- AI Development
- AI App Development
- AI Consulting
- AI Software Development
- ChatBot Development
- Enterprise AI ChatBot
- AI Chatbot Development
- LLM Development
- Machine Learning Development
- AI Copilot Development
- MLOps Consulting Services
- AI Agent Development
- Deep Learning Development
- AI Deployment Services
- Deep Learning Consulting
- AI Token Development
- AI Development Company
- AI Development Company in Saudi Arabia
- AI Integration Services
Feeling overwhelmed by all the AI tools and their types, like GPT, Llama, open-source, and closed-source? As language models become more powerful, understanding the difference between platforms like Meta’s Llama and OpenAI’s GPT is more important than ever.
Choosing between open-source and closed-source AI isn’t just about tech; it affects cost, control, flexibility, and how fast you can innovate. Llama gives you freedom to tinker, while GPT offers a polished, plug-and-play experience. Each has its strengths, and what works for one use case might not work for another.
If you’ve ever asked yourself, “Should I go for an open-source model or stick with a commercial one? This blog will help you decide. We’ll break it down across performance, cost, efficiency, and practical use cases. Keep reading, and by the end, you’ll know exactly which model fits your needs!
What is the Llama?
LLaMA ( Large Language Model Meta AI) is an advanced AI model developed by Meta (formerly Facebook). It’s a smart assistant trained on a massive amount of text data to understand and generate human-like language. Just like ChatGPT, LLaMA can assist with tasks such as answering questions, developing content, summarizing articles, or even translating languages.
The best part? Meta designed LLaMA3 to be open and more accessible to researchers and developers, so they can build their own agentic AI tools using it.
Meta’s LLaMA has been downloaded over 1.2 billion times, showing its wide adoption across developers and SMBs. Here are some key features of LLaMA:
- High performance with fewer parameters – It’s more efficient, offering strong results without being too heavy on resources.
- Multilingual support – LLaMA understands and generates text in multiple languages.
- Trained on diverse datasets – This helps it understand a wide range of topics and contexts.
- Customizable – Developers can fine-tune LLaMA for specific tasks or industries.
- Open-source access – Meta allows researchers to access and experiment with the model.
- Fast and efficient inference – It’s designed to deliver quick responses with lower computing power.
What is GPT?
GPT stands for Generative Pre-trained Transformer. It’s a type of AI model developed by OpenAI that’s great at understanding and generating human-like text. It’s trained on massive amounts of data, so it can help with writing blogs, answering questions, drafting emails, coding, and even chatting just for fun.
Read Also: Build Your Own GPT Model In 5 Easy Steps
Here are some standout features of GPT:
- Natural language understanding – It gets the context of your questions and gives relevant answers.
- Text generation – You can ask it to write essays, summaries, poems, or anything in between.
- Multilingual support – GPT understands and responds in many languages, not just English.
- Code writing – It can write and explain code in different programming languages.
- Conversational ability – Feels like you’re chatting with a real person.
- Context awareness – It remembers parts of your conversation to keep the flow natural.

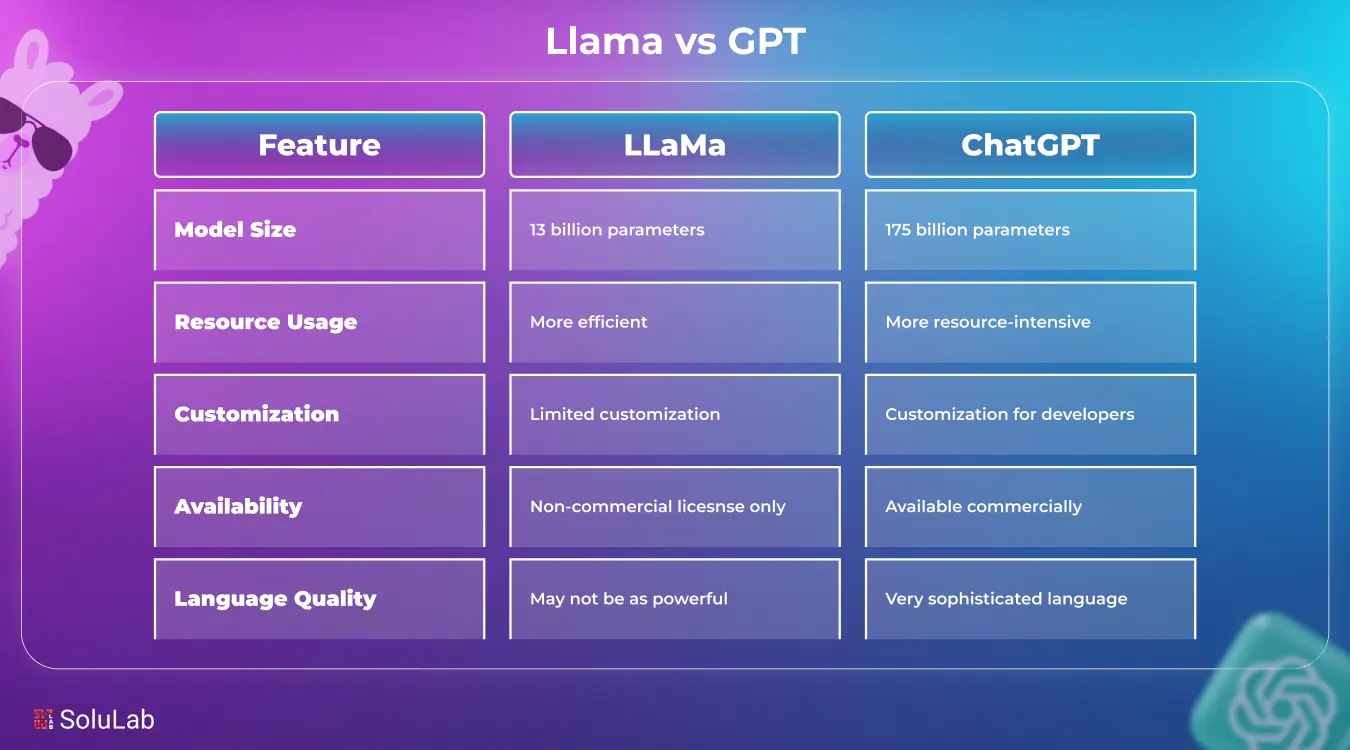
Llama vs GPT: Quick Comparison
Despite using natural language processing, Llama and GPT differ from one another in a number of ways. The following are some of the main distinctions between these two that we have covered.
1. Architecture and Model Size
Llama and GPT are different in terms of architecture and model size. The most recent iteration of GPT is a transfer-based model with billions of parameters that implements deep architecture. These enable GPT to produce text that makes sense.
However, the parameters in Llama range from 7 billion to 65 billion. With only a few computational resources, it can sustain high performance and is very efficient. Llama is therefore ideal in scenarios requiring quick deployment and little processing power.
2. Training Data and Sources
GPT is trained on a wide range of publicly available data like websites, books, and articles, making it very general-purpose. Llama, developed by Meta, uses a more curated dataset with a focus on high-quality, open-source text. So while GPT is broader, Llama is more focused on academic and structured content. This impacts how each model handles different types of questions.
3. Performance in Natural Language Processing (NLP)
When it comes to NLP tasks like summarizing, translating, or answering questions, GPT generally performs better out of the box. It’s polished, more versatile, and handles a wide range of tones and contexts smoothly. Llama also does well but may need more fine-tuning to match GPT’s fluency, especially for casual or creative use.
4. Efficiency and Computational Requirements
Llama is designed to be more lightweight and efficient, which means it can run on smaller devices or with fewer resources. GPT, while powerful, tends to need more computing power, especially for the larger versions. So if you’re working with limited infrastructure, Llama might be easier to manage.
5. Cost and Accessibility
GPT is mostly accessed through OpenAI’s paid plans or APIs, which can be a bit costly for high-volume use. LLM models, on the other hand, are open-source and free to use if you have the technical know-how to run them yourself. This makes Llama more budget-friendly but less plug-and-play than GPT.
6. Use Cases and Applications
GPT is used in everything from chatbots to content writing, coding help, and even tutoring. It’s flexible and easy to integrate via API. Llama is better suited for custom enterprise solutions or researchers looking to fine-tune models for specific use cases. It’s powerful, but requires more hands-on setup.
Read Also: How to Build a Multilingual Chatbot in 2025?
Pros and Cons of Llama
There are benefits and drawbacks to all technology. Llama is by no means unusual. Let’s examine some of this technology’s benefits and drawbacks.
1. Open-Source Freedom – You can access and modify the model as you like, which gives a lot more flexibility for developers and researchers.
2. Cost-Effective – Since it’s open-source, you don’t have to pay subscription fees like you would with GPT or other closed-source AI development.
3. Customizable – You can fine-tune Llama on your datasets to suit very specific tasks or industries.
4. Efficient Performance – Llama is built to be lightweight and can run on lower-end hardware compared to larger models like GPT-4.
Cons of Llama
1. Setup Complexity – It’s not beginner-friendly. You’ll need some technical skills to run and fine-tune it properly.
2. Limited Support – Unlike GPT, there’s no dedicated customer support or built-in platform; most help comes from the open-source community.
3. Needs Fine-Tuning – Out of the box, it might not be as fluent or polished as GPT, especially for casual or creative tasks.

Pros and Cons of GPT
GPT is a well-liked option in the field of AI language models. However, when comparing Meta Llama vs Open AI GPT, it’s clear that both have their pros and drawbacks. Let’s examine a few of them.
- Highly accurate and fluent responses: GPT gives human-like replies and understands context really well, making it great for writing, chatting, and problem-solving.
- Versatile use cases: From drafting emails to writing code, creating content, or tutoring, GPT can do a lot; it’s like having a smart assistant on call.
- Continually improving: With regular updates and fine-tuning, GPT keeps getting better at understanding and generating text.
- Easy to integrate: Businesses can plug it into websites, apps, or customer service systems using OpenAI’s API, with minimal setup.
Cons of GPT:
- It’s not perfect: Sometimes GPT gives incorrect or biased answers. You still need to double-check the output, especially in sensitive use cases.
- Can be expensive: Using the more advanced versions like GPT-4 on a regular basis can add up, especially for startups or solo users.
- Lack of transparency: Since GPT is closed-source, you don’t fully know how it was trained or what data it was exposed to.
- Resource-intensive: Larger models require strong infrastructure to run efficiently, so not always ideal for on-device or low-power environments.
Future of AI-Language Models: What to Expect?
We could see them becoming even more human-like, not just in how they write, but in how they understand context, emotions, and intent. These models might soon bring real-time language translation with near-perfect accuracy or help students learn in ways that feel tailor-made.
We would likely see smaller, faster models that run on phones or laptops, making powerful AI tools more accessible. Privacy and ethics could also become a bigger focus, with AI models being designed to explain how they make complex topics simpler.
We might even witness more collaboration between humans and AI, where writers, designers, and coders work alongside AI as creative partners, often supported by an AI development company. In short, language models could go from being just tools to becoming everyday collaborators, bringing more value to both personal and professional lives. And honestly, we’re only scratching the surface of what’s possible.

Conclusion
Choosing between Llama and GPT comes down to your needs. If you’re looking for a ready-to-use, polished tool with strong support and broad capabilities, GPT is a solid choice.
But if you prefer more control, customization, and a cost-effective open-source model, Llama could be a better fit. Both have their strengths; GPT shines in performance and ease of use, while Llama offers flexibility and freedom.
As AI continues to grow, we’ll likely see both models grow in their ways, giving users more options than ever before. So, it’s really about what works best for your setup.
SoluLab, a leading LLM development company in the USA, can help you create such AI tools and help your business scale faster. Contact us today to discuss further!
FAQs
1. Can Llama and GPT be used together in AI applications?
Llama and GPT can be combined in hybrid AI systems. You can use Llama for local processing and GPT for advanced tasks, balancing the strengths of Open-Source AI vs. Closed-Source AI models.
2. What are the primary differences between Llama and GPT?
Llama is part of open source AI development and offers customization and local deployment, while GPT is one of the most advanced OpenAI models, available through a paid API with limited access to internal workings.
3. What are the security risks of using AI language models?
Both Llama and GPT carry risks like data leakage, biased outputs, or misuse. Open-source AI development tools require secure implementation, while closed-source models depend on the provider’s privacy and data-handling practices.
4. Can I customize Llama and GPT models?
Llama supports full customization, making it ideal for developers using open-source AI development tools. GPT, being a closed-source product, allows limited fine-tuning depending on OpenAI’s access policies and plans.
5. How do the access models impact the choice between Llama and GPT?
In the Open-Source AI vs. Closed-Source AI debate, access plays a big role. Llama offers full control through open-source AI development, while GPT provides convenience and performance through managed OpenAI models.
