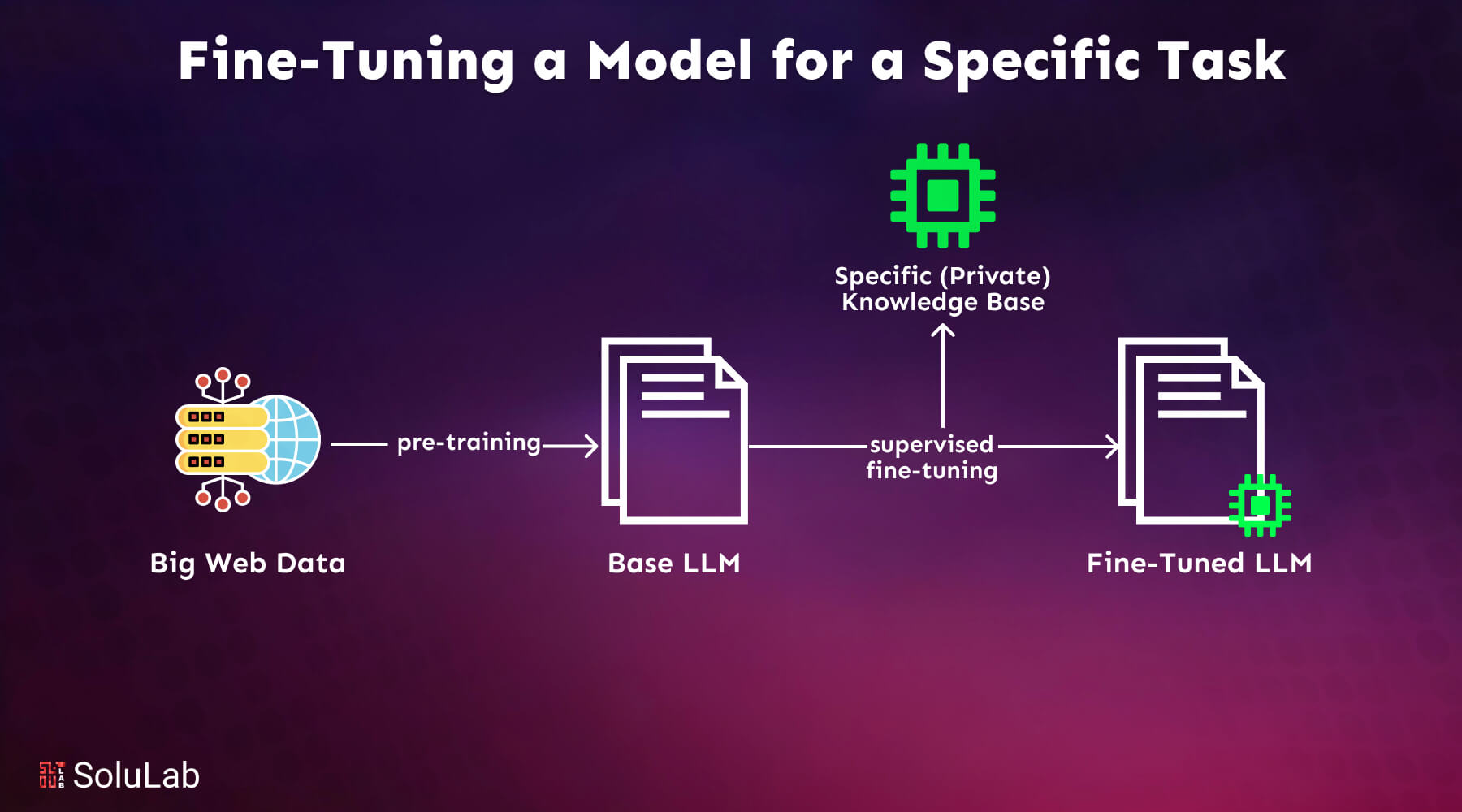
Large language models (LLMs) have natural language processing with their advanced capabilities, handling tasks like text generation, translation, summarization, and question-answering. However, they may not always be suited for specific tasks or industries.
