

Key Takeaways
- Agentic RAG introduces decision-making into retrieval systems
- It shifts from single-step retrieval to iterative reasoning
- Systems can plan, retrieve, evaluate, and refine outputs
- Agentic RAG works best for complex, multi-step queries
- Architecture is defined by control flow, not just components
- LangChain and similar frameworks enable modular implementation
- Key challenges include cost, explainability, and data quality
- Best approach is phased adoption, not full system replacement
For a while, Retrieval-Augmented Generation felt like the answer to everything LLMs couldn’t solve.
Hallucinations? Add retrieval.
Context gaps? Add more documents.
But reality caught up quickly.
Static retrieval pipelines struggle when questions become layered, ambiguous, or evolving. That’s where Agentic RAG (Retrieval-Augmented Generation) begins to matter not as an upgrade, but as a shift in how systems reason.
Instead of fetching data, systems start deciding how to fetch it.
And that changes everything.
Why Traditional RAG Hits a Ceiling?
For a while, traditional RAG systems felt like a clean fix to LLM limitations.
You connect a model to external data, improve grounding, reduce hallucinations, problem solved.
Except, in practice, that only holds true for a narrow class of problems.
The moment queries become even slightly exploratory, things begin to break down.
A user doesn’t always ask:
- a well-formed question
- about a single document
- with a clear, static context
Instead, real queries often look like:
- “Compare multiple perspectives.”
- “Summarize evolving information.”
- “Figure out what matters and then explain it.”
And this is where traditional RAG shows its limits.
The structural limitation
At its core, traditional RAG is still a linear system:
- retrieve once
- generate once
It doesn’t:
- Revisit its own outputs
- question the quality of retrieved data
- adapt its strategy mid-way
So when the problem requires thinking, not just fetching, the system stalls.
What this means in real systems?
In enterprise environments, this shows up as:
- incomplete answers despite having the data
- Irrelevant retrieval due to weak context understanding
- inability to handle multi-step queries
This is exactly the gap where rag-agentic AI systems begin to take over, not by improving retrieval alone, but by rethinking how retrieval decisions are made.
What Is Agentic RAG?
To understand Agentic RAG (Retrieval-Augmented Generation), it helps to shift the mental model.
This is not just a better pipeline. It’s a different way of structuring artificial intelligence.
Instead of treating retrieval as a fixed step, agentic systems treat it as a process that can evolve.
From pipeline to system
In a traditional setup:
- The system executes instructions
In an agentic setup:
- The system decides what to do next
That distinction is subtle but powerful.
Agentic RAG introduces AI agents that:
- interpret intent beyond the surface query
- decide how to approach the problem
- dynamically choose tools and data sources
- refine outputs through multiple iterations
A more intuitive analogy
If traditional RAG is like:
- looking up an answer in a book
Agentic RAG is like:
- assigning a researcher who:
- understands the question
- checks multiple sources
- validates findings
- and then explains the answer clearly
That added layer of agency is what enables systems to handle complexity.

Core Capabilities That Define Agentic RAG
What makes an agentic RAG framework powerful isn’t just better components – it’s how those components interact.
The system stops behaving like a pipeline and starts behaving like a coordinated decision engine.
3.1 Goal-driven execution
Agentic AI systems don’t just react, they operate with intent.
Instead of directly answering a query, they first interpret:
- What outcome is expected
- What steps might be required
This allows the system to:
- break down ambiguous queries
- Prioritize relevant information
- Stay aligned with the end goal
3.2 Multi-step reasoning (where real gains happen)
Complex queries are rarely solved in a single pass.
Agentic systems:
- decompose queries into smaller parts
- solve them individually
- and then stitch results together
But more importantly, they re-evaluate along the way.
If something doesn’t add up, they adjust something that traditional RAG cannot do.
This is where agentic RAG architecture becomes essential, because AI orchestration replaces linear execution.
3.3 Tool-aware intelligence
Not all information lives in one place, and agentic systems understand that.
They can dynamically decide:
- When to query a vector database
- When to fetch structured data
- When to call external APIs
This flexibility transforms the system from:
- a static retriever
to - an adaptive problem solver
3.4 Context that evolves, not resets
Traditional systems treat each query as isolated.
Agentic systems maintain:
- intermediate reasoning
- prior outputs
- evolving context
This allows them to:
- refine answers
- maintain continuity
- and handle long, layered interactions
3.5 Built-in evaluation loops
Perhaps the most important shift agentic systems don’t assume they are right.
They check:
- Is the answer complete?
- Is the source reliable?
- Do we need another retrieval pass?
This internal feedback loop is what significantly improves output quality in real-world AI deployments.
Bringing it together
Individually, these capabilities are useful. Together, they redefine what retrieval systems can do.
Instead of answering questions, agentic RAG frameworks start solving problems.
How Agentic RAG Works?
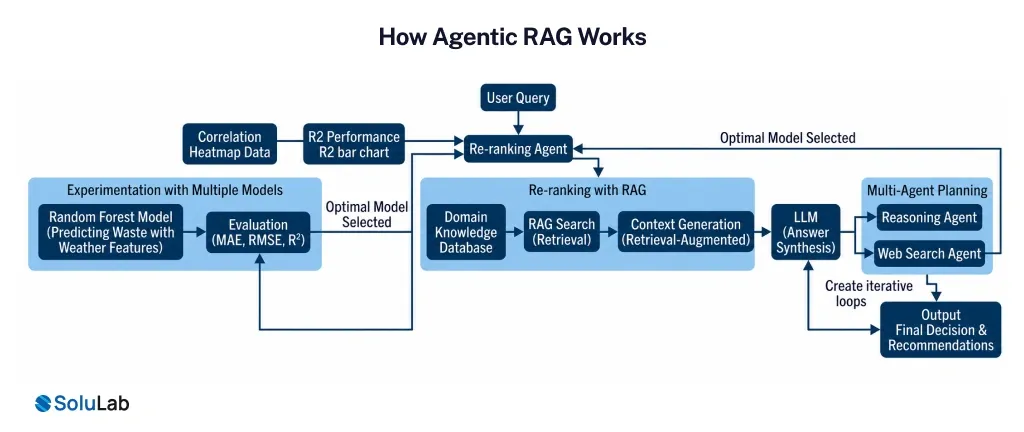
Understanding Agentic RAG (Retrieval-Augmented Generation) becomes much easier when you stop thinking in terms of steps… and start thinking in terms of behavior.
Because what’s really changing here isn’t just the pipeline – it’s how the system approaches a problem.
- It starts with interpretation, not retrieval
In traditional systems, a query immediately triggers retrieval.
Agentic systems pause.
They first try to understand:
- What is the user actually asking?
- Is this a simple lookup or a layered problem?
- Do we need reasoning before retrieval?
This initial interpretation determines everything that follows.
- Then comes planning – the missing layer in RAG
Instead of jumping to answers, the system builds a plan.
Not a rigid workflow, but a flexible outline:
- What needs to be answered first?
- What information is required?
- Which tools might be needed?
In many agentic RAG LangChain implementations, this planning layer is explicitly modeled — because without it, systems fall back into static behavior.
- Retrieval becomes iterative, not one-shot
Once the plan is in place, retrieval begins — but not as a single step.
The system:
- retrieves initial information
- evaluates whether it’s sufficient
- refines the query if needed
- retrieves again
This loop continues until the system has enough confidence to move forward.
This is one of the defining characteristics of a mature agentic RAG framework.
- Tools are used contextually, not pre-wired
In traditional setups, tools are predefined in the pipeline.
Here, the system decides:
- whether a tool is needed
- Which tool fits the context
- When to invoke it
That could mean:
- querying a vector database
- pulling structured data
- calling an external API
This flexibility is what allows agentic systems to operate across complex environments.
- Reasoning and synthesis happen together
As information flows in, the system doesn’t wait until the end to generate an answer.
It continuously:
- connects pieces of information
- checks for inconsistencies
- refines intermediate conclusions
By the time the final response is generated, much of the “thinking” has already happened.
- Validation is no longer optional
One of the most important additions in agentic RAG architecture is validation.
Before returning an answer, the system may:
- verify sources
- Check logical consistency
- trigger additional retrieval if gaps exist
This is critical in enterprise use cases where correctness matters more than speed.
A simple agentic RAG example
Let’s take a practical scenario:
“Evaluate whether launching a crypto exchange in Europe is more viable than in Southeast Asia.”
A traditional system might:
- retrieve generic documents
- generate a high-level answer
An agentic system would:
- break the query into regions
- retrieve regulatory, market, and compliance data separately
- Compare across parameters
- identify missing pieces
- refine retrieval
- and then synthesize a structured answer
That’s a real agentic RAG example, and it shows why these systems are moving beyond simple Q&A into decision support.
Agentic RAG vs Traditional RAG: Where the Shift Really Happens
At first glance, the difference between traditional and agentic RAG can feel like an upgrade.
Better retrieval. Smarter outputs. Slightly more flexible pipelines.
But when you look closely, the change is deeper than that.
It is not about improving retrieval. It is about changing how decisions are made before, during, and after retrieval.
Traditional RAG solves for relevance
A typical system is designed to answer one question:
What information best matches this query?
So it retrieves once, passes context to the model, and generates a response.
If the query is clean and the data is well structured, this works surprisingly well.
But the system assumes something important. It assumes the query is already complete.
That assumption rarely holds in real scenarios.
Agentic RAG solves for resolution
Agentic systems approach the same problem differently.
Instead of asking what to retrieve, they ask:
What needs to happen to solve this?
That might include:
- breaking the query into smaller parts
- checking multiple sources
- Revisiting earlier steps
- pulling in external tools
The system is no longer chasing relevance alone. It is trying to reach a reliable outcome.
Why this difference become visible in production?
In controlled demos, both approaches can look similar.
In production, the gap becomes obvious.
Traditional RAG:
- struggles with ambiguity
- returns partially correct answers
- requires constant prompt tuning
Agentic RAG:
- handles evolving queries
- corrects itself mid-process
- reduces dependency on manual orchestration
This is why many teams moving toward RAG agentic AI systems are not doing it for performance gains alone. They are doing it to reduce fragility.
A simple way to think about it
Traditional RAG:
- retrieves and answers
Agentic RAG:
- explores, verifies, and then answers
That extra layer of thinking is what changes system behavior.
How Agents Actually Function Inside the System?
Talking about agent “types” often makes things more confusing than helpful.
In real systems, agents are not categories. They are roles that emerge depending on what the system needs to do.
So instead of listing types, it helps to follow what happens when a query enters the system.
First, something decides where to begin
Every query needs a starting point. Sometimes it is obvious. Sometimes it is not.
A reasoning AI agent looks at the query and makes an initial call:
- Should this go to a knowledge base
- Should it trigger a structured query
- Or does it need deeper reasoning first
This is the system figuring out direction before doing any real work.
Then the problem gets broken down
If the query is even slightly complex, it cannot be solved in one go.
So the system starts splitting it.
Not mechanically, but logically:
- What are the sub-questions here
- What needs to be answered first
- What depends on what
This is where agentic systems start resembling how a human would approach a problem.
Now the system starts interacting with the world
At this point, information is not just retrieved. It is gathered.
The system may:
- query a vector database
- Pull structured data
- call an API
- or combine all three
In many agentic RAG LangChain setups, this is where tools become critical building blocks.
But the key difference is this. Tools are not pre-decided. They are chosen in context.
Thinking and acting start to loop together
Once the system begins executing, it does not move in a straight line.
It cycles:
- retrieve something
- evaluate it
- decide what is missing
- retrieve again
This loop continues until the system feels it has enough to answer properly.
This is the part most traditional systems simply cannot do.
Eventually, everything comes together
By the time the final response is generated, the system has:
- explored multiple paths
- filtered irrelevant data
- refined its own understanding
So the output is not just generated. It is constructed.
Why this matters
When you look at it this way, agents are not features.
They are what allow the system to:
- pause
- think
- adjust
- and continue
Without that, you are still operating a pipeline. Just a slightly better one.

What an Agentic RAG Architecture Really Implies?
Most discussions around architecture focus on components.
Vector databases. LLMs. APIs. Tools.
Those are necessary. But they are not what defines an agentic RAG architecture.
What matters more is how control flows through the system.
In traditional setups, control is predefined
The system follows a path that is already decided:
- query comes in
- retrieval happens
- generation follows
There is very little room to deviate.
Even when things go wrong, the system continues on the same path.
In agentic systems, control is fluid
There is still structure, but it is not rigid.
The system can:
- decide to retrieve again
- switch tools
- reframe the query
- or stop and synthesize
So instead of a pipeline, you now have something closer to a controlled loop.
The architecture starts to organize itself around decisions
If you map it out, most agentic systems naturally settle into a few layers.
A layer where inputs enter.
A layer where decisions are made.
A layer where information is retrieved.
A layer where outputs are generated.
But the important part is not the layers. It is how often the system moves between them.
The orchestration layer becomes the center
This is where most of the intelligence sits.
It is responsible for:
- planning
- coordinating agents
- managing execution
- tracking intermediate state
Without a strong orchestration layer, the system falls back into static behavior very quickly.
Retrieval stops being a single step
In this setup, retrieval is no longer a one-time action.
It becomes something the system can:
- trigger multiple times
- refine based on context
- or skip entirely if not needed
This alone changes how efficient and accurate the system becomes.
Memory quietly becomes critical
One of the most underestimated parts of the architecture is memory.
Not just chat history, but:
- What has already been retrieved
- What decisions were made
- What paths were explored
Without this, the system keeps repeating work or loses context mid-process.
Implementing Agentic RAG Without Overengineering It
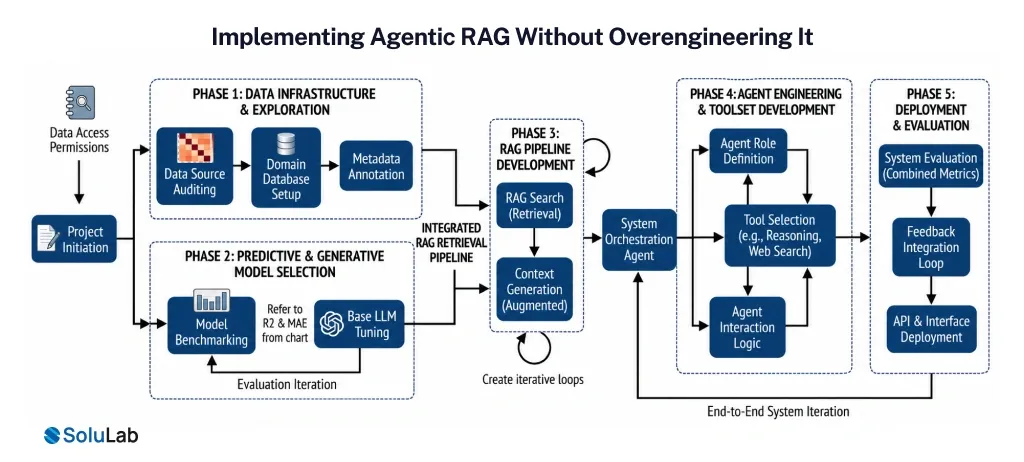
At this point, the concept sounds powerful. The temptation is to build everything at once.
That is usually where things go wrong. Agentic AI systems are not difficult because of models. They are difficult because of coordination.
So the goal is not to build a complex system.
The goal is to build a system that can evolve into one.
Start with a controlled use case
Before thinking about full-scale deployment, it helps to narrow the scope.
Pick a use case where:
- Queries are slightly complex but not unpredictable
- Data sources are known
- outputs can be evaluated clearly
This allows you to introduce agentic behavior without losing control.
Introduce decision points gradually
Instead of replacing your entire RAG pipeline, start by adding one layer of decision-making.
For example:
- allow the system to decide whether retrieval is needed
- or allow it to refine queries before retrieval
This small shift already moves you toward a RAG agentic AI setup without breaking existing systems.
Use frameworks, but do not depend on them blindly
Frameworks like agentic rag langchain implementations and LlamaIndex make it easier to experiment.
They provide:
- tool abstractions
- agent orchestration utilities
- integrations with data sources
But they are still building blocks.
The real challenge is:
- How you define workflows
- how you manage state
- how you control execution
Frameworks help you move faster. They do not replace system design.
Read more- How to Build AI Agents with LangGraph
Treat tools as capabilities, not add-ons
One common mistake is to attach tools after building the system.
In agentic setups, tools should be part of the design from the beginning.
Ask:
- What kind of data access is required
- What actions the system should be able to take
- How those actions influence decisions
This is what makes the system adaptive instead of reactive.
Build visibility early
Agentic systems can become opaque very quickly.
Without visibility, it becomes difficult to answer simple questions:
- Why did the system take this path
- Why did it retrieve this data
- Why did it stop
So from the beginning, it helps to log:
- decisions made
- tools used
- intermediate outputs
This is not just for debugging. It is essential for trust.
Keep control where it matters
Not every decision should be left to the system.
In many enterprise setups, guardrails are required:
- limiting which tools can be used
- defining boundaries for data access
- enforcing validation rules
A good agentic rag framework balances autonomy with control.
Too much freedom creates unpredictability. Too much control removes the benefit of agents.
Risks, Constraints, and What Enterprises Actually Worry About
Agentic RAG sounds promising. But in real deployments, the conversation quickly shifts from capability to risk. Because once systems start making decisions, the cost of being wrong increases.
Data quality becomes more visible
Traditional systems already depend on data quality. AI-powered solutions expose their weaknesses more clearly.
If the underlying data is:
- incomplete
- inconsistent
- outdated
The system will still operate. But it may:
- draw incorrect conclusions
- reinforce weak signals
- or miss critical context
So the focus shifts from retrieval accuracy to data reliability.
Cost can grow in unexpected ways
Agentic systems often involve:
- multiple retrieval passes
- Repeated reasoning cycles
- tool interactions
If not managed carefully, this leads to:
- higher latency
- increased token usage
- unpredictable compute costs
This is why decision boundaries matter. Not every query needs full agentic depth.
Explainability is no longer optional
In simple systems, an answer is enough.
In agentic systems, stakeholders often ask:
- How did the system arrive at this
- What sources were used
- What decisions were made
Without clear reasoning traces, trust becomes difficult to build.
This is especially important in:
- finance
- healthcare
- regulated environments
Privacy and access control
Agentic systems interact with multiple data sources.
That introduces risks around:
- unauthorized access
- data leakage
- improper tool usage
So access control needs to be:
- enforced at the system level
- not just at the database level
The opportunity behind these constraints
Interestingly, these challenges are also what make agentic systems valuable.
Because solving them leads to:
- more robust architectures
- better governance models
- stronger system observability
This is where serious implementations begin to separate from experimental ones.
Operating Model: How to Decide What to Build and What Not To
By this stage, the technical discussion is only half the story.
The bigger question is: Where does an agentic approach actually make sense?
Because not every system needs it.
Start with the nature of the problem
Multi-agent systems are most useful when:
- queries are multi-step
- answers require synthesis across sources
- context evolves during interaction
If your use case is:
- simple retrieval
- structured queries
- deterministic outputs
A traditional RAG system may be enough.
Identify where decisions add value
The real advantage of agentic systems is decision-making.
So ask:
- Where does the system need to choose between multiple paths
- Where does context change mid-process
- Where does the answer depend on interpretation
If these points exist, agentic behavior is justified.
Build vs extend
Many teams assume they need to rebuild everything.
In reality, most successful systems evolve from existing pipelines.
You can:
- Extend current RAG systems with planning layers
- introduce agents for specific tasks
- gradually increase system autonomy
This reduces risk and allows controlled scaling.
Think in phases, not full systems
Trying to build a complete agentic system upfront often leads to unnecessary complexity.
A phased AI-led development approach works better:
- Phase 1: improved retrieval and query refinement
- Phase 2: introduce tool usage
- Phase 3: add planning and iterative reasoning
Each phase builds confidence and control.
Read more: how to build like UpdateIA
Where SoluLab fits into this journey?
At this stage, the challenge is no longer just technical.
It becomes about:
- aligning architecture with business goals
- managing compliance and risk
- designing systems that scale beyond prototypes
This is where teams often need support, not in building features, but in structuring systems correctly from the start. SoluLab, a leading AI agent development company, can help you with best practices and flawless execution.
A recent AI agent project, UpdateIA, is an example for you to understand the level of expertise our AI native team holds. It’s not just an AI agent but an orchestration system with 14+ AI agents handling different tasks at a time.

Conclusion
Agentic RAG is not just an evolution of retrieval systems. It is a shift in how systems approach problems. Instead of treating queries as static inputs, it treats them as starting points. From there, the system interprets, plans, explores, and refines before arriving at an answer.
That difference may seem subtle, but in practice it changes everything. It reduces fragility, improves reasoning depth, and allows systems to operate in environments where context is not fixed.
For teams building serious AI systems, the question is no longer whether retrieval is needed. That part is already solved.
The real question is whether your system needs to think along the way.
FAQs
Agentic RAG is an advanced form of retrieval-augmented generation where AI agents actively plan, retrieve, and refine information instead of relying on a single retrieval step. It introduces decision-making into the retrieval process.
Traditional RAG retrieves information once and generates a response. Agentic RAG can iteratively retrieve, evaluate, and refine its approach, making it more suitable for complex and multi-step queries.
An agentic RAG framework is a system design where agents manage planning, tool usage, and reasoning across multiple steps. It combines LLMs, retrieval systems, and external tools into a coordinated decision-making system.
A typical Agentic RAG system includes large language models (LLMs), vector databases, retrieval engines, agent frameworks, memory layers, planning modules, orchestration tools, and external integrations such as APIs, databases, and enterprise software.
AI agents act as intelligent decision-makers that can plan workflows, select retrieval strategies, evaluate results, coordinate tools, and take actions to accomplish complex objectives beyond simple question answering.
Agentic RAG enables AI agents to break down complex tasks into smaller steps, retrieve information from multiple sources, evaluate outcomes, and iteratively refine their approach before delivering a response or taking action.
Businesses should begin by identifying high-value workflows, organizing their knowledge sources, selecting the right AI and retrieval technologies, and partnering with an experienced AI development company, like SoluLab, to design, deploy, and scale an Agentic RAG solution effectively.
Bhavya is driving growth through data-backed demand generation for AI and Web3 solutions. With 9+ years in digital marketing, he has spearheaded initiatives that led to a 40% increase in qualified inbound leads. Bhavya shares insights on marketing ROI and scaling a digital presence via AI workflows. He is open to connecting with startups and enterprise teams to help them overcome their challenges.


