

Large language models like GPT-3 and BERT are developed with the help of transfer learning. It is a machine learning approach where a model that has been trained on one job is applied to another task that is different yet comparable. The theory underlying transfer learning is that a model may use the information it learns from solving one issue to help solve another.
One of the first applications of transfer learning was enhancing the capabilities of NLP-based models using pre-trained word embeddings, such as Word2Vec. Large pre-trained language models like BERT and GPT-3 have had a significant impact in the recent past, expanding the potential applications of transfer learning. One of the most often utilized techniques in transfer learning is fine-tuning. It entails training a pre-trained model using a smaller collection of task-specific labeled data in order to modify it for a certain task.
However, fine-tuning the whole model has become extremely costly and sometimes unfeasible due to the fact that huge language models include billions of parameters. As a result, in-context learning has gained more attention. In this method, the model receives reminders for a task and provides in-context updates. But it’s not always the best option due to inefficiencies like having to analyze the prompt each time the model predicts anything and occasionally performing terribly. This is where Parameter-efficient Fine-tuning (PEFT) is essential. Research by Houlsby et al. (2019) shows that Parameter-Efficient Fine-Tuning methods, such as adapters, can reduce the number of trainable parameters by up to 99% compared to traditional full fine-tuning methods while retaining competitive performance on various NLP tasks.
By focusing on a limited subset of the model’s parameters, PEFT can achieve performance that is equivalent to complete fine-tuning while using a substantially smaller amount of computing power. In this blog, we will discuss the PEFT approach along with its advantages and how it has developed into a productive tool for optimizing LLMs on downstream activities, despite common issues such as encountering the error no module named ‘PEFT’.
What is PEFT?
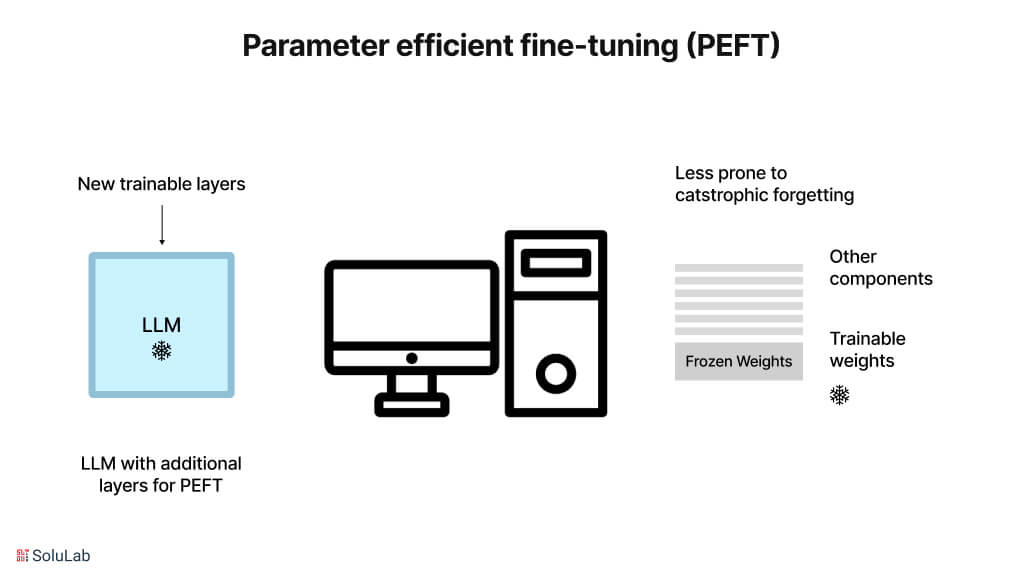
Parameter-efficient Fine-tuning (PEFT) is a natural language processing (NLP) approach that improves the efficiency of pre-trained language models on specified downstream tasks. It involves recycling the pre-trained model’s parameters and fine-tuning them with a smaller dataset, saving computing resources and time over training the complete model from scratch.
PEFT accomplishes this effectiveness by freezing portions of the pre-trained model’s layers and fine-tuning just the final few layers relevant to the downstream job. This approach allows the model to be modified to new tasks with minimal computational cost and fewer labeled instances.