A study on product attribute extraction showed that fine-tuning with as few as 200 samples increased model accuracy from 70% to 88%
Fine-tuning lets users adapt pre-trained LLMs for specialized tasks like blockchain technology. By training a model on a smaller, task-specific dataset, you can boost its performance on that task while keeping its general language knowledge intact. For example, a Google study showed that fine-tuning a pre-trained LLM for sentiment analysis improved its accuracy by 10%.
In this blog, we’ll explore how fine-tuning LLMs can enhance performance, lower training costs, and deliver more accurate, context-specific results. We’ll also cover different fine-tuning techniques and applications to highlight their importance in LLM-powered solutions.
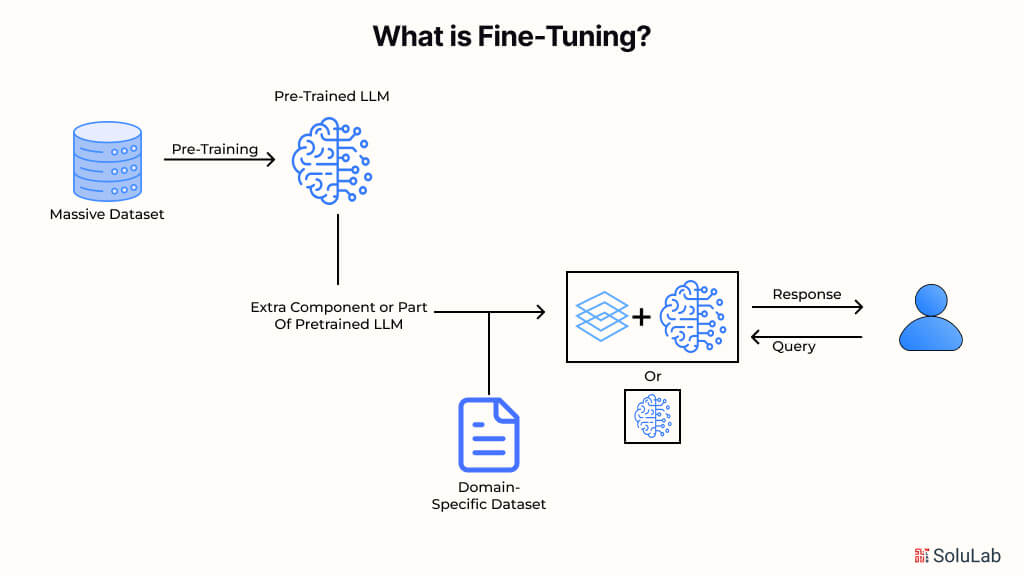
What is Fine-Tuning, and Why do you Need it?
When you fine-tune a model that has already been trained, you teach it more on a dataset that is specific to your topic. These days, most LLM models work well in general, but they don’t do well with certain task-oriented situations. There are many benefits to the fine-tuning process, such as lower computing costs and the ability to use cutting-edge models without having to build a new one from scratch.
Transformers give you access to a huge library of models that have already been trained to do different jobs. With the integration of blockchain trade finance applications, these models become even more powerful. A very important step in making these models better at doing certain jobs, like analyzing sentiment, answering questions, or summarizing documents, is to fine-tune them.
Fine-tuning changes the model so that it works better for certain jobs. This makes it more useful and adaptable in the real world. To make an existing model fit a certain job or domain, this step is necessary. Whether or not to fine-tune is determined by your aims, which will most likely alter based on the domain or job at hand.
During fine-tuning, the model is exposed to task-specific examples, allowing it to grasp the nuances of the subject. This process enhances the model’s ability to transition from a general-purpose tool to a specialized resource and show its full potential for targeted applications. You may need to fine-tune LLMs for several key reasons:
a. Customization for Specific Domains
Different domains or tasks involve unique language usage, terminology, and nuances. Fine-tuning a pre-trained LLM allows it to understand these specific characteristics and produce content tailored to your area.
