutions. With 9+ years in digital marketing, he has spearheaded initiatives that led to a 40% increase in qualified inbound leads. Bhavya shares insights on marketing ROI and scaling a digital presence via AI workflows. He is open to connecting with startups and enterprise teams to help them overcome their challenges.


