


Picture yourself as a chef creating a new recipe. As a novice, you find it challenging to craft innovative and flavorful dishes due to your limited culinary experience. Eager to improve your skills, you turn to a seasoned mentor who provides insightful feedback and imparts the art of culinary techniques. In the world of AI, Long Ouyang, a research scientist at OpenAI, highlights that “Reinforcement Learning from Human Feedback (RLHF) learns from human guidance to expedite the training process.
RLHF involves two essential roles: the human mentor and the AI apprentice. Similar to the culinary mentor, the human guide offers feedback to shape the AI’s decision-making. Meanwhile, the AI apprentice uses this guidance to enhance its culinary capabilities and optimize its overall performance.
This guide explores what RLHF is, how it works, and being used in the real world.
What is Reinforcement Learning from Human Feedback?
Reinforcement Learning from Human Feedback (RLHF) is a way for computers to learn and get better at tasks with the help of people. In regular learning, computers figure things out on their own, but RLHF uses a mix of computer learning and human guidance.
In simple terms, when we want a computer to do something, like talk to us like a friend (like a chatbot), we use RLHF to make it better. Computers learn from what people say and correct them if they make mistakes. This makes the computer smarter and more helpful in conversations.
RLHF is especially useful for language-related tasks, like chatting or summarizing information. It helps computers understand what we want and respond in a way that makes sense. It’s like teaching a computer to talk and understand us better.
OpenAI’s ChatGPT is an example of a computer program that uses RLHF. It learns from what people say to make its responses better and more appropriate. This way, it becomes a more useful and friendly tool for communication.
Key Components of RLHF
Understanding RLHF, or Reinforcement Learning with Human Feedback, becomes easier when breaking down its key components. These components lay the groundwork for building intelligent systems that learn from human demonstrations and feedback, creating a bridge between human knowledge and machine learning. Let’s explore these elements in simpler terms:
- Agent
The heart of RLHF is the agent, an artificial intelligence system that learns to carry out tasks through reinforcement learning (RL). This agent engages with an environment and receives feedback, either in the form of rewards for good actions or punishments for undesirable ones.
- Human Demonstrations
RLHF teaches the agent what actions to take by providing human demonstrations. These demonstrations are sequences of actions in response to different situations, showcasing desirable behavior. The agent learns by imitating these demonstrated actions.
- Reward Models
In addition to human demonstrations, reward models offer extra guidance to the agent. These models assign a value to different states or actions based on desirability. The agent then aims to maximize the cumulative reward it receives, learning to make choices that lead to favorable outcomes.
- Inverse Reinforcement Learning (IRL)
IRL is a technique within RLHF that helps agents infer the underlying reward function from human demonstrations. By observing the demonstrated behavior, agents try to grasp the implicit reward structure and learn to replicate it.
- Behavior Cloning
Behavior cloning is a method for the agent to imitate human actions. The agent learns a set of rules by aligning its actions closely with those demonstrated by humans. This helps the agent acquire desirable behaviors through imitation.
- Reinforcement Learning (RL)
Once the agent has learned from demonstrations, it transitions to RL to further refine its policy. RL demands an agent to observe the environment, take appropriate action, and get feedback. Through this trial-and-error process, the agent fine-tunes its policy for optimal performance.
- Iterative Improvement
RLHF often follows an iterative process. Human demonstrations and feedback are continuously provided to the agent, which refines its policy through a combination of imitation learning and RL. This iterative cycle repeats until the agent achieves a satisfactory level of performance.
RLHF: Potential Benefits