This approach ensures the model provides accurate and relevant responses aligned with your requirements. Whether working with legal documents, medical reports, business analytics, or internal company data, fine-tuning enables the model to deliver domain-specific insights.
b. Ensuring Data Compliance
Fields like blockchain use cases, healthcare, banking, and law are governed by strict rules regarding the use and handling of sensitive information. Fine-tuning an LLM on private or controlled data helps organizations ensure compliance with these regulations.
This approach develops models based on in-house or industry-specific datasets, lowering the danger of sensitive information being exposed to external systems.
c. Overcoming Limited Labeled Data
Obtaining large amounts of labeled data for specific tasks or domains can be challenging and costly. Fine-tuning allows businesses to maximize the utility of their existing labeled datasets by adapting a pre-trained LLM to the data.
This method improves the model’s performance and effectiveness, even in scenarios where labeled data is scarce. By fine-tuning with limited data, organizations can achieve significant enhancements in the model’s accuracy and relevance for the desired task or domain.

Primary Fine-Tuning Approaches
When you fine-tune a Large Language Model (LLM) for a blockchain consulting company, you adjust its parameters based on the task you aim to accomplish. The extent of these changes depends on the specific job requirements. Generally, there are two main approaches to fine-tuning LLMs: feature extraction and full fine-tuning. Let’s explore each method in detail:
-
Feature Extraction (repurposing)
One of the primary ways to enhance LLMs is through feature extraction, also known as recycling. This approach involves using a pre-trained LLM as a fixed feature extractor. Since the model has already been trained on an extensive dataset, it has learned significant language representations that can be leveraged for specific tasks.
In this method, only the last few layers of the model are trained on task-specific data, while the rest of the model remains unchanged. The pre-trained model’s rich representations are adapted to suit the new task. This technique is efficient and cost-effective, making it a quick way to improve LLMs for specific purposes.
-
Full Fine-Tuning
Full fine-tuning is another important way to tailor LLMs to specific aims. Unlike feature extraction, this strategy requires training the entire model using task-specific data. Every layer of the model is adjusted during the training process.