Why is Parameter-efficient Fine-tuning Important?
Although PEFT is a relatively recent concept, upgrading the final layer of models has been used in the area of computer vision with the advent of transfer learning. Even in NLP, studies with static and non-static embedded words were conducted at an early stage. According to a study from Google Research, techniques like Low-Rank Adaptation (LoRA) and prefix-tuning can achieve over 95% of the performance of full fine-tuning with as little as 0.4% of the parameters being trained.
Parameter-efficient fine-tuning seeks to enhance the accuracy of pre-trained models, which include BERT and RoBERTa, on a variety of downstream tasks, involving sentiment analysis, named entity identification and question answering. It accomplishes this in low-resource environments with limited data and processing power. It merely changes a limited fraction of model parameters and is less susceptible to overfitting.
Difference Between Fine-Tuning and Parameter-Efficient Fine-Tuning
Fine-tuning and parameter-efficient fine-tuning (PEFT) are two methods used to enhance the performance of pre-trained models on specific tasks.
Fine-tuning involves taking a pre-trained model and further PEFT training it on new data for a new task. This process typically involves updating all the layers and parameters of the pre-trained model, which can be computationally expensive and time-consuming, especially for large models.
In contrast, parameter-efficient fine-tuning (PEFT) focuses on training only a select subset of the model’s parameters. This approach leverages adaptive budget allocation for parameter-efficient fine-tuning, which identifies the most critical parameters for the new task and updates only those. By concentrating on the essential parameters, PEFT significantly reduces the computational cost and time required for fine-tuning.
Parameter-efficient Fine-tuning vs. Standard Fine-tuning
| Parameter-efficient Fine-tuning | Standard Fine-tuning |
| Goal | Enhance the performance of a pre-trained model on a specific task with limited data and computational resources. |
| Training Data | Utilizes a small dataset (fewer examples). |
| Training Time | Faster training time compared to fine-tuning. |
| Computational Resources | Requires fewer computational resources. |
| Model Parameters | Updates only a small subset of the model’s parameters. |
| Overfitting | Less prone to overfitting as the model undergoes fewer modifications. |
| Training Performance | Performance is good, though typically not as high as with full fine-tuning. |
| Use Cases | Ideal for low-resource settings or situations where large training datasets are not available. |
Benefits of PEFT
In this context, the benefits of PEFT over conventional fine-tuning will be explored. Let’s examine the advantages of parameter-efficient fine-tuning as opposed to fine-tuning.
- Reduced Computational and Storage Costs
PEFT considerably lowers computational and storage costs by only requiring minor adjustments to a limited number of additional model parameters while freezing the majority of the pre-trained LLMs’ parameters.
- Resolving Catastrophic Forgetting
When PEFT LLM is fully fine-tuned, there is a chance that the model will forget what it learned during pretraining. PEFT can get around this problem by changing a small number of settings.
- Superior Performance in Low-data Regimes
Research has demonstrated that PEFT techniques outperform complete fine-tuning in low-data regimes and more effectively adapt to circumstances outside of the domain.
- Portability
Unlike the enormous checkpoints of complete fine-tuning, users of PEFT techniques can acquire small checkpoints worth a few MBs. Because of this, it is simple to deploy and use the trained weights from PEFT techniques for a variety of applications without having to replace the entire model.
- Performance Equivalent to Complete Fine-tuning
PEFT allows for the achievement of full fine-tuning performance with a minimal number of trainable parameters.
Few-shot Learning in Context (ICL) vs Parameter-efficient Fine-tuning (PEFT)
Methods for training natural language processing models include parameter-efficient fine-tuning and few-shot in-context learning. Though the methodologies used in both systems are technically different, they both allow large language models already taught to perform new tasks without requiring further training. The first method, called ICL, does not need gradient-based training; instead, it enables the model to execute a new job by entering prompted samples. ICL does, however, come at a high expense in terms of memory, processing power, and storage. The second method, called PEFT fine tuning, trains a model to do a new job with few modifications by adding or choosing a few additional parameters.
