

Retrieval-Augmented Generation (RAG) and LLM fine-tuning are two common methods used to improve how large language models deliver accurate, domain-specific answers.
The main difference between RAG and Fine-Tuning is that RAG uses an LLM to access external knowledge sources, allowing the model to retrieve relevant information in real time before generating a response.
Fine-tuning, on the other hand, trains the model further using specialized datasets, helping it learn patterns, terminology, and behavior specific to a particular industry or task.
In this blog, we will break down the key differences between RAG and LLM fine-tuning, when to use each approach, their advantages, and how businesses can select the right strategy for building reliable AI applications.
Key Takeaways
- The Problem: Many businesses struggle to choose between RAG and LLM fine-tuning for their AI systems. Without the right approach, models can produce outdated information, require high training costs, or fail to use company data effectively.
- The Solution: RAG improves responses by retrieving real-time external knowledge, while fine-tuning trains the model on specialized datasets. Choosing the right method depends on data availability, cost, and how frequently information needs updating.
- How SoluLab Helps: SoluLab, with the help of AI, helps businesses design enterprise AI systems using RAG, fine-tuned LLMs, or hybrid architectures. Our team builds scalable AI solutions that integrate private data, improve accuracy, and deliver reliable AI
What is the difference between RAG and Fine-Tuning?
The difference between RAG and fine-tuning is that RAG helps AI find information from external sources before answering. Fine-tuning trains the AI on special data so it learns better. Simply put, RAG adds knowledge, while fine-tuning improves the AI itself.
Moreover, a comparative study found that RAG systems outperformed fine-tuned models by up to 16% in ROUGE scores and 15% in BLEU scores. Now let’s understand both concepts in detail:
What is Retrieval-Augmented Generation?
Retrieval-Augmented Generation (RAG) is a framework introduced by Meta in 2020, designed to enhance large language models (LLMs) by connecting them to a curated, dynamic database. This connection allows the LLM to generate responses enriched with up-to-date and reliable information, improving its accuracy and contextual reasoning.
Key Components of RAG Development
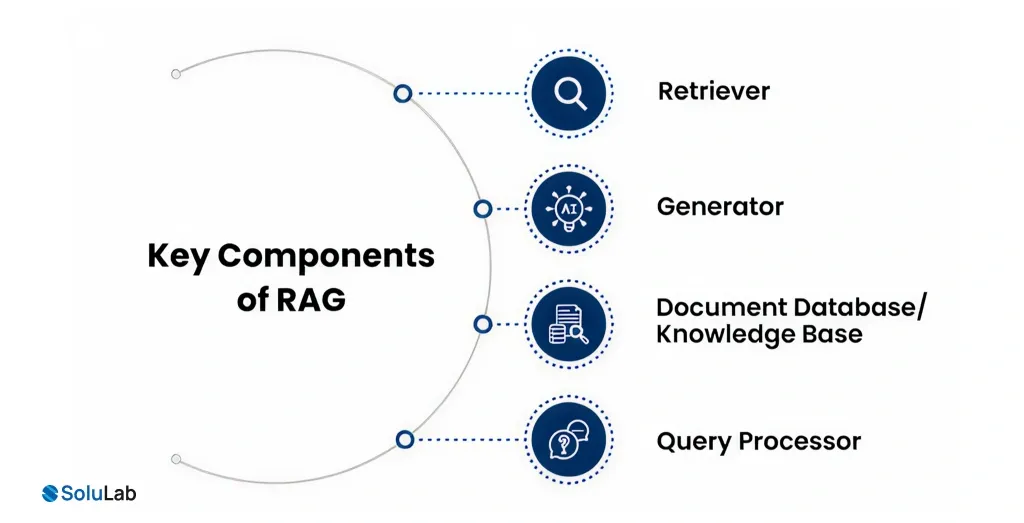
Building a RAG architecture is a multifaceted process that involves integrating various tools and techniques. These include prompt engineering, vector databases like Pinecone, embedding vectors, semantic layers, data modeling, and orchestrating data pipelines. Each element is customized to suit the requirements of the RAG system.
Here are some key components of RAG (Retrieval-Augmented Generation) development, explained simply:
1. Retriever: This component searches a knowledge base (like documents or databases) to find the most relevant information based on the user’s query. It’s like the AI’s “research assistant.”
2. Knowledge Base / Vector Store: A structured collection of documents or data chunks, stored in a format that allows fast and accurate search, usually via embeddings in a vector database (e.g., Pinecone, FAISS).