This method is most effective when the task-specific dataset is large and notably distinct from the pre-training dataset. By allowing the entire model to learn from task-specific data, full fine-tuning enables the model to become deeply tailored to the new task, potentially resulting in superior performance. However, it’s essential to note that full fine-tuning requires more time and computational resources compared to feature extraction.
Fine-Tuning Process and Best Practices
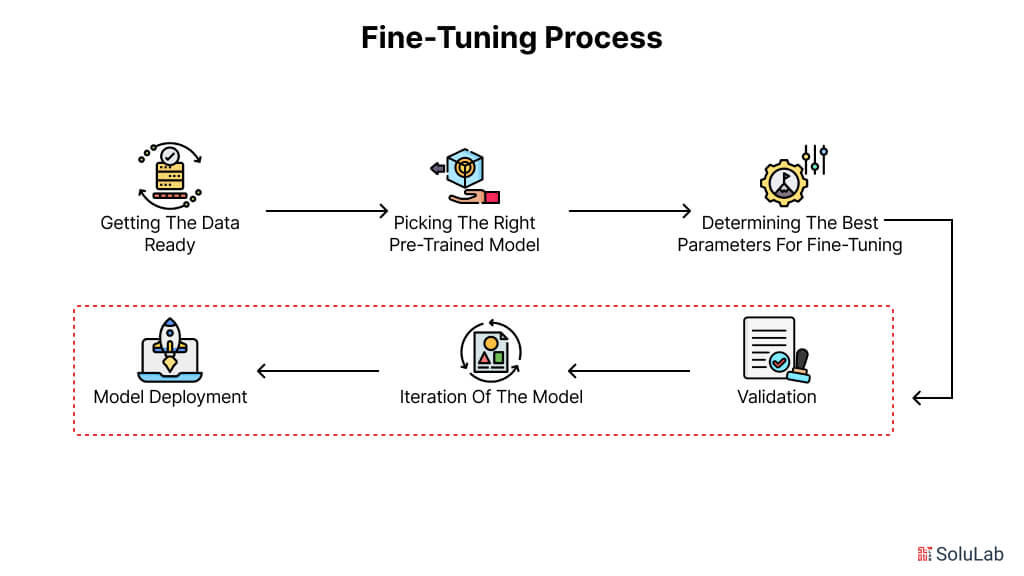
To get the best results, fine-tuning a model that has already been trained for your use case or application requires a clear process. These are some of the best practices:
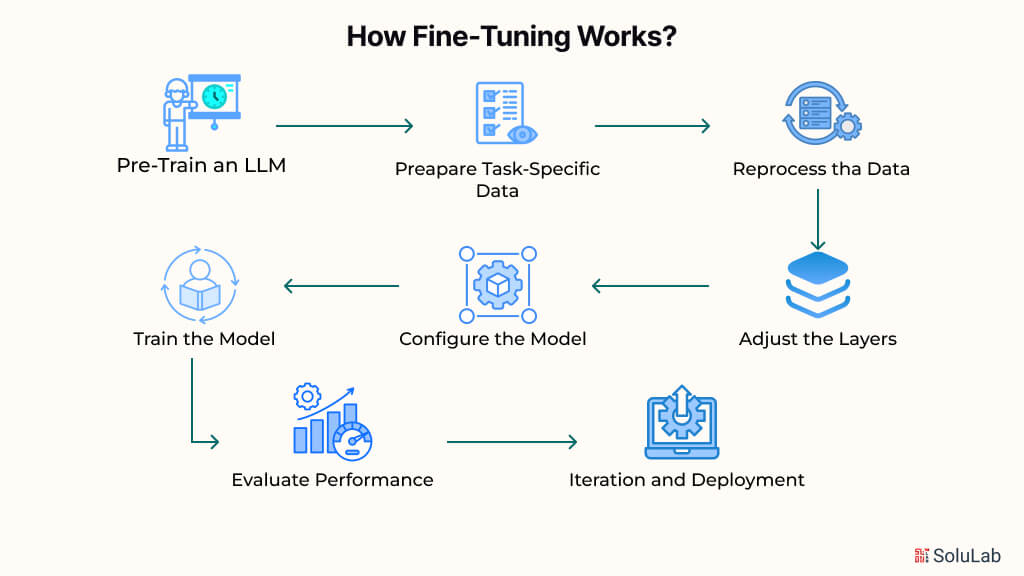
1. Getting the Data Ready
Data preparation involves selecting and preprocessing the dataset to ensure it is useful and of good quality for the task at hand. This may include activities such as cleaning the data, addressing missing values, and formatting the text to meet the model’s input requirements.
Data augmentation methods can also be applied to expand the training dataset and improve the model’s reliability. Properly preparing the data is crucial for fine-tuning, as it directly impacts the model’s ability to learn and generalize effectively, resulting in better performance and accuracy when generating task-specific outputs.
2. Picking the Right Pre-trained Model
Choosing a pre-trained model that meets the requirements of the target task or area is critical. To ensure the pre-trained model integrates seamlessly into the fine-tuning workflow, it is important to understand its architecture, input/output specifications, and layer configurations.
When making this choice, factors such as model size, training data, and performance on related tasks should be considered. Selecting a pre-trained model that closely matches the target task’s characteristics can accelerate the fine-tuning process and enhance the model’s adaptability and utility for the intended application.
3. Determining the Best Parameters for Fine-tuning
Configuring fine-tuning parameters is critical for achieving optimal results during the process. Parameters such as the learning rate, number of training epochs, and batch size significantly influence how the model adapts to task-specific data. Overfitting can often be mitigated by freezing certain layers (usually earlier ones) while training the final layers.
By freezing the initial layers, the model retains the general knowledge acquired during pre-training, allowing the final layers to focus on adapting to the new task. This approach balances leveraging prior knowledge and effectively learning task-specific features.
