
The GPT (Generative Pre-trained Transformer) model has transformed natural language processing (NLP) by exhibiting an extraordinary ability to generate human-like text. Its capacity to comprehend and provide logical and contextually appropriate replies has made it a popular tool for a wide range of applications, like chatbots, content production, language translation, and more. Though pre-trained versions of GPT are available, creating your own GPT model can give distinct benefits and customization choices customized to your individual requirements.
Developing a GPT model involves meticulous planning, domain-specific data, and computing resources. In this blog, we will walk you through how to make your own GPT model while also giving practical guidance and observations.
By adhering to the guidelines described in this blog, you may unleash the power of GPT and leverage its possibilities for your unique needs. Whether you’re an AI enthusiast, dedicated developer, or researcher, this step-by-step guide will provide you with the information and resources you need to learn how to create a GPT model.
Now, let’s look at GPT’s components and advantages!
Overview of the GPT Model and Its Components
A GPT (Generative Pre-trained Transformer) model is a modern natural language processing (NLP) model that has received widespread attention and praise in recent years. GPT models, created by OpenAI and centered on the Transformer architecture, have shown tremendous advances in language creation and comprehension tasks.
A GPT model includes two main components: a pre-training phase and a fine-tuning phase.
1. Pre-training Phase
With pre-training, the GPT model is trained on a large amount of unlabeled text data. Such an unsupervised learning approach entails teaching the model to anticipate missing words in phrases, which allows the model to obtain a thorough knowledge of language structures, information, and semantics. The pre-training step involves a large-scale language modeling work that allows the model to grasp the complexities of human language. To create your own ChatGPT, this foundational understanding is crucial, as it equips the model with the necessary linguistic knowledge before fine-tuning.
2. Fine-tuning Phase
Following pre-training, the GPT model goes through a fine-tuning step with labeled or domain-specific data. This supervised learning method enables the model to adjust to particular tasks or domains, such as text categorization, sentiment analysis, chatbot interactions, or content creation. Fine-tuning enables the GPT model to execute certain tasks with greater accuracy and relevance. To understand how to train GPT, it is essential to recognize the role of attention methods, which let the model focus on key areas of the input text while successfully capturing long-term relationships. With its multi-head self-attention system, the Transformer architecture enables GPT models to perform large-context tasks while producing coherent and contextually relevant replies.
Advantages of Using GPT Models
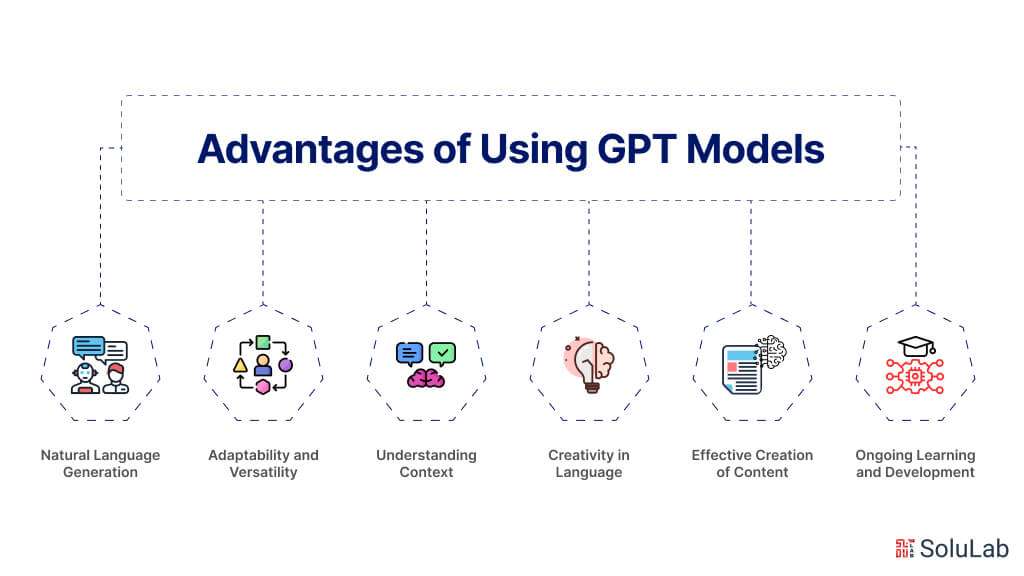
GPT (Generative Pre-trained Transformer) models have several advantages, revolutionizing the industry of natural language processing (NLP) and improving the quality and efficiency of language-generating jobs. Let’s look at some of the primary advantages of adopting GPT models:
- Natural Language Generation
GPT models specialize in producing human-like language, making them useful for applications like chatbots, content production, and creative writing. Knowing the context and semantics of the input text allows GPT models to create coherent and contextually appropriate replies, hence improving the entire user experience. Understanding how to train your own GPT ensures these models are tailored to specific tasks, enhancing their effectiveness in various applications.