ICL is a method that incorporates contextual information during fine-tuning in order to enhance the few-shot learning efficiency of pre-trained language models. With this method, more contextual data is fed into a pre-trained language model to refine it on a few-shot job. The additional phrases or paragraphs that give more details about the work at hand might be this contextual knowledge. With just a small number of training instances, ICL seeks to leverage this contextual data to improve the model’s capacity to generalize to new tasks.
However, by identifying and freezing key model parameters, parameter-efficient fine-tuning is a strategy that seeks to increase the effectiveness of fine-tuning pre-trained language models on tasks downstream.
This method entails freezing a portion of the model’s parameters to avoid overfitting and fine-tuning the pre-trained model on a limited set of data. The model can keep more of its pre-trained information by choosing freezing key parameters, which enhances its performance on downstream tasks with sparse training data.

Is PEFT or ICL More Efficient?
Let us now discuss ICL vs. PEFT. For small language model programs, where models have to swiftly change to new tasks with minimal training samples, parametric few-shot learning (PFSL) is an essential job. ICL is one of the most widely used methods that have been proposed in recent years to address this difficulty. However, a 2021 study presents a novel method known as parametric efficient few-shot learning that performs better in terms of reliability than ICL while needing significantly fewer computational resources.
PEFT-fine tuning uses a unique scaling mechanism called (IA)^3 to rescale inner activations using learned vectors, which is one of the key reasons it performs better than ICL. With just a few more parameters added, this method outperforms fine-tuning the entire model. Alternatively, ICL uses a small sample size to fine-tune the whole model, which may result in overfitting and a decrease in accuracy.
The incorporation of two extra loss factors by PEFT methods, which encourages the model to output a lower probability for erroneous choices and takes the length of distinct response options into consideration, is another reason why it performs better than ICL. By avoiding overfitting, these PFT training loss terms improve the model’s ability to generalize to new tasks.
Parameter-efficient fine-tuning not only performs better than ICL, but it also uses fewer computing resources. According to the study report, PEFT trains on a single NVIDIA A100 GPU in under 30 minutes and needs over 1,000 times less floating-point operations (FLOPs) while inference than few-shot ICL with GPT-3. Because of this, PEFT is now a more viable and scalable option for NLP applications in the real world.
In general, few-shot learning for NLP applications has advanced significantly with the development of PEFT. For jobs requiring fast adaptation to novel few-shot learning contexts, it is a better option to ICL because of its utilization of (IA)^3 scaling, extra loss terms, and higher computing efficiency.
Parameter-efficient fine-tuning not only performs better than ICL, but it also uses fewer computing resources. According to the study report of PEFT paper, PEFT trains on a single NVIDIA A100 GPU in under 30 minutes and needs over 1,000 times fewer floating-point operations (FLOPs) while inference than few-shot ICL with GPT-3. Because of this, PEFT is now a more viable and scalable option for NLP applications in the real world.
In general, few-shot learning for NLP applications has advanced significantly with the development of PEFT. For jobs requiring fast adaptation to novel few-shot learning contexts, it is a better option for ICL because of its utilization of (IA)^3 scaling, extra loss terms, and higher computing efficiency.
Use Cases of PEFT
Classification of Texts
- With PEFT, you can quickly and easily adapt huge models of language for sentiment analysis, which is perfect for online reviews, customer feedback, and real-time social media evaluation.
- Identify important entities in text, including names, organization, and locations by effectively refining models. Data extraction in industries like healthcare and finance is essential.
Translation by Machine
- Use PEFT to modify pre-trained models for particular languages, pairs, or industries, producing translations of excellent quality with less computational demand that can be used in an environment with constrained resources.
AI that can Converse
By customizing, pre-trained models for conversation in specific sectors or business acting, PEFT can improve the model’s capacity to handle unique contexts and inquiry.
Computer Vision
- Apply small parameter changes to pre-trained visional algorithms were specific data sets. This method helps with imagining in hospitals, where models are adjusted to identify particular elements.
- Improve models to quickly recognize and categorize items in pictures and movies. This is essential for applications in retail inventory management, autonomous, driving, and surveillance.
Recognition of Speech
With PEFT, you may modify pre-trained speech, recognizing models to fit certain accents, dialects, or languages, increasing accuracy, and useful Ness in a variety of linguistic contexts.
What are the Techniques of Parameter-efficient Fine-tuning?
New approaches are being developed through research, however, PFT approaches are currently limited to the following:
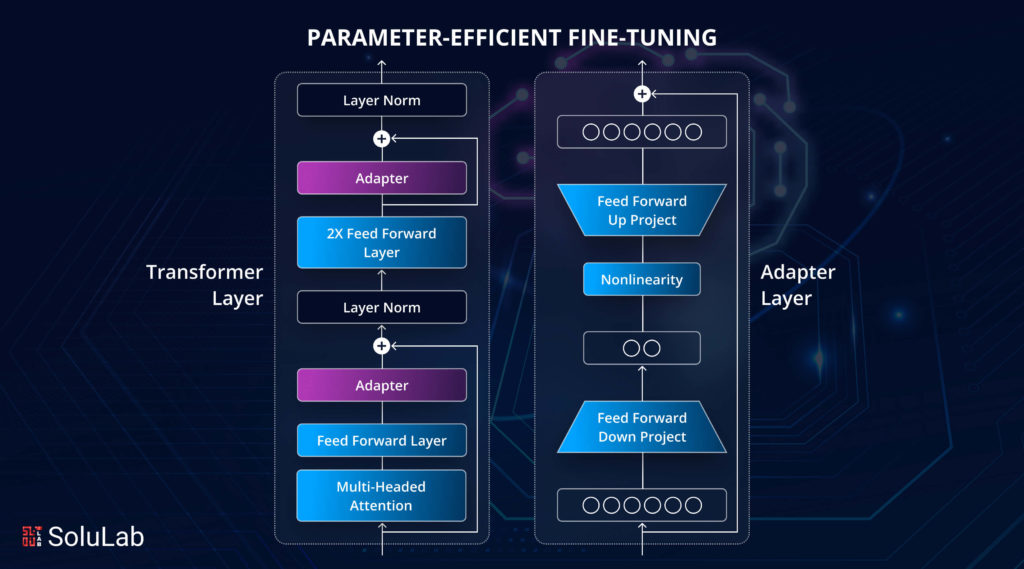
1. Adapter
A sub-model called an adapter can be introduced to pre-train language models to adjust their underlying representation during fine-tuning. By placing the adapter behind the transformer architecture, multi-head, focusing, and feed layers, we may tune only the adapter parameters while freezing the rest of the model.
2. LoRA
Another method for fine-tuning big language models for specific activities or domains is a low-rank adaptation (LoRA). Like adapters, LoRA is a small adaptable module that fits into the PEFT transformer design. Freezing the train, the weight of the model, and injecting the rank breakdown matrix into each transformer architecture, layer drastically reduces downstream task trainable parameters. This approach can reduce trainable parameters by 10,000 times and GPU memory by three times while matching or exceeding fine-tuning the quality of models on various jobs.
3. Quick Training
PEFT also uses prompt tuning to adjust built-in language models to downstream requirements. Instead of model training where all pre-Trainin model parameters are modified for each job prompt, tuning requires practicing soft prompts by backpropagation and labeling samples to fine-tune them for individual tasks. Quick tuning outperformance, GPT three fuse shot learning, remains more competitive as the model size increases. It boosts domain transfer reliability and speeds up assembly. Instead of model Tweaking, which requires copying the complete treated model for each job, it stores a shot task-specific reminder for each work making it simple to reuse a frozen model for several downstream tasks.
4. Prefix Tuning
For natural language, production, prefix tuning is a lighter alternative to find tuning big pre-Trainin language models. Given the side of current models, fine-tuning calls for changing and storing all variables for each task, which is expensive. Prefix tuning optimizes a tiny continuous task. Pacific vector termed the prefix while freezing language model parameters. Prefix tuning trains, language models, and free parameters. Prefix tuning finds a context to guide the Model of language to generate task-specific content. the model.
What is the Process of Parameter-efficient Fine-tuning?