4. Validation
Validation involves testing how well the fine-tuned model performs using a validation set. Metrics such as accuracy, loss, precision, and recall can be used to assess the model’s performance and generalization capability.
By analyzing these metrics, one can gauge how effectively the fine-tuned model handles task-specific data and identify areas for improvement. This validation process helps refine fine-tuning parameters and model architecture, resulting in an optimized model that delivers accurate results for the intended purpose.
5. Iteration of the Model
Model iteration allows adjustments to be made based on test results. After evaluating the model’s performance, fine-tuning parameters such as the learning rate, batch size, or degree of layer freezing can be modified to enhance performance.
Additionally, exploring approaches like implementing regularization techniques or altering the model’s architecture can further improve its performance over time. This iterative process enables engineers to fine-tune the model systematically, making incremental enhancements until it achieves the desired level of performance.
6. Model Deployment
Model deployment, which involves transitioning the fine-tuned model into the appropriate environment, bridges the gap between development and real-world application. This process includes considerations such as the hardware and software requirements of the deployment environment and the model’s integration with other systems or applications.
Ensuring smooth and reliable deployment also requires addressing factors like scalability, real-time performance, and security measures. Successfully deploying the model in the appropriate environment allows its enhanced capabilities to be utilized effectively in solving real-world challenges.
Fine-Tuning Applications
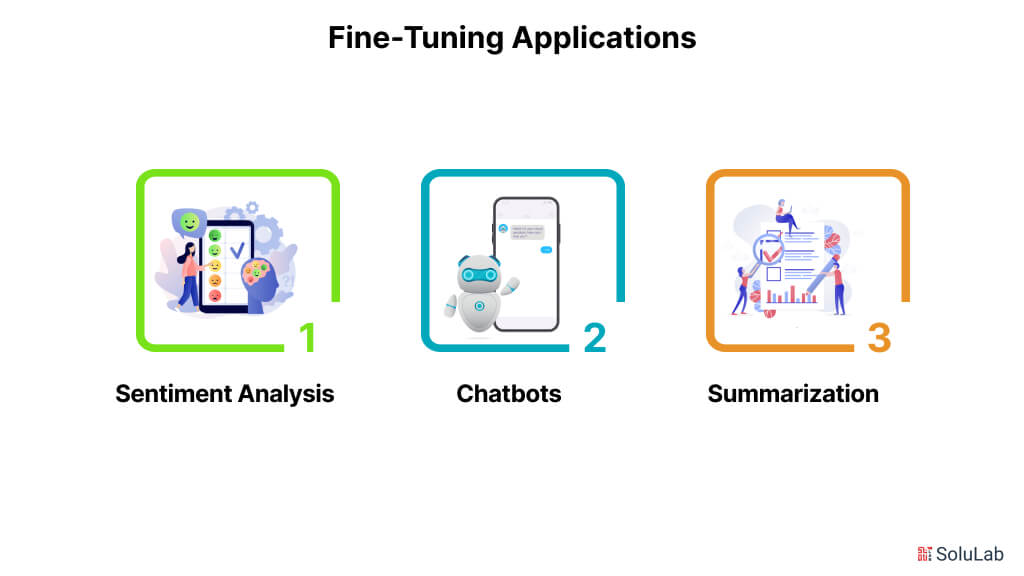
You can use blockchain platforms for the power of large models for specific tasks without having to train a model from scratch by fine-tuning models that have already been trained. Some common situations where fine-tuning LLMs can be very helpful are listed below:
1. Sentiment Analysis: Fine-tuning models on specific company data, unique domains, or particular tasks helps ensure accurate analysis and understanding of emotions in textual content. This allows businesses to derive valuable insights from product reviews, social media posts, and customer feedback. These insights can aid in decision-making, developing marketing strategies, and creating new products.
For example, businesses can use sentiment analysis to identify trends, measure customer satisfaction, and uncover areas for growth. Fine-tuned social media models enable businesses to gauge public sentiment about their brand, products, or services, allowing them to manage reputations proactively and engage with customers in a more targeted manner. Overall, fine-tuned large language models are a powerful tool for sentiment analysis, providing businesses with profound insights into customer emotions.