- Adaptability and Versatility
GPT models may be optimized for particular tasks and domains, making them incredibly flexible and adaptive. Due to its adaptability, GPT models may be used for a variety of natural language processing (NLP) applications, such as sentiment analysis, text categorization, language translation, and more, by academics and developers.
- Understanding Context
Because GPT models are pre-trained on large volumes of unlabeled data, they have a firm grasp of contextual comprehension. Contextual knowledge enables the models to provide replies that are appropriate for the given context and grasp linguistic subtleties, leading to more meaningful and accurate outputs. To fully understand this, one might even explore how to code GPT from scratch, delving into the intricacies of training and fine-tuning such powerful language models.
- Creativity in Language
Generative and original text may be produced using GPT models. GPT models are helpful in creative writing assignments and content generation due to their vast pre-training exposure to a variety of language patterns and structures, which allows them to produce original and creative replies.
- Effective Creation of Content
Automating content development processes can be facilitated by GPT models. To train your own GPT, you can leverage its language production skills to produce high-quality, relevant, and captivating content for various channels, such as product descriptions, articles, social media posts, and more. This effectiveness can preserve the coherence and integrity of the created information while saving time and money.
- Ongoing Learning and Development
As fresh labeled data becomes available, GPT models may be updated and further refined. The models’ ability to adjust to changing linguistic patterns and stay current with emerging trends and situations is made possible by this ongoing process of learning and development, which guarantees the models’ relevance and precision over time. Understanding how to train GPT is crucial to ensuring these models maintain high performance and adaptability.
Use Cases of GPT Models
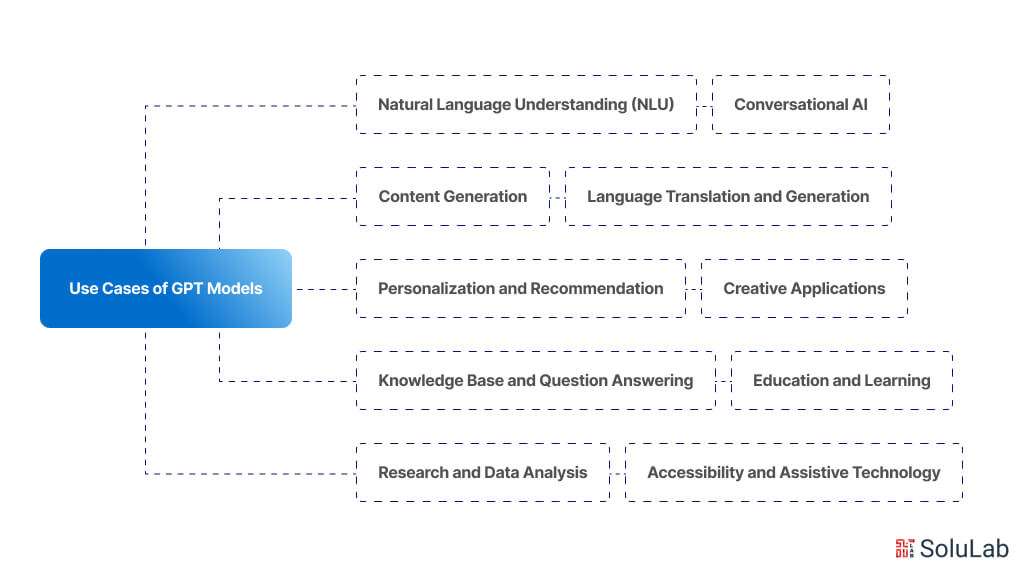
GPT (Generative Pre-trained Transformer) models have a wide range of use cases across various industries and domains. Here are some pointers on potential use cases:
1. Natural Language Understanding (NLU):
- Text summarization: GPT models can summarize long documents or articles into concise summaries.
