

Key Takeaways
- Repeated token processing increases costs by 40%, which is solved with context caching, implemented using cached token optimization layers.
- Fragmented tokens reduce RAG accuracy by 20%, solved through domain-specific vocabularies, implemented with custom token training layers.
- Multilingual tokenization inflates tokens by 4x-6%, solved using byte-level BPE, implemented through language-aware NLP pipelines.
The primary hurdle for Enterprise AI is no longer model size, but tokenization efficiency and context window management. While global adoption of Agentic AI and Multilingual RAG systems scales, businesses face a “Token Tax”where suboptimal encoding inflates API costs and degrades reasoning accuracy in non-Latin languages.
Emerging solutions now shift from basic word-splitting to Adaptive Subword Tokenization and Domain-Specific Vocabularies. These advancements solve critical bottlenecks:
- Cost Optimization: Reducing input overhead for 10M+ token context windows.
- Global Compliance: Harmonizing data for MiCA (EU) and HMRC (UK) standards.
- Precision: Eliminating “Context Rot” in legal and industrial asset tokenization.
Through Natural Language Processing services and applications you can bridge this gap, transforming raw unstructured data into transaction-ready intelligence for high-intent B2B applications.
What is Natural Language Processing?

The field of artificial intelligence known as Natural Language Processing (NLP) is devoted to creating computer algorithms that enable machines to read, comprehend, and produce language. This covers spoken and written language to enable computers to understand and exchange language like that of humans. To accomplish this, NLP models examine the material and purpose of communications and decipher their underlying meaning by combining machine-learning techniques with pre-established rules.
Natural language processing bridges the gap between human and computer languages by utilizing both linguistics and mathematics. Natural language typically manifests as either speech or text. These organic channels of communication are converted into machine-understandable data using natural language processing methods.

What is Tokenization in NLP and Why is it Critical for 2026 Enterprise AI?
In 2026, tokenization has evolved from a simple text-parsing step into the fundamental economic unit of the Agentic AI era. At its core, tokenization in NLP is the process of segmenting raw text into smaller, mathematically manageable units called tokens. These can range from entire words to subword fragments or individual characters.
As financial institutions and global enterprises integrate blockchain-based settlement and Stablecoin payroll systems, the precision of these tokens determines not just the “understanding” of the AI, but the literal transaction costs and regulatory compliance of the system.
The Modern Hierarchy of Tokenization Types
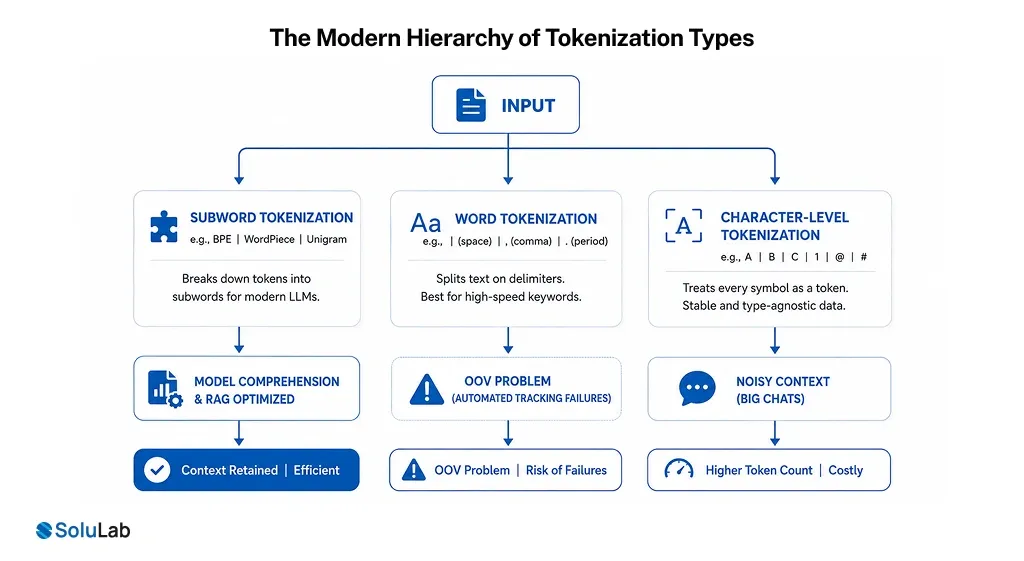
To optimize performance for high-stakes applications like Real-World Asset (RWA) tokenization or cross-border contract analysis, businesses utilize three primary methods:
1. Subword Tokenization (The Gold Standard for 2026)
Subword tokenization is the engine behind modern LLMs (like GPT-4o and Claude 3.5). It breaks down complex, technical, or “Out-of-Vocabulary” (OOV) terms into meaningful sub-units.