2. Chatbots: Fine-tuning chatbots enables them to have more useful and engaging conversations tailored to specific contexts. This enhances customer interactions and benefits various fields, including customer service, healthcare, e-commerce, and finance. For instance, chatbots can assist users with medical queries by providing detailed and accurate responses, thereby improving patient care and access to medical information.
Fine-tuned chatbots can address product-related questions, recommend items based on user preferences, and streamline transactions. In the finance sector, chatbots can offer personalized financial advice, assist with account management, and respond to customer inquiries accurately and efficiently. Overall, fine-tuning language models for chatbot applications enhances conversational capabilities, making them invaluable across various industries.
3. Summarization: Fine-tuned models can automatically generate concise, useful summaries of lengthy documents, articles, or discussions. This improves information retrieval and knowledge management, especially for professionals who must sift through vast amounts of data to extract critical insights.
Fine-tuned summarization models can condense extensive research papers, enabling scholars to grasp key concepts and outcomes more quickly. In business, these models can shorten lengthy reports, emails, and documents, simplifying decision-making and improving information comprehension. Overall, using fine-tuned language models for summarization makes information more accessible and comprehensible, proving to be a valuable tool across multiple domains.
Fine-tuned models produce the best results across a variety of use cases. This demonstrates the versatility and utility of fine-tuning in enhancing LLMs for solving specific business challenges.
The Different Types of Fine-tuning
Fine-tuning can be handled in a variety of ways, based on the primary focus and specific goals.
1. Supervised Fine-tuning: The most simple and popular fine-tuning method. The model is trained using a labeled dataset relevant to the goal task, such as text categorization or named entity recognition.
For sentiment analysis, we would train our model using a dataset of text samples labeled with their corresponding sentiment.
2. Few-shot Learning: Collecting a large labeled dataset is not always practical. Few-shot learning addresses this by including a few samples (or shots) of the required task at the start of the input prompts. This allows the model to better understand the problem without requiring substantial fine-tuning.
3. Transfer Learning: Although all fine-tuning approaches are a kind of transfer learning, this category is explicitly designed to allow a model to execute a task other than the one it was initially trained on. The fundamental idea is to use the model’s knowledge gathered from a large, general dataset to solve a more specific or related problem.
4. Domain-specific Fine-tuning: This form of fine-tuning aims to train the model to understand and generate content specific to a given domain or industry. The model is fine-tuned using a dataset of text from the target domain to increase its context and understanding of domain-specific tasks.
For example, to create a chatbot for a medical app, the model would be trained on medical records to tailor its language comprehension abilities to the healthcare industry.
Challenges and Limitations
Fine-tuning an LLM for a specific task or set of information is a powerful technique, but it comes with significant downsides.
- Cost and Time: Training large models requires substantial computing power. Smaller teams or those with limited budgets may find these costs prohibitive.
- Brittleness: Fine-tuned models may struggle to adapt to new data without expensive retraining. They can become locked into a “stabilized snapshot” of their training data.
- Expertise Required: Building and maintaining AI systems requires specialized skills and knowledge, which can be hard to acquire.
- Quirky Outputs: Models can sometimes “visualize” unexpected or biased results, or forget previously learned information. Ensuring their accuracy is an ongoing challenge.
In short, while fine-tuning is a powerful process, it requires careful management. Many believe the benefits outweigh the costs.
The Challenges of MLOps and LLMOps
Designing a production LLMOps pipeline ensures a repeatable process. You can run it on cloud.zenml.io.
Deploying a fine-tuned model is just the beginning. To maintain its performance in the real world, you must address various operational challenges in machine learning production:
- Orchestration and Automation: Streamlining deployment and developing robust CI/CD pipelines can be difficult. You must manage the entire lifecycle, from training and deployment to monitoring.
- Infrastructure Complexity: Managing the infrastructure for model deployment is not easy. Challenges include secret management, caching model checkpoints, and optimizing hardware and software configurations for inference.
- Performance and Reliability: Once deployed, your model must consistently perform well. Monitoring throughput, latency, and error rates is crucial, along with having proper versioning methods to manage updates.
- Monitoring and Debugging: When something goes wrong with a deployed model, identifying the issue can be challenging. You need advanced tools to monitor performance, analyze errors, and handle unexpected failures.
- Continuous Improvement: Top blockchain platforms for performance models are never “finished.” They must evolve with new data. Implementing a continuous improvement loop is challenging, especially with the tools available today.
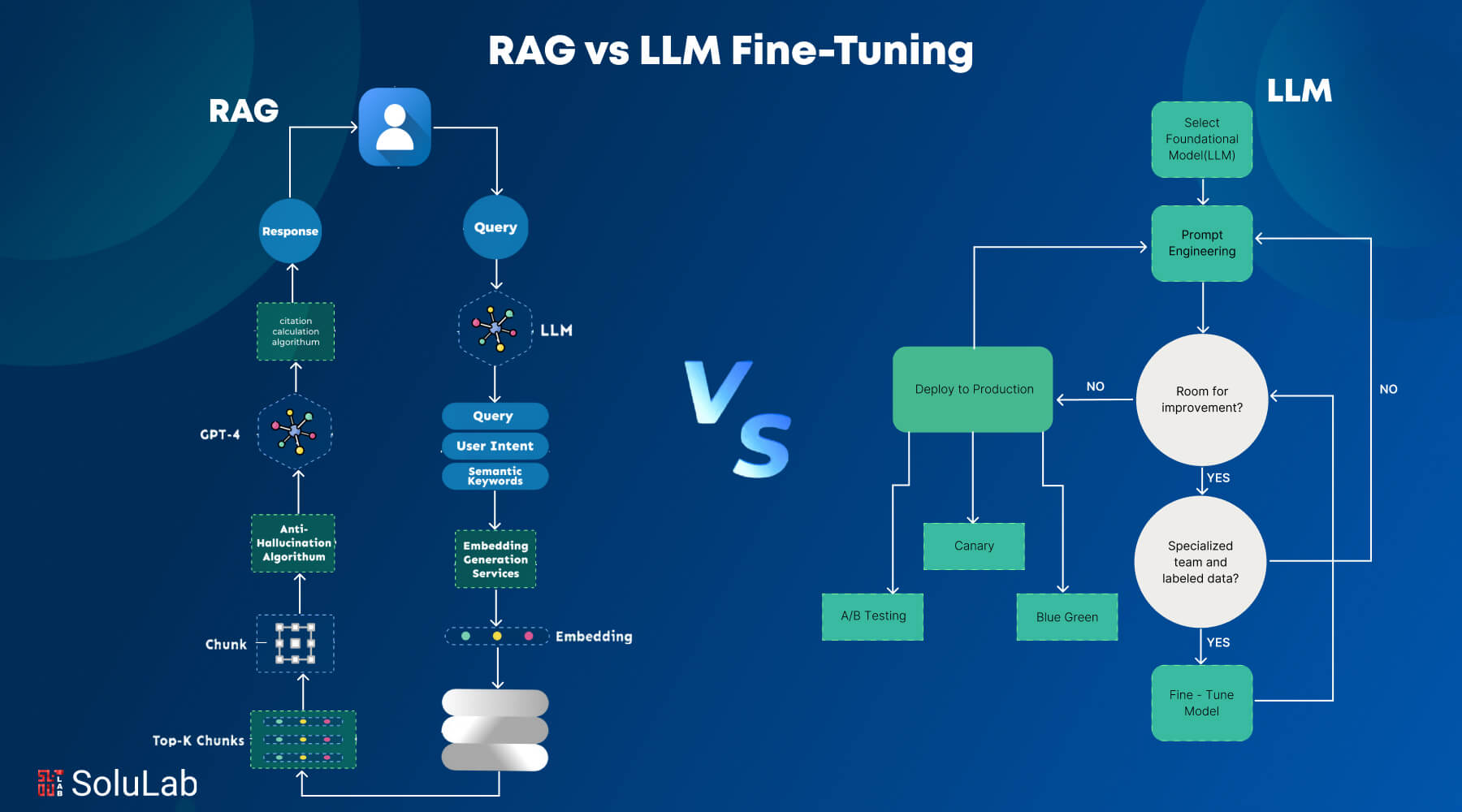
Fine-tuning vs. RAG
AG combines the strengths of retrieval-based and generative models. The retriever component searches a large database or knowledge base for relevant information based on the input query in RAG. A generative model then uses this data to provide a more accurate and contextual answer. Advantages of RAG include:
| Parameter | Fine-Tuning | RAG (Retrieval-Augmented Generation) |
| Definition | Fine-tuning involves adjusting a pre-trained model’s weights using domain-specific data. | RAG (Retrieval-Augmented Generation) combines a language model with an external knowledge retrieval system to generate responses. |
| Objective | To adapt the model for improved performance on a specific task or dataset. | To provide real-time, knowledge-rich responses without modifying the base model. |
| Data Dependency | Requires a large, high-quality labeled dataset relevant to the specific task. | Relies on an external knowledge source or database for retrieval. |
| Knowledge Updates | Requires pre-training or additional fine-tuning to update the model’s knowledge. | Updates are as simple as refreshing or updating the knowledge database. |
| Ethical and Privacy Issues | May inadvertently memorize sensitive data, posing privacy concerns. | Privacy risks depend on the external data source but can be mitigated by controlling the database. |
| Computational Resources | High computational cost due to re-training the model. | Relatively lower computational cost since the base model remains unchanged. |
Fine-tuning vs. RAG factors to consider
When deciding between fine-tuning and RAG, consider the following factors:
- Domain-specific applications: Fine-tuning is typically better for highly specialized models. RAG excels at real-time information retrieval and external knowledge integration.
- Data Availability: Fine-tuning requires a lot of task-specific labeled data, while RAG can use external data when such data is unavailable.
- Resource Constraints: RAG uses databases to complement the generative model, reducing the need for extensive training. Fine-tuning, however, is computationally demanding.

Conclusion
Fine-tuning large language models offers many exciting opportunities for AI applications. Fine-tuning LLMs for specific use cases is becoming more popular among companies wanting to customize pre-trained models for their business needs. It can improve model performance and be a cost-effective way to boost business outcomes. However, successful fine-tuning requires a solid understanding of model architecture, performance benchmarks, and adaptability.
By following the right practices and precautions, you can adapt these models to meet specific needs and their full potential. To continue learning about fine-tuning, I recommend trying DataCamp’s LLM Concepts course, which covers key training methods and the latest research.
Solulab helped NovaPay Nexus build a self-hosted, automated cryptocurrency payment processor, enabling businesses to accept digital currencies without fees or middlemen. The platform allows users to manage multiple stores, create payment apps, and ensure secure transactions with privacy-first features. Solulab, a LLM development company, has a team of experts to solve and assist with business queries. Contact us today!
FAQs
1. Is fine-tuning cost-effective?
Yes, fine-tuning is often more cost-effective than training a model from scratch, as it leverages existing knowledge in pre-trained models.
2. Do I need specialized knowledge to fine-tune a model?
Yes, fine-tuning requires a good understanding of machine learning, model architecture, and the specific task to ensure the model is adapted correctly.
3. What are some examples of fine-tuning?
Customizing a model for specific tasks, like sentiment analysis, product recommendations, or chatbot training, using domain-specific datasets.
4. What hardware requirements for fine-tuning a large language model?
High-performance GPUs or TPUs, large memory (RAM), and fast storage are essential for the efficient fine-tuning of large language models.
5. How to fine-tune a model in language modeling?
Adjust the pre-trained model using task-specific data, optimize parameters, and retrain with a smaller learning rate for specialized applications.