
Artificial intelligence (AI) has advanced significantly in recent years. Multimodal AI is one of the most recent innovations. Multimodal AI produces more accurate results than standard AI because it can handle numerous data inputs (modalities).
Like us, Multimodal AI can see, hear, read, and interpret across different data types. From smarter chatbots to mind-blowing video generation tools, this tech is already changing the game.
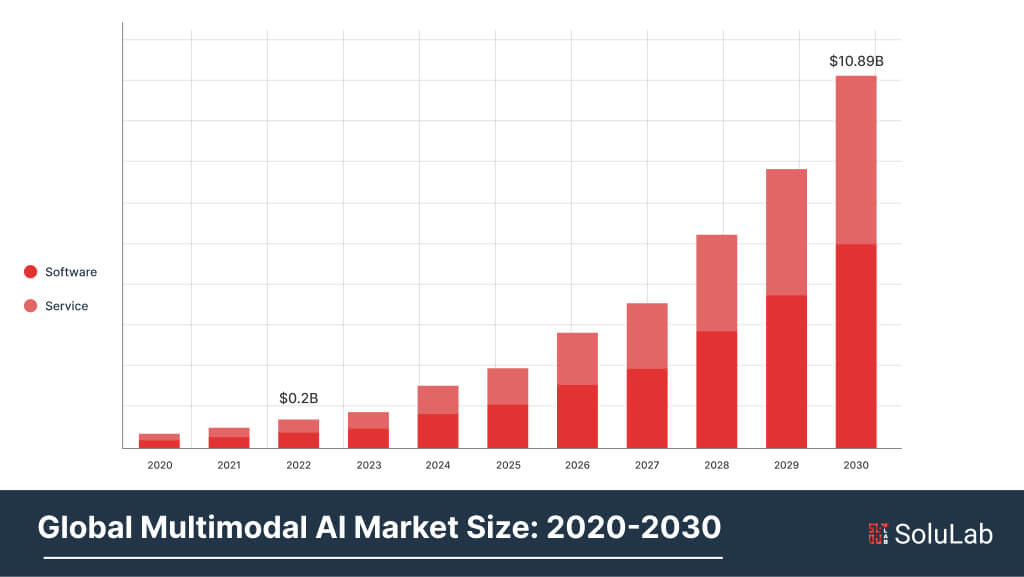
The global multimodal AI market size is expected to reach USD 27 billion by 2034, growing at a CAGR of 32.7%
In this guide, we’ll break it all down in simple terms — what it is, how it works, and why it matters.
What is MultiModal AI?
Artificial intelligence that can analyze and comprehend several data kinds, such as text, images, audio, and video, at the same time is known as multimodal AI. By combining input from multiple sources, multimodal AI provides a more thorough and nuanced understanding than typical AI models that use only one sort of data.
Virtual assistants like Google Assistant and Amazon’s Alexa are the best examples of multimodal AI. This assistive technology can deliver text-based responses (text modality), visual responses (visual modality), and vocal responses (audio modality) to requests.
These virtual assistants handle data from several modalities and perform tasks like notifying customers and controlling smart home equipment to provide a seamless and easy experience for customers.
What Makes Multimodal AI Different Than Unimodal AI?
Based on the data it analyzes, artificial intelligence (AI) can be divided into two main categories:
- Unimodal AI
- Multimodal AI.
In these occurrences, Unimodal AI can devote itself to some tasks related to the given modality and can confine itself to a single form of data such as text, image as well as voice. The last level of AI systems is the multimodal AI systems that come in and take inputs from different sources and analyze them to generate more complicated and sophisticated outputs based on the efficiency of each modality. The advantages of unimodal and multimodal AI and the different types of applications that each of them requires are presented in the table below:
| Aspect | MultiModal AI | UniModal AI |
| Meaning | AI is capable of combining and analyzing multiple data kinds. | AI that is only capable of processing a single data type. |
| Sources of Data | Combines different modalities be it text, graphics, audio, and video. | Restricted to a single type of data modality be it text, picture, audio, etc. |
| Difficulty | More intricate, and requires the synchronization and integration of several data formats. | Generally easier, and more task-oriented. |
| Feature Extraction | Extraction of characteristics to improve understanding of data of different kinds. | One data type feature can be extracted |
| Applications | Applied to tasks like visual question answering, video analysis, and picture captioning. | Applied to tasks like image classification, speech recognition, and sentiment analysis. |
| Performance | Have the capability to manage multiple contextual tasks. | Exceptional proficiency in particular tasks. |
| Training | For efficient training, a varied dataset is required with various modalities. | Needs a focused dataset to be used with a single modality |
| Interpretation | Difficult to understand because of the combination of several data sources. | Due to the availability of only one kind of data, this is easier to understand. |
| User Experience | Provides more interacting modes that allow interaction with different inputs. | Restricts some types of interaction like text input for NLP. |
| Scalability | More difficult to grow because different data sources and interactions are required. | Can be scaled more easily within a particular domain. |
How Does MultiModal AI Work?
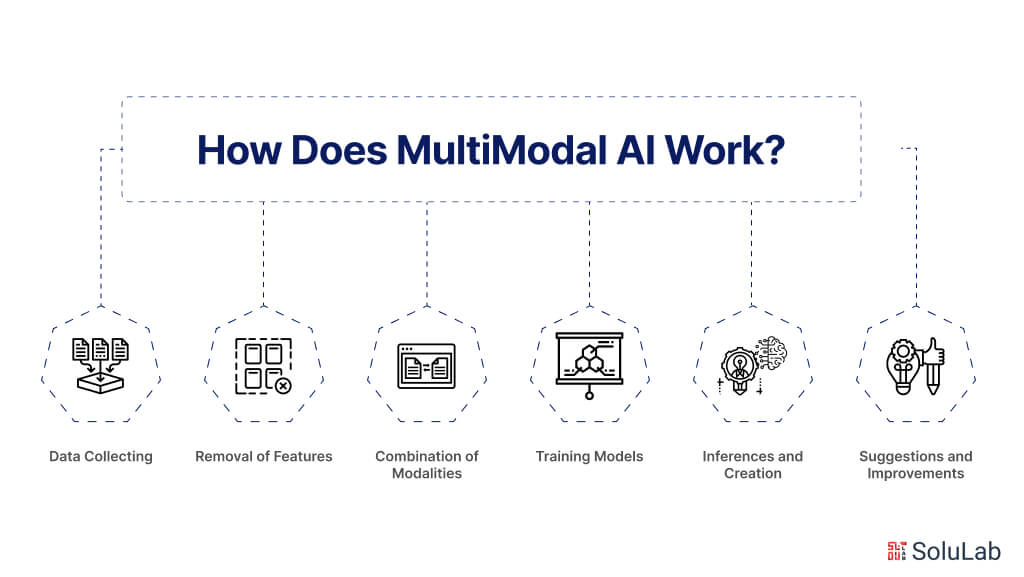
Here is a breakdown of how does multimodal AI works:
Data Collecting
Multimodal AI systems are known for gathering data from files imported like texts, images, and audio among many other sources. Once data is gathered, it is processed for application to heterogeneous data to make it tidy and prepared for further interaction. This step also plays a major role in removing inaccurate data that could hamper AI’s effectiveness.
Removal of Features
Once the data is gathered and processed, AI will the modality of each data for extracting the relevant data. For example, textual data is processed with the use of Natural Language Processing techniques, while on the other hand visual data is investigated using computer vision. To comprehend the qualities of every kind of data this model is significant.
Combination of Modalities
The obtained features from various modalities are integrated with the multimodal AI architecture which is used for creating a holistic understanding of the input. This fusion of modalities is made possible using a variety of methods like early fusion and late fusion. With this integration, the model can take advantage of each modality’s potential to perform better overall.
Training Models
A sizable and varied dataset which includes examples from all relevant sources is used to train an AI model. The capacity of a model to reliably understand and correlate data from diverse sources is improved in the training period, which in a way provides strength to the model.
Inferences and Creation
When the models are trained, the multimodal model can carry them out inference, which entails making predictions or coming up with solutions in the light of unobserved data. For instance, it might adapt spoken words in a movie, describe, and respond to the user’s specific requests with relevant information.
Suggestions and Improvements
Multimodal AI apps get better at interpreting and absorbing multimodal input through ongoing feedback and extra training. The systems can develop and improve their potential through this continuous process, which eventually produces outputs that are even more accurate and predictive.

Top 7 MultiModal Real-Life Use Cases
Multimodal can change and is already transforming industries with the combination of several data types for improving customer experiences, simplification of operations, and creating new growth opportunities. Here are the top 7 multimodal AI use cases:
Retail
Multimodal AI in the retail sector speeds up efficiency with the blend of data from cameras, transaction records, and RFID tags. This integration can help with the management of inventory which also aids in predicting demands more accurately and providing customer-specific promotions for a much smoother supply chain workflow and higher customer satisfaction.
HealthCare
For healthcare, Multimodal AI works on merging the data from electric health records, medical imaging, and patient reports to improve diagnosis, treatments, and tailored care. This method has proven enhanced accuracy and efficiency with the help of various data. With source integration, patterns ought to be uncovered for diagnosis for precise outcomes.
Read Blog: Generative AI in Healthcare
Finance
Multimodal AI examples can boost risk management and fraud detection by merging numerous data such as user activity, transaction logs, patterns, and past financial records. This will enable a more detailed analysis, for a precise detection of potential fraud and threats for risk assessment.
Related: AI in Finance
eCommerce
Present dynamics have unfolded the world of online shopping to another extent, in which multimodal with any failure have shown changes by keeping the customers satisfied with the help of interactions, product visuals, and feedback to keep adapting to customer demands. When varied data is analyzed well, it helps with precise suggestions, optimizing product displays, and enhancing overall user experience.
Social Media
For social media, multimodal AI has changed the scene completely by blending different data from different places like images, texts, and videos that not only boost user interactions but also handle the content. Once the data of each kind is properly examined, the AI system can better understand the sentiments, user emotions, trends, recent and past behaviors, etc.
Agriculture
Multimodal AI is not what crosses your mind when you hear agriculture, but it plays a major role in this sector as well. In the farming sector, AI can enhance crop management and agricultural efficiency with the combination of data using satellite images, on-field sensors, and predicting the weather. It can also help with crop health monitoring and even effective water and nutrient control.
Manufacturing
Multimodal AI in the manufacturing sector optimizes production with the potential of merging data from machine sensors production line cameras, and keeping a check on quality control. This method not alone helps with the improvement of maintenance but also with overall production effectiveness.
Key Benefits of MultiModal AI
Multimodal AI offers a wide range of benefits that enhance efficiency, productivity, precision, flexibility, and much more for all kinds of applications which would eventually lead to accurate results, informed decisions, and efficient solutions. Here are a few major benefits you should know about:
1. Flexibility in Reality
By blending data from different sources, multimodal AI can manage a broader range of real-world applications effectively and is more adaptable to cater to various scenarios. As a result, this will make it easier for multimodal AI to excel in diverse situations for provide an even more versatile solution to complex tasks.
2. Stronger Performance
The merge of multiple modalities has made the multimodal AI more equipped while handling complex tasks which leads to dependable and versatile AI solutions, this enhanced capability has also improved performance by showcasing the strengths of AI.
3. Through Comprehension
Multimodal AI systems combine various forms of data from different modalities, this would help provide an intricate and holistic view of the context or the problem that requires consideration. Using this approach AI can gain a deep understanding of situations and problems.
4. Improved Precision
Multimodal AI can surpass single-modality systems in terms of accuracy. This model seems to provide a more precise data analysis and reduce errors with the help of integrated data of various forms such as texts, images, and audio.
5. Enhanced problem-solving
Multimodal artificial intelligence can handle more difficult tasks like evaluating multimedia information or identifying a medical problem since it can process a variety of inputs.
Read More: What Is Manus AI? How to Build a Similar AI Agent for Your Business
Top 3 Models of MultiModal AI in 2026
Multimodal AI, which combines text, graphics, video, and audio, has created intelligent and adaptable systems in 2026. This section discusses the top three multimodal AI models of the year, their breakthroughs, application cases, and capabilities.
1. Google Gemini 2.0
The multimodal LLM Google Gemini 2.0 processes and understands text, image, audio, and video input. Deep thinking, innovative content development, and multimodal perception are its strengths. Scalable and compatible with Google Cloud solutions, it works in enterprise applications. It can manage complicated workflows in healthcare, entertainment, and education due to its innovative design.
Key Features
- Advanced multimodal (pictures, text, audio, video).
- Precision in complex reasoning and creativity.
- Enterprise-scalable.
- Smooth Google Cloud integration.
2. xAI’s Grok 3
The flagship multimodal LLM from xAI, Grok 3, is designed for complex reasoning, problem-solving, and real-time data processing. Its text, image, and voice inputs make it suitable for financial analysis, autonomous systems, and real-time decision-making. Grok 3’s efficiency and scalability optimizations ensure high performance with large datasets.
Key Features:
- Text, image, audio rationale.
- Effectively handles huge datasets.
- Designed for fast-decision applications.
3. DeepSeek V3
DeepSeek V3 is a fast multimodal AI system for automation, research, and creativity. It accepts text, image, and voice inputs and works well in media, healthcare, and education. Advanced algorithms let it perform complex jobs including content development, data analysis, and predictive modeling.
Key Features
- Multimodal input (text, pictures, audio).
- High research and data analysis accuracy.
- Can be tailored to industrial needs.
- Scalable for mass deployments.
Future of Multimodal AI
Multimodal AI offers a new age of advanced AI capabilities. Multimodal AI integrates text, graphics, audio, and video to change how we use technology. Some incredible trends to watch:
1. Multimodal large-language models: Expand to handle text, video, and other mediums, enabling easier and flexible applications in education, healthcare, and entertainment.
2. Improved multimodal creativity systems: Sophisticated tools like text-to-video generators enable more efficient and precise content creation.
3. Real-time processing of multimodal inputs: Innovation in dynamic applications like virtual assistants, driverless vehicles, and interactive simulations is driven by real-time analysis and response.
As these advances continue, multimodal AI will change how we handle complicated problems and generate new opportunities in many sectors.

How Has SoluLab Helped Businesses AI Solutions as an AI Development Company?
Multimodal AI can be beneficial for businesses that need to create more quickly and intelligently. By delivering the most precise findings, it may completely change your operating capacity and customer experience.
Adopting this technology gives your business significance as chatbots and virtual assistants proliferate, in addition to opening doors to additional innovative solutions. This improved user experience and broadened AI applications across industries. Open-source models, AI infrastructure investment, and task-specific models are significant trends.
SoluLab an AI development company, can help you discuss your business challenges and come up with innovative solutions. Contact us today!
FAQs
Shipra Garg is a tech-focused content strategist and copywriter specializing in Web3, blockchain, and artificial intelligence. She has worked with startups and enterprise teams to craft high-conversion content that bridges deep tech with business impact. Her work translates complex innovations into clear, credible, and engaging narratives that drive growth and build trust in emerging tech markets.