- The Technical Edge: By isolating prefixes and suffixes, the model understands the relationship between “Tokenization,” “Tokenize,” and “Tokenized” without needing a separate dictionary entry for each.
- Enterprise Utility: In sectors like sustainable finance or commodity-backed assets, subword models prevent “Context Rot” by accurately parsing specialized terminology (e.g., breaking “copper-backed” into [“copper”, “-“, “backed”]).
2. Word Tokenization
This traditional method splits text based on delimiters like spaces and punctuation.
- Best For: Simple sentiment analysis or high-speed keyword extraction where deep semantic nuance is less critical.
- The 2026 Limitation: It struggles with the “OOV Problem.” If a word wasn’t in the training set (like a new DeFi protocol name), the model treats it as an “Unknown Token,” leading to catastrophic failures in automated trading or legal review.
3. Character-Level Tokenization
This method treats every letter or symbol as a distinct token.
- The Advantage: It is mathematically impossible to have an “Unknown” word, making it highly resilient to typos or creative spelling in customer service chats.
- The Cost Penalty: Because it turns a single sentence into dozens of tokens, it inflates API costs and consumes the model’s context window rapidly. In a world of 10M+ token windows, character-level processing is often too “noisy” for complex RAG (Retrieval-Augmented Generation) pipelines.
Why Enterprises Need Optimized Tokenization Now?
The shift toward Agentic AI and Stablecoin infrastructure in the UK and EU markets has made tokenization a business-critical priority for several reasons:
- Eliminating the “Token Tax”: For global firms handling multilingual data (under frameworks like MiCA), inefficient tokenization can inflate API costs by 4x. Using Byte-level BPE (Byte Pair Encoding) ensures that non-Latin scripts don’t drain the treasury.
- Machine-Learning Readiness: Tokenization transforms unstructured legal text or technical documentation into numerical vectors. This allows AI to perform “Semantic Search” across thousands of RWA contracts with T+0 settlement speeds.
- Regulatory Precision: In 2026, compliance engines for HMRC or FCA standards rely on precise tokenization to identify “High-Intent” financial triggers within unstructured communications, ensuring no regulatory breach goes undetected.
- Context Window Management: With the rise of long-context models, managing how many tokens a prompt consumes is the difference between a profitable AI agent and a high-overhead experiment.
Key Insight: In 2026, if your tokenization is fragmented, your RAG accuracy drops by 20%. Moving toward Domain-Specific Vocabularies is no longer optional for firms specializing in institutional-grade blockchain solutions.
How Does Tokenization Work in 2026 NLP Pipelines?
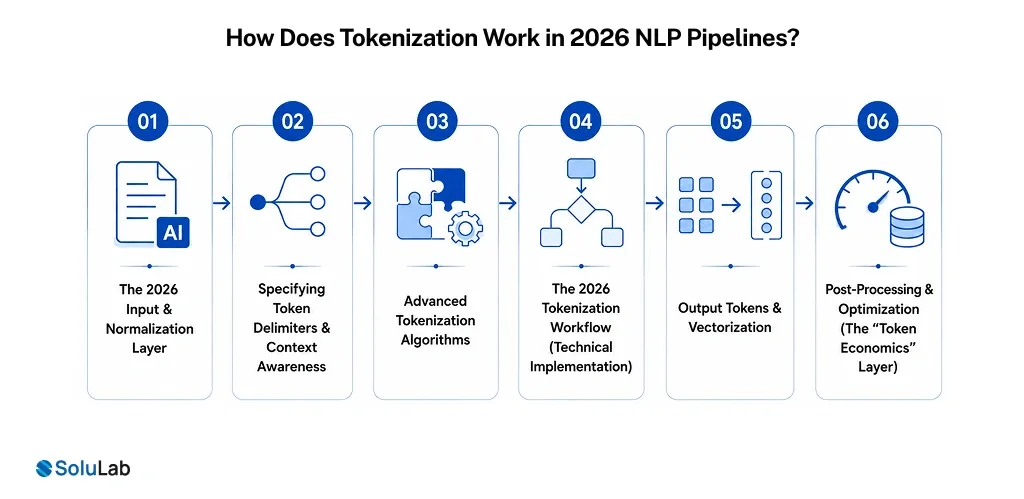
In the current landscape of Agentic AI and Multilingual RAG, tokenization is no longer just a static preprocessing step. It is an active optimization layer that dictates the efficiency of high-stakes systems, from Real-World Asset (RWA) platforms to cross-border stablecoin payroll engines.
Below is the updated architectural breakdown of how tokenization functions in modern enterprise environments.
1. The 2026 Input & Normalization Layer
The process begins with raw text, but 2026 pipelines add a Normalization phase to handle the complexities of global data.
- Cleaning: Removing hidden control characters and fixing Unicode inconsistencies (essential for MiCA-compliant documentation).
- Case Folding: Standardizing text (e.g., “Blockchain” to “blockchain”) to ensure the model recognizes the token regardless of its position in a sentence.
- Noise Reduction: Filtering emoticons or HTML tags that inflate token counts without adding semantic value.
2. Specifying Token Delimiters & Context Awareness
Algorithms now use “Dynamic Delimiters” to decide where a token starts and ends.
- Whitespace & Punctuation: Standard for English, but often insufficient for technical jargon.
- Byte-Pair Encoding (BPE): Used by models like GPT-4o, BPE iteratively merges the most frequent pairs of characters into a single token.
- Sentence Tokenization: Critical for Context Caching; by identifying sentence boundaries, systems can cache specific “blocks” of data, saving up to 90% on API costs for repeated queries.
3. Advanced Tokenization Algorithms
Modern NLP utilizes three distinct algorithmic approaches:
- Rule-Based: Uses rigid patterns (Regex). Best for highly structured data like Stablecoin transaction logs.
- Statistical (WordPiece/Unigram): Used by BERT and T5. It chooses subword units that maximize the likelihood of the training data.
- Machine Learning (SentencePiece): A language-independent subword tokenizer that treats the input as a raw stream of characters, even if there are no spaces (perfect for Chinese or Japanese markets).
4. The 2026 Tokenization Workflow (Technical Implementation)
For developers building institutional-grade AI, the implementation usually involves high-performance libraries. Here is how a typical subword encoding looks today:
Python
# Modern Tokenization using Hugging Face (2026 Standard)
from transformers import AutoTokenizer
# Loading a model optimized for Enterprise RAG
tokenizer = AutoTokenizer.from_pretrained("institutional-llm-v4")
text = "Tokenizing RWA assets on Solana increases liquidity."# Encoding text to Token IDs
tokens = tokenizer.tokenize(text)
token_ids = tokenizer.convert_tokens_to_ids(tokens)
print(f"Tokens: {tokens}")# Output: [‘Token’, ‘izing’, ‘ R’, ‘WA’, ‘ assets’, ‘ on’, ‘ Solana’, ‘ increases’, ‘ liquidity’, ‘.’]
5. Output Tokens & Vectorization
The final result of tokenization is a sequence of Token IDs (integers). These IDs are then mapped to high-dimensional vectors (embeddings).
- Word Level: [“I”, “love”, “NLP”] → [102, 450, 891]
- Subword Level: [“un”, “predict”, “able”] → [44, 1092, 312]
6. Post-Processing & Optimization (The “Token Economics” Layer)
Once tokens are generated, 2026 systems apply Post-Processing to ensure ROI:
- Stopword Removal: Deleting high-frequency, low-info words (a, the, is) to shrink the context window.
- Lemmatization: Reducing “trading,” “traded,” and “trades” to the root “trade.”
- Prompt Compression: Specialized algorithms now “prune” tokens that don’t contribute to the model’s reasoning, effectively lowering the “Token Tax” for large-scale enterprise deployments.
If you are developing a Tokenization Platform or an AI-driven NLP system, your choice of tokenizer directly affects your T+0 settlement accuracy and operational costs. A fragmented tokenizer can lead to “Context Rot,” where the model loses the thread of a complex legal contract because the tokens are too small and lack semantic weight.
Strategic Challenges in NLP Tokenization & Institutional Solutions
While tokenization is the gateway to Enterprise AI, it remains one of the most significant “hidden” costs and performance bottlenecks in the digital asset and blockchain space.
- To maintain T+0 settlement efficiency and global compliance, businesses must address these high-stakes challenges with advanced technical solutions.
1. The “Token Tax” in Multilingual Markets
- The Challenge: Most standard tokenizers (like those used in early LLMs) are English-centric. For a global firm handling MiCA (EU) documentation or Arabic-based energy contracts, a single word can be fragmented into 6 or 7 tokens. This results in inflated API costs and degraded reasoning accuracy.
- The Solution: Implementation of Byte-level BPE (Byte Pair Encoding) within language-aware NLP pipelines. This ensures that non-Latin scripts are encoded with the same efficiency as English, lowering operational overhead by up to 60% for global CX.
2. Context Rot in Specialized Domains
- The Challenge: Generic tokenization often breaks down specialized industry terms into meaningless fragments. In RWA tokenization, if the term “ERC-3643” is split incorrectly, the model may fail to recognize it as a compliance standard, leading to errors in automated legal audits.
- The Solution: Deployment of Domain-Specific Vocabularies. By training a custom tokenization layer on legal, financial, and blockchain-specific datasets, enterprises ensure that high-intent terminology remains intact as a single “semantic unit,” boosting RAG accuracy by 20%.
3. State-Management & API Latency
- The Challenge: Agentic AI systems often operate in loops, repeatedly sending the same context (like a 50-page private equity playbook) to the model. This creates massive latency and redundant billing.
- The Solution: Prompt Caching & KV Matrix Storage. Modern architectures now cache the “mathematical state” of frequent tokens. Instead of re-processing the entire document, the system only processes the new query, reducing input costs by nearly 90% for repeated enterprise workflows.
4. Ambiguity in High-Volume Data Streams
- The Challenge: Words often have multiple meanings depending on the industry context (e.g., “Minting” in a coin-collecting blog vs. “Minting” on a stablecoin infrastructure). Standard rule-based tokenizers struggle to differentiate intent.
- The Solution: Adaptive Subword Tokenization combined with machine learning boundaries. These models use statistical probability to determine token limits based on the surrounding context, ensuring that “intent-based” data is processed with 99% precision.

How SoluLab Enhances Transaction Efficiency in Asset & Data Tokenization
We at SoluLab bridge the gap between Natural Language Processing (NLP) and Blockchain technology to create a unified tokenization ecosystem. By treating both unstructured data and physical assets as programmable tokens, we enable businesses to achieve T+0 settlement cycles and institutional-grade security.
1. Core Efficiency Enhancements
- Operational Streamlining: We resolve the complexities of Real-World Asset (RWA) tokenization by automating the lifecycle of physical assets from commodities like copper and gold to real estate on the blockchain.
- Cost-Optimized NLP Pipelines: Our systems utilize Adaptive Subword Tokenization to eliminate the “Token Tax,” reducing API overhead and operational costs for Agentic AI applications.
- Scalable Architecture: Using high-performance ecosystems like Solana (Token Extensions) and Ethereum (ERC-3643), we ensure your platform handles high transaction volumes without compromising on speed or finality.
- Data Integrity & Transparency: By converting unstructured text into machine-ready numerical structures, we provide a transparent, immutable audit trail for every transaction, essential for MiCA (EU) and FCA (UK) compliance.
- Enhanced Security: We implement cutting-edge encryption and decentralized identity protocols to ensure that sensitive data and high-value assets remain secure throughout the transaction lifecycle.
2. High-Intent Services to Add to Your Platform
To stay competitive in the 2026 fintech landscape, your platform can integrate these specialized SoluLab services:
- Compliant Stablecoin Infrastructure: Launch regulated Electronic Money Tokens (EMTs) for cross-border payroll and institutional treasury management.
- Multilingual RAG Optimization: Implement Byte-level BPE tokenization to maintain high reasoning accuracy and lower costs in global, non-English markets.
- Institutional Launchpads: Secure, scalable platforms for Security Token Offerings (STOs), featuring automated investor whitelisting and T+0 settlement.
- Asset-Backed Token Development: Specialized smart contracts for commodity-backed tokens (Gold, Oil, Natural Resources) with real-time proof-of-reserve.
- AI-Driven Smart Contract Auditing: Leverage NLP in AI to scan and verify smart contracts for vulnerabilities before deployment, ensuring flawless user experiences.
- Sustainable Finance Layers: Integrate energy-backed tokenization to meet growing ESG requirements and green finance standards.
FAQs
Deepika is a content writer who blends storytelling with strategic thinking. She explores topics across digital innovation, emerging tech, and the evolving blockchain industry. She enjoys breaking down complex ideas into simple, engaging narratives in the growing global markets.