- Sentiment analysis: Analyzing the sentiment of text data, such as social media posts or customer reviews.
- Named Entity Recognition (NER): Identifying and classifying entities mentioned in the text, such as names of people, organizations, or locations.
2. Conversational AI:
- Chatbots: Creating intelligent AI-powered chatbots capable of engaging in natural conversations with users.
- Virtual assistants: Building virtual assistants that can perform tasks, answer questions, and provide assistance through text or voice interactions.
3. Content Generation:
- Article writing: Generating articles, blog posts, or news stories on various topics.
- Creative writing: Producing creative content such as poems, stories, or dialogues.
- Code generation: Writing code snippets or scripts based on specific requirements or tasks.
4. Language Translation and Generation:
- Language translation: Translating text between different languages with high accuracy.
- Language generation: Generating text in multiple languages for tasks like multilingual content creation or localization.
5. Personalization and Recommendation:
- Personalized content recommendation: Recommending articles, products, or media based on user preferences and behavior.
- Personalized marketing: Creating personalized marketing messages or campaigns tailored to individual customers.
6. Knowledge Base and Question Answering:
- Question answering: Providing accurate and relevant answers to questions posed in natural language.
- Knowledge base completion: Filling in missing information or completing incomplete sentences in a knowledge base.
7. Education and Learning:
- Automated tutoring: Assisting students with learning by providing explanations, answering questions, and generating practice exercises.
- Content generation for educational resources: Generating educational materials such as quizzes, worksheets, or lesson plans.
8. Creative Applications:
- Art and music generation: Creating artwork, music compositions, or other creative works based on input prompts.
- Storytelling and narrative generation: Generating story plots, characters, and dialogues for storytelling applications.
9. Research and Data Analysis:
- Data synthesis: Generating synthetic data for research purposes or augmenting existing datasets.
- Text analysis: Analyzing large volumes of text data to extract insights, trends, or patterns.
10. Accessibility and Assistive Technology:
- Text-to-speech synthesis: Converting text into natural-sounding speech for users with visual impairments or reading difficulties.
- Speech-to-text transcription: Converting spoken language into text, enabling accessibility for users who prefer speech input.
GPTs Distinctive Functionalities and Integration
To get the most out of GPT you can make use of its sophisticated functionalities such as integrating external APIs. You may access this feature in your GPT preferences settings by selecting the “Actions” tab from the “Configure” menu. You may greatly increase your GPT functionality above static conversational responses by linking it to external APIs. You can increase the dynamic adaptability of your GPT in the following ways:
1. Obtaining Real-Time Data
Your GPT can obtain current information from outside sources by integrating with APIs. It is a trustworthy source of real-time insights since it can pull the most recent news, stock market movements, and live weather updates for instance.
2. Using Other Software
To set up meetings, send reminders, or update tasks automatically, your GPT can integrate with platforms and applications such as Google Calendar, project management software, and Slack. Workflows are streamlined and productivity is increased by this integration.
3. Custom Applications
API connections make it possible for companies or developers to create GPT-powered custom applications. For example, by connecting with the store’s inventory API, an AI chatbot for e-commerce that sells products can offer tailored suggestions.
Related: Llama Vs. GPT
Custom GPT’s Privacy, Security, and Compliance
Although custom GPTs are very sophisticated, there are risks involved. When making and utilizing them, it’s critical to consider appropriate usage and privacy.