3. Embedding Model: Converts user queries and documents into vector formats (numeric form) to be compared for relevance. Popular models include OpenAI’s or Sentence Transformers.
4. Generator (LLM): The large language model (like GPT-4) takes the retrieved documents and generates a human-like response, ensuring the answer is contextually relevant and grounded in the retrieved info.
5. Orchestration Layer: Coordinates the entire pipeline—from query input to retrieval to generation. Tools like LangChain or LlamaIndex help developers streamline this flow efficiently.
How Does RAG Work?
1. Query Processing: The RAG workflow begins when a user submits a query. This query serves as the starting point for the system’s retrieval mechanism.
2. Data Retrieval: Based on the input query, the system searches its database for relevant information. This step utilizes sophisticated algorithms to identify and retrieve the most appropriate and contextually aligned data.
3. Integration with the LLM: The retrieved information is combined with the user’s query and provided as input to the LLM, creating a context-rich foundation for response generation.
4. Response Generation: The LLM, empowered by the contextual data and the original query, generates a response that is both accurate and tailored to the specific needs of the query.
What is Fine-Tuning?
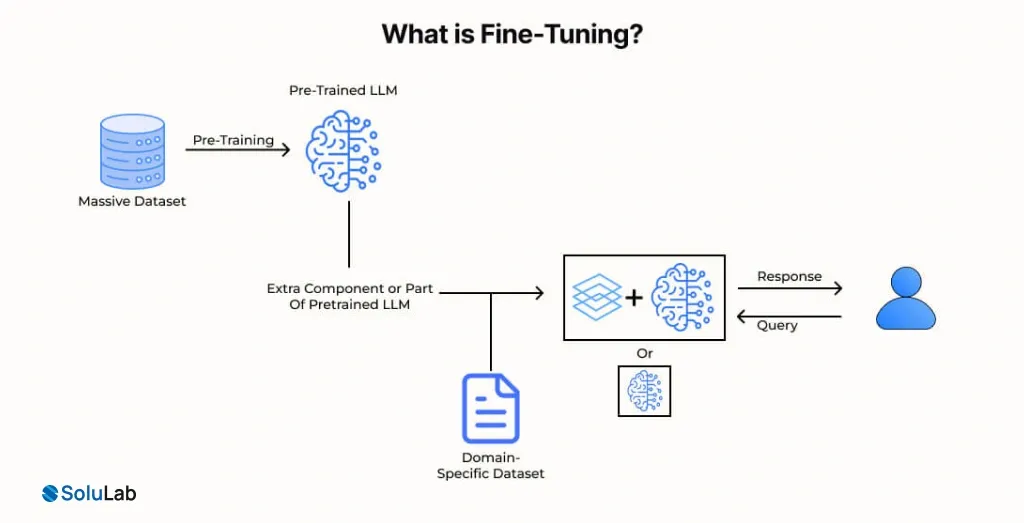
Fine-tuning offers an alternative method for developing generative AI by focusing on training a large language model (LLM) with a smaller, specialized, and labeled dataset. This process involves modifying the model’s parameters and embeddings to adapt it to new data.
- Place the image here
When it comes to enterprise-ready AI solutions, both Retrieval-Augmented Generation (RAG) and fine-tuning aim for the same objective: maximizing the business value derived from AI models. However, unlike RAG, which enhances an LLM by granting access to a proprietary database, fine-tuning takes a more in-depth approach by customizing the model itself for a specific domain.
The fine-tuning process focuses on training the LLM using a niche, labeled dataset that reflects the nuances and terminologies unique to a particular field. By doing so, fine-tuning enables the model to perform specialized tasks more effectively, making it highly suited for domain-specific applications.

Types of Fine-Tuning for LLMs
Fine-tuning large language models (LLMs) isn’t one-size-fits-all—there are several approaches, each tailored to different goals, data sizes, and resource constraints. Here are some types of fine tuning for LLMs:
1. Supervised Adjustment
Using a task-specific dataset with labeled input-output pairs, supervised fine-tuning includes further training of a previously trained model. Through this process, the model can learn how to use the provided dataset to map inputs to outputs.
How it works:
- Make use of a trained model.
- As the model requires, create a dataset with input-output pairings.
- During fine-tuning, update the pre-trained weights to help the model adjust to the new task.