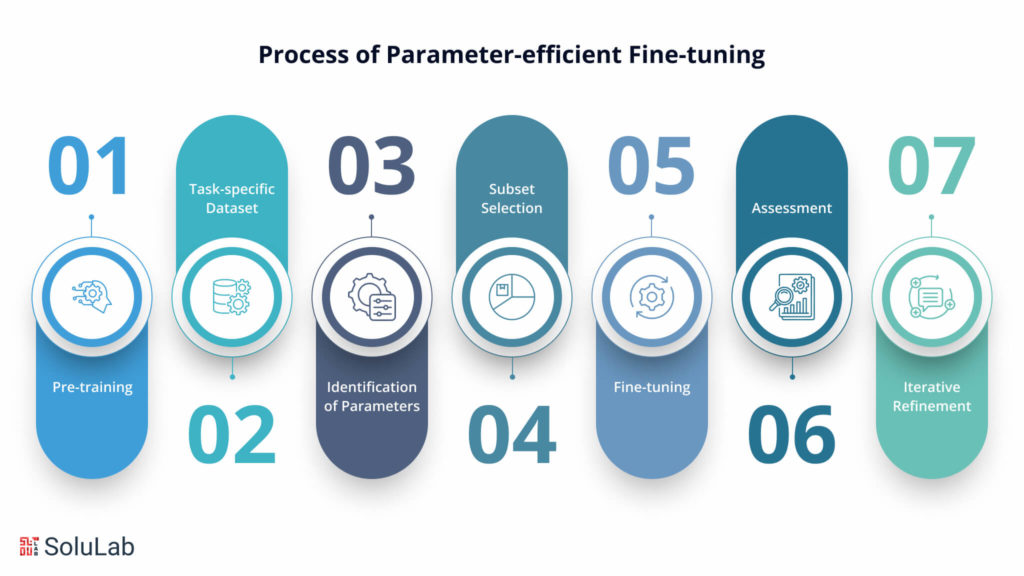
Depending on the specific setup and the trained model being utilized, there might be variations in the stages required for parameter-efficient fine-tuning. However, the following provides a broad overview of the PEFT steps, which can be impacted by common issues like the no module named ‘PEFT’ error:
- Pre-training: First, a large-scale model is developed for a generic job, such as language modeling or picture classification, on a big dataset. The pre-training stage aids in the model’s acquisition of useful features and representations from the data.
- Task-specific Dataset: Assemble or produce a dataset tailored to the intended task for which you wish to optimize the trained model. This dataset needs to be representative of the intended job and labeled.
- Identification of Parameters: Determine or assess the significance or applicability of parameters in the trained model for the intended use. This stage aids in figuring out which parameters to focus on during fine-tuning. Important parameters may be found using a variety of approaches, including gradient-based algorithms, importance estimates, and sensitivity analysis.
- Subset Selection: Choose a portion of the parameters from the pre-trained model that best suits the intended job. One way to identify the subset is to apply specific criteria, like choosing the top k most significant attributes or imposing a threshold on the significance scores.
- Fine-tuning: Preserve the other parameters and start the chosen subset of parameters using the values from the trained model. Use the task-specific dataset to adjust the chosen settings. This entails utilizing methods like Adam optimization or stochastic gradient descent (SGD) to develop the model on the target task data.
- Assessment: Examine how well the adjusted model performs on a validation set or using other assessment metrics pertinent to the goal task. This stage aids in evaluating how well PEFT performs while utilizing fewer parameters to get the intended results.
- Iterative Refinement (optional): To further enhance the model’s performance, you can choose to iterate and refine the PEFT model from pretrained process by modifying the parameter selection criteria, investigating various subsets, or fine-tuning for extra epochs. This is dependent on the performance and needs.
It’s crucial to remember, nevertheless, that applications and research articles may employ different PEFT implementation strategies and specifics.
Related: Comparison of Large Language Models
Step-by-Step Guide to Fine-Tuning with PEFT
Fine-tuning pre-trained models is a crucial step in enhancing the performance of AI systems for specific tasks. Parameter-efficient fine-tuning (PEFT) is an advanced technique that optimizes this process by fine-tuning only a subset of the model’s parameters, reducing computational costs and time. Here’s a step-by-step guide to fine-tuning with PEFT, while also addressing potential issues like the no module named ‘PEFT’ error:
Step 1: Select a Pre-Trained Model
Choose a pre-trained model that suits your specific application. Models like BERT, GPT, or RoBERTa are popular choices for natural language processing tasks. Ensure the model is compatible with PEFT methods.