A. Maintaining Safety and Privacy
Privacy and security must be given top priority when developing a GPT. Put safeguards in place to protect user data, make sure that interactions with the GPT are secure, and continuously check on its functionality to avoid any unexpected outputs and interactions.
B. Observance of Usage Guidelines
Recreating OpenAI’s usage guidelines is a must, these rules guarantee that your application of GPT technology is morally righteous, compliant with the law, and consistent with the usefulness of these potent instruments. Learn about these guidelines to make sure your personalized GPT stays inside them.
Requirements to Build Your Own GPT Model
Prior to starting the process of creating a GPT (Generative Pre-trained Transformer) model, a few requirements must be met. These requirements guarantee an efficient and fruitful procedure. The following are some necessary preconditions to think about to make your own GPT:
- Domain-specific Information
Gather or choose a significant amount of domain-specific information relevant to the intended use or assignment. A GPT model must be trained on a varied and pertinent dataset to yield accurate and contextually relevant results.
- Computing Capabilities
Significant computing resources are needed to build a GPT model, especially regarding memory and processing capacity. To manage the computational needs of training and optimize the model, make sure you have access to a strong computer infrastructure or think about using cloud-based solutions.
- Preparing Data
Make sure the dataset is ready by carrying out the required preparatory operations, such as cleaning, tokenization, and encoding. This guarantees that the format of the data is appropriate for GPT model training. Understanding how to train GPT involves these crucial steps to ensure the model performs optimally.

- Framework for Training
Select an appropriate deep learning framework, like PyTorch or TensorFlow, to make the GPT model’s setup and training easier. To make the most of the features of the selected framework, please become familiar with its documentation and APIs. This familiarity is essential when you aim to create your own GPT model.
- GPU Intensification
Make use of GPU acceleration to make training go more quickly. Due to their large-scale design, GPT models notably benefit from GPUs’ parallel processing, which drastically shortens training durations. To effectively train GPT models, leveraging GPU acceleration is essential for handling the extensive computational demands.
- Optimizing Fine-tuning Approach
Establish a fine-tuning plan to modify the trained GPT model to fit your particular domain or activity. Choose the right dataset for fine-tuning and decide the parameters and hyperparameters to adjust in order to get the best results.
- Metrics for Evaluation
Choose evaluation metrics that are acceptable and in line with your GPT model’s intended performance objectives. Perplexity, BLEU score, and bespoke domain-specific metrics are examples of common metrics that assess the coherence and quality of the output text. These metrics are crucial when you create own GPT model to ensure it meets the desired standards and effectively serves its intended purpose.
- Proficiency in Deep Learning
Gain a thorough knowledge of the principles of AI deep learning, particularly as they pertain to transformer architectures, attention processes, and sequence-to-sequence models. To efficiently construct and fine-tune GPT models, please become aware of the underlying ideas. This foundational understanding is crucial when you aim to create your own GPT model.
- Proficiency in Deep Learning
Gain a thorough knowledge of the principles of deep learning, particularly as they pertain to transformer architectures, attention processes, and sequence-to-sequence models. To efficiently construct and fine-tune GPT models, please become aware of the underlying ideas.
- Version Control and Monitoring of Experiments
For handling iterations, monitoring modifications, and keeping track of configurations, hyperparameters, and experimental outcomes, put in place a version control system and study tracking mechanism.
- Iteration and Patience
A top-notch GPT model needs to be developed gradually and through iterations. To get the required performance, try out various architectures, hyperparameters, and training approaches. To maximize the model’s effectiveness, ongoing testing, assessment, and improvement are essential. Consistently refining these elements is key to successfully train GPT models.
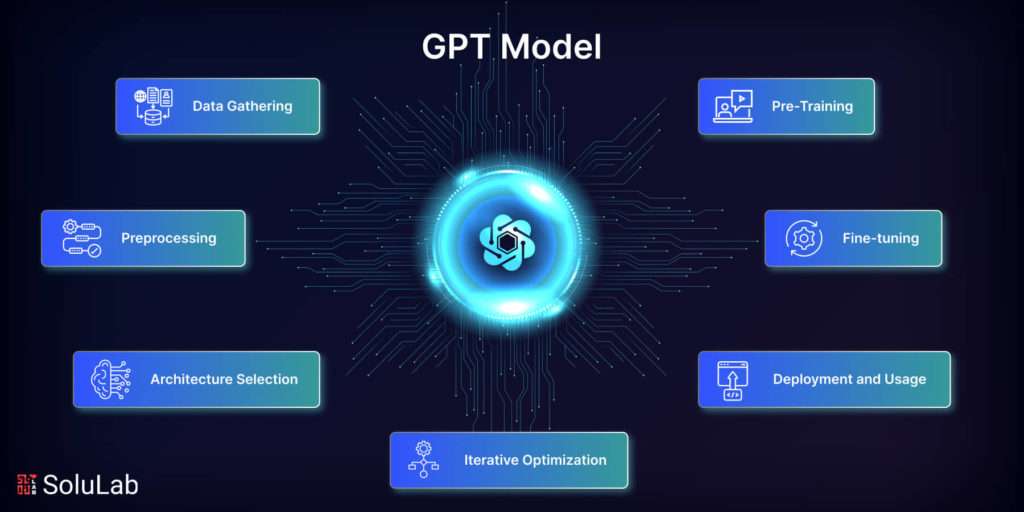
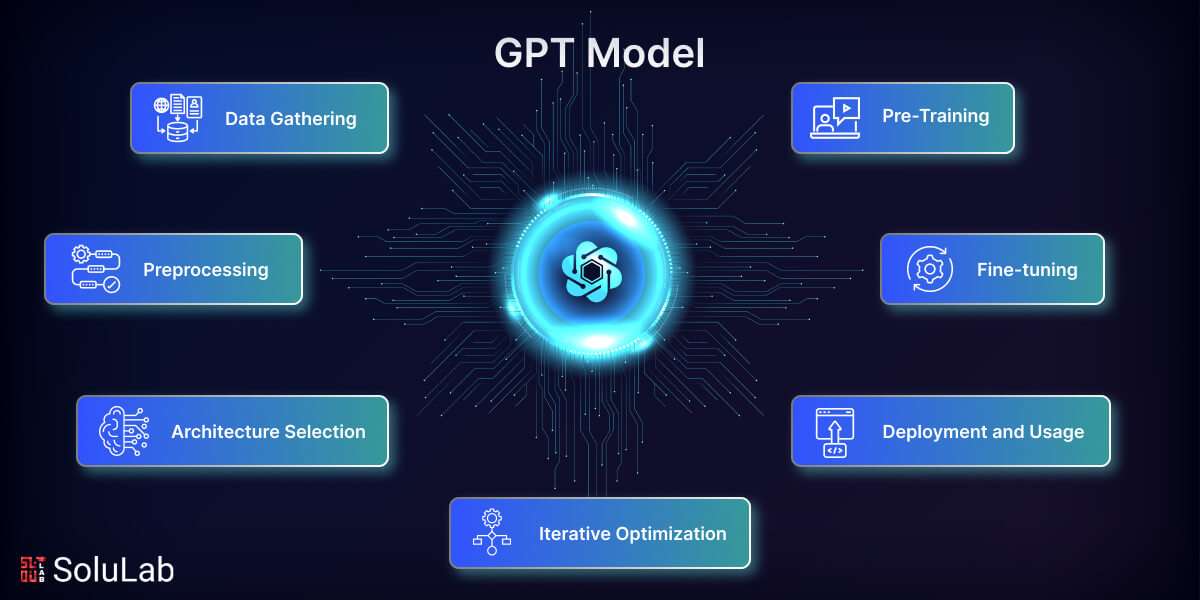
How to Create a GPT Model?
A set of procedures that include data collecting, preprocessing, architecture selection, pre-training, fine-tuning, iterative optimization, and deployment are needed to create a GPT (Generative Pre-trained Transformer) model. Now let’s examine each of these actions in more depth:
1. Data Gathering
Gathering or selecting a sizable corpus of text data pertinent to the target topic or activity is the first stage in creating a GPT model. To create your own GPT, the dataset ought to be representative and varied to guarantee that the model picks up on a wide variety of linguistic patterns and situations.
2. Preprocessing
Preprocessing is done after the dataset is gathered to clean it up and put it in a manner that is appropriate for training. Preprocessing usually includes encoding the data for the model’s input, managing punctuation, representing the text into individual words or subwords, and eliminating noise. This step is crucial when preparing to create your own GPT model, ensuring the dataset is optimized for effective training and model performance.
3. Architecture Selection
Selecting the right architecture is essential to creating a GPT model that works. The Transformer architecture is frequently used for GPT models because of its capacity to efficiently collect long-range relationships and contextual information thanks to its mechanism for attention and self-attention layers.
4. Pre-Training
Pre-training is an important stage in which a sizable corpus of unlabeled text data is used to train the GPT model. As the model gains knowledge of language structures, context, and semantics, it is able to anticipate missing words or tokens in phrases. Unsupervised learning methods, like the masked language modeling target, are commonly used for pre-training. For those interested in a deeper understanding, learning how to code GPT from scratch can provide valuable insights into the underlying mechanisms of training and fine-tuning such models.
5. Fine-tuning
The GPT model is refined using a smaller dataset that is tagged or tailored to the intended task or topic following pre-training. By fine-tuning, the model’s performance and relevance are increased since it may adjust its knowledge to the intended job. In order to fine-tune the model, supervised learning techniques are used to train GPT, sometimes with a task-specific goal or loss function.
6. Iterative Optimization
To build your own GPT requires trial and iteration. To maximize the model’s performance, a range of hyperparameters, architectures, and training approaches are investigated and improved. Evaluation metrics are utilized to evaluate and contrast various model iterations, which include task-specific metrics or perplexity metrics.
7. Deployment and Usage
The GPT model may be applied in real-world scenarios after it has been trained and refined. In order to enable users to engage with the language-generating capabilities of the model, deployment entails integrating the model into the intended system or platform. Depending on the particular activity it was trained for, the deployed model might produce outputs, recommendations, or reactions.
Key Considerations for Building a GPT Model
To improve a GPT (Generative Pre-trained Transformer) model’s performance, minimize any problems, and guarantee ethical and efficient language production, a number of crucial factors must be carefully taken into account. The following are some important things to remember when you want to learn how to create a GPT model:
1. Eliminating Bias and Toxicity
Two important issues with language generation models are bias and toxicity. To stop the model from sustaining or enhancing negative biases, take action to detect and reduce biases in the training set. To address prejudice, use strategies like varied training data, debiasing algorithms, and fine-tuning with fairness objectives. Use content moderation and filtering techniques as well to lessen the production of offensive or dangerous information. Addressing these challenges is crucial when you aim to train your own GPT, ensuring ethical and safe deployment of the model in various applications.
2. Improving Hallucination
Situations where the model produces false or fictitious information are referred to as hallucinations. Using external knowledge bases or fact repositories to validate produced information, adding fact-checking procedures, and training the GPT model on reputable and high-quality data sources are all necessary to address hallucinations. Enhancing the accuracy of the model and lowering hallucinations can be accomplished by iterative refining and ongoing assessment. These steps are critical when you aim to create your own GPT model, ensuring the reliability and trustworthiness of the generated content.
3. Stopping Data Exfiltration
When the GPT model accidentally remembers and repeats portions of the training data, it might cause data leakage and unwittingly reveal private or sensitive information. To reduce the chance of data leakage and protect privacy, use strategies such as token masking during pre-training, cautious dataset selection, and data sanitization. These practices are crucial when you aim to create your own ChatGPT, ensuring data security and privacy are maintained throughout the model’s development and deployment.
4. Including Queries and Actions
Take into consideration include actions and queries in the language generation process in order to render GPT models more task-oriented and interactive. This entails changing the architecture of the model or adding new input methods that let users give precise commands or prompts, directing the generated replies in the direction of desired results. Build your own GPT model that can comprehend user requests and activities and react to them appropriately.
How to Build Your Own GPT App?
Building your own GPT (Generative Pre-trained Transformer) app involves several steps and considerations. Here are some pointers to get you started on how to make your own GPT app:
- Define the Use Case: Determine the purpose of your GPT app. Are you creating a chatbot, a content generator, a writing assistant, or something else? Your development approach will be guided by your understanding of the particular use case.
- Choose a Framework or Platform: Decide whether you want to build your app from scratch using deep learning frameworks like TensorFlow or PyTorch, or if you prefer to use existing platforms like Hugging Face’s Transformers library or OpenAI’s API. Using existing platforms can simplify development, but building from scratch offers more customization.
- Data Collection and Preprocessing: Gather and preprocess the data relevant to your use case. If you’re building a chatbot, you might need conversational data. For a content generator, you might need text from various sources. Ensure that your data is cleaned and formatted properly before training.
- Model Selection and Training: Choose the appropriate GPT model for your application. GPT-2 and GPT-3 are popular choices, but there are also smaller variants like GPT-2 small or DistilGPT for resource-constrained environments. Train your model on the collected and preprocessed data until it achieves satisfactory performance.
- Integration: Integrate the trained model into your app’s backend. This involves setting up APIs or libraries to interact with the model. Ensure that your app can send inputs to the model and receive outputs effectively.
- User Interface Design: Design the user interface (UI) of your app. Consider how users will interact with the GPT model—will it be through a text-based interface, voice commands, or something else? Create an intuitive and user-friendly UI to enhance the user experience. This step is crucial when you aim to create your own ChatGPT, ensuring seamless interaction between users and the model.
- Testing and Evaluation: Test your app thoroughly to identify and fix any bugs or issues. Evaluate the performance of your GPT model in real-world scenarios to ensure it generates accurate and relevant responses.
- Deployment: Deploy your app to your chosen platform or hosting service. Make sure it’s accessible to your target audience and can handle expected levels of traffic and usage.
- Feedback and Iteration: Gather feedback from users and stakeholders to continuously improve your app. Iterate on the design, functionality, and performance of both the app and the underlying GPT model based on this feedback.
- Ethical and Legal Considerations: Consider the ethical implications of deploying a GPT-powered app, such as bias in the training data or misuse of generated content. Ensure compliance with relevant laws and regulations, especially regarding data privacy and intellectual property rights.

Final Words
We have looked at building a personalized GPT (Generative Pre-trained Transformer) model in this extensive guide. From data collection to preprocessing, architectural selection, pre-training, fine-tuning, and iterative optimization, we have thoroughly examined every stage. We spoke about things like eliminating toxicity and prejudice, enhancing hallucinations, stopping data leaks, and adding queries and actions. By adhering to these guidelines and utilizing the capabilities of GPT models, you may start an interesting language creation adventure. Create a GPT model that can produce language that is responsible, contextually relevant, and natural for a range of uses. It is important to consistently assess and improve your model to guarantee its efficacy, minimize prejudices, and conform to moral principles.
SoluLab offers comprehensive expertise and support in building your own GPT (Generative Pre-trained Transformer) model, tailored to your specific requirements and use cases. With a team of skilled AI engineers and developers, SoluLab provides end-to-end solutions, from data collection and preprocessing to model selection, training, and deployment. Leveraging cutting-edge technologies and industry best practices, SoluLab ensures the development of highly accurate and efficient GPT models that meet your business needs. Whether you’re looking to create a chatbot, content generator, or conversational AI solution, SoluLab’s dedicated team will work closely with you to deliver customized, scalable, and reliable solutions. Contact us today to discuss your project and discover how SoluLab can empower your business with advanced AI capabilities.
FAQs
Shipra Garg is a tech-focused content strategist and copywriter specializing in Web3, blockchain, and artificial intelligence. She has worked with startups and enterprise teams to craft high-conversion content that bridges deep tech with business impact. Her work translates complex innovations into clear, credible, and engaging narratives that drive growth and build trust in emerging tech markets.