When labeled datasets are available, supervised fine-tuning is perfect for applications like named entity recognition, text classification, and sentiment analysis.
2. Instructional Adjustment
In the prompt template, instruction fine-tuning adds extensive guidance to input-output examples. This improves the model’s ability to generalize to new tasks, particularly ones that require instructions in plain language.
How it works:
- Make use of a trained model.
- Get a dataset of instruction-response pairs ready.
- Like neural network training, train the model using the instruction fine-tuning procedure.
Building chatbots, question-answering systems, and other activities requiring natural language interaction frequently use instruction fine-tuning.
3. PEFT, or parameter-efficient fine-tuning
A complete model requires a lot of resources to train. By altering only a portion of the model’s parameters, PEFT techniques lower the amount of memory needed for training, allowing for the efficient use of both memory and compute.
PEFT Techniques:
- Selective Method: Only fine-tune a few of the model’s layers while freezing the majority of them.
- LoRA, or the Reparameterization Method: Model weights can be reparameterized by adding tiny, trainable parameters and freezing the previous weights using low-rank matrices.
For instance, 32,768 parameters would be needed for complete fine-tuning if a model had dimensions of 512 by 64. The number of parameters can be lowered to 4,608 with LoRA.
- Additive Method: The additive method involves training additional layers on the encoder or decoder side of the model for the given job.
- Soft Prompting: Keep other tokens and weights frozen and train only the newly introduced tokens to the model prompt.
PEFT lowers training costs and resource needs, which is helpful when working with huge models that exceed memory restrictions.
4. Human Feedback Reinforcement Learning (RLHF)
RLHF uses reinforced learning to match the output of a refined model to human preferences. After the initial fine-tuning stage, this strategy improves the behavior of the model.
How it works:
- Prepare Dataset: Create prompt-completion pairs and rank them according to the alignment standards used by human assessors to prepare the dataset.
- Train Reward Model: Create a reward model that uses human feedback to provide completion scores.
- Revise the Model: Update the model weights based on the reward model using reinforcement learning, usually the PPO algorithm.
For applications requiring human-like outputs, including producing language that complies with ethical standards or user expectations, RLHF is perfect.
How Fine-Tuning Works?
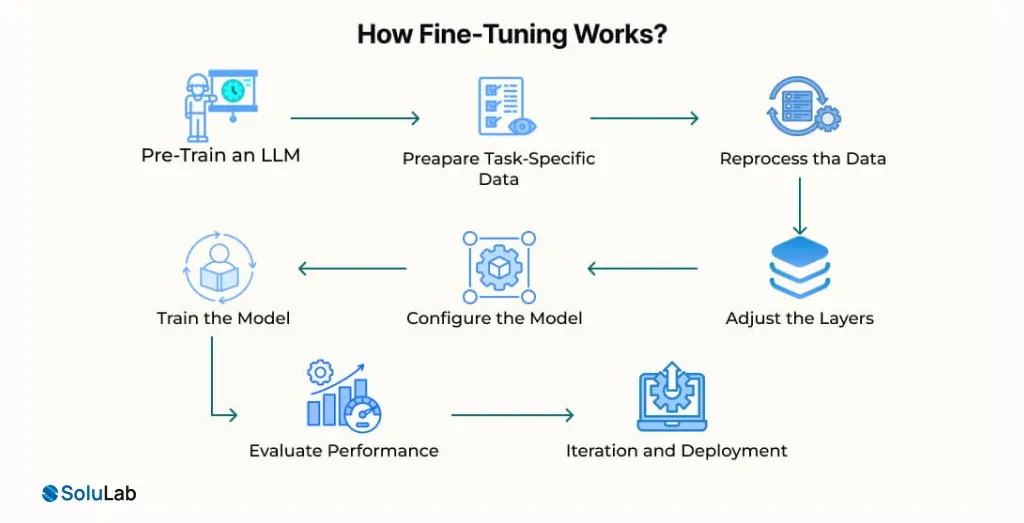
Fine-tuning is a critical step for customizing large language models (LLMs) to perform specific tasks. Here’s a detailed explanation of the process, emphasizing fine-tuning RAG for beginners.
1. Start with a Pre-Trained Model: Begin with a pre-trained language model that already understands basic language patterns and text relationships. Fine-tuning helps adapt this general model to perform a specific task more accurately.
2. Collect Task-Specific Data: Gather a smaller dataset related to your task, such as customer queries or product information. Divide the data into training, validation, and testing sets to evaluate performance properly.
3. Clean and Prepare the Data: Check the dataset for errors, duplicates, or incomplete entries and remove them. Well-structured and clean data help the model learn better and produce more reliable results.
4. Adjust Model Layers: Pre-trained models have multiple layers that process information. During fine-tuning, only the top layers are updated so the model learns the new task while keeping its core language knowledge.
5. Configure Training Settings: Set important parameters such as learning rate, batch size, and number of training cycles. These settings control how fast and effectively the model learns from the new dataset.
6. Train the Model: Feed the prepared data into the model so it can learn patterns related to the task. The system adjusts its responses during training to reduce errors and improve accuracy.
7. Evaluate Model Performance: Test the model using new, unseen data to measure how well it performs. Use evaluation metrics or human feedback to check the accuracy and usefulness of the results.
8. Improve and Deploy the Model: If needed, refine the model by repeating training with better data or settings. Once the results are satisfactory, deploy the model in real applications for practical use
Differences Between RAG and LLM Fine-Tuning
The table below highlights the key distinctions between LLM RAG vs Fine-Tuning to help understand when to choose each approach. Both methods serve the purpose of enhancing large language models (LLMs), but their methodologies and applications differ significantly.
| Aspect | RAG (Retrieval-Augmented Generation) | LLM Fine-Tuning |
| Objective | Augment responses with external retrieved data at inference time for factual accuracy and freshness | Adapt model weights during training for specialized behavior, style, or domain expertise |
| Data Dependency | Relies on external knowledge base (e.g., vector database) that must be indexed and maintained | Requires labeled training dataset specific to the task |
| Training Effort | Minimal; no model retraining, just setup retrieval pipeline | High; compute-intensive training process, often thousands to hundreds |
| Knowledge Update | Dynamic and real-time via updated external sources, no retraining needed | Static post-training; requires full retraining for updates |
| Inference Cost | Higher per query due to retrieval step adding latency and compute | Lower; fast inference after one-time training |
| Customization Level | Moderate; flexible context injection but limited style/behavior changes | High; deep adaptation of tone, terminology, and reasoning |
| Best For | Enterprise support agents, researchers, journalists | Domain specialists (finance, healthcare, legal), automation engineers |
| Examples | Chatbots with enterprise docs, news summarization | Sentiment analysis in finance, medical diagnosis tuning |
Build Enterprise AI Systems with SoluLab
SoluLab helps enterprises build scalable AI systems that automate workflows, unlock insights from data, and improve decision-making using advanced machine learning, LLMs, and enterprise-grade AI architectures.
SoluLab uses AI to work smartly and efficiently. Also, we provide faster deliverables at budget costs. Here are the services we can help you with:
Services
- Custom large language model development
- Retrieval-augmented generation (RAG) implementation
- Enterprise AI knowledge assistant development
Intelligent AI chatbot development solutions
Case Study
SoluLab helped InfuseNet, an AI platform that enables businesses to import and integrate data from texts, images, documents, and APIs to build intelligent and personalized applications.
The platform features a drag-and-drop interface that connects advanced models such as GPT-4 and GPT-NeoX. This makes it easier for teams to build ChatGPT-like applications using private business data while maintaining strong security and operational efficiency.
With integrations for services like MySQL, Google Cloud, and CRM platforms, InfuseNet allows organizations to build data-driven applications that improve productivity, streamline workflows, and support better business decision-making.

Conclusion
Retrieval-Augmented Generation (RAG) and LLM fine-tuning both help businesses build more accurate and domain-aware AI systems.
If your goal is knowledge retrieval and lower maintenance costs, RAG is often the better choice. If you need deeply customized responses and specialized expertise, fine-tuning may be more suitable.
Choosing the right approach depends on your data, use case, and scalability goals. SoluLab, an LLM development company, can help your business design and implement the right AI architecture for long-term success.
FAQs
Shipra Garg is a tech-focused content strategist and copywriter specializing in Web3, blockchain, and artificial intelligence. She has worked with startups and enterprise teams to craft high-conversion content that bridges deep tech with business impact. Her work translates complex innovations into clear, credible, and engaging narratives that drive growth and build trust in emerging tech markets.


![Top 10 MLOps Consulting Companies in the USA [2026]](https://www.solulab.com/wp-content/uploads/2025/12/Top-MLOps-Consulting-Companies-in-USA.webp)