Step 2: Define the Task
Clearly define the task for which you are fine-tuning the model. It could be text classification, sentiment analysis, named entity recognition, or any other specific NLP task. This definition will guide the selection of data and fine-tuning approach.
Step 3: Prepare the Dataset
Gather and preprocess the dataset required for your task. This involves cleaning the data, tokenizing text, and splitting the dataset into training, validation, and test sets. Ensure the dataset is representative of the task to achieve optimal results.
Step 4: Choose PEFT Techniques
Select appropriate PEFT techniques, such as:
- Adapters: Small neural networks are added to each layer of the transformer, learning task-specific features while keeping the main model weights frozen.
- Prefix-Tuning: Prepend trainable prefixes to the input embeddings, allowing the model to adapt to new tasks without modifying the original weights.
- Low-Rank Adaptation (LoRA): Introduce low-rank matrices to adapt the model weights efficiently.
Step 5: Configure the Training Parameters
Set the training parameters, including learning rate, batch size, number of epochs, and optimizer. Ensure the parameters are fine-tuned for PEFT to avoid overfitting or underfitting.
Step 6: Implement Fine-Tuning
Utilize libraries like Hugging Face’s Transformers or PyTorch to implement the fine-tuning process. These libraries provide built-in support for PEFT methods, streamlining the fine-tuning workflow.
Step 7: Evaluate the Model
After fine-tuning, evaluate the model’s performance using the test dataset. Calculate metrics such as accuracy, F1 score, precision, and recall to measure the effectiveness of the fine-tuning process.
Step 8: Optimize and Iterate
Based on the evaluation results, adjust the fine-tuning parameters or PEFT methods if necessary. Iteratively fine-tune the model until the desired performance is achieved.
Step 9: Deploy the Model
Once the model performs satisfactorily, deploy it in your production environment. Monitor its performance and make adjustments as needed to ensure it continues to meet the required standards.
By following these steps, you can efficiently fine-tune pre-trained models using PEFT, achieving superior performance for your specific tasks while minimizing computational resources.

Conclusion
Parameter-efficient fine-tuning (PEFT) represents a significant advancement in AI model optimization. By allowing fine-tuning of only a subset of parameters, PEFT minimizes computational resources and time, making it a cost-effective solution for enhancing the performance of pre-trained models. This approach is particularly beneficial for specific tasks such as text classification, sentiment analysis, and named entity recognition, where the ability to quickly adapt models to new datasets and applications is crucial. The use of techniques like adapters, prefix-tuning, and low-rank adaptation further amplifies the flexibility and efficiency of the fine-tuning process, ensuring that AI systems can be tailored to meet diverse and dynamic requirements.
However, implementing the PEFT model from pretrained comes with its own set of challenges, including the complexity of selecting appropriate techniques, configuring training parameters, and ensuring optimal performance across different tasks. As a leading AI development company, SoluLab is equipped to navigate these challenges, offering expertise in fine-tuning pre-trained models with PEFT.
Our team of skilled AI developers can help you use the full potential of PEFT, ensuring that your AI use cases solutions are both powerful and resource-efficient. Whether you need to hire AI specialists or seek comprehensive AI development services, SoluLab is your trusted partner. Contact us today to explore how we can enhance your AI capabilities and drive innovation in your projects.
FAQs
Shipra Garg is a tech-focused content strategist and copywriter specializing in Web3, blockchain, and artificial intelligence. She has worked with startups and enterprise teams to craft high-conversion content that bridges deep tech with business impact. Her work translates complex innovations into clear, credible, and engaging narratives that drive growth and build trust in emerging tech markets.


![Top 10 AI Development Companies Setting New Industry Standards [2026 Edition]](https://www.solulab.com/wp-content/uploads/2023/05/AI-Development-Companies.webp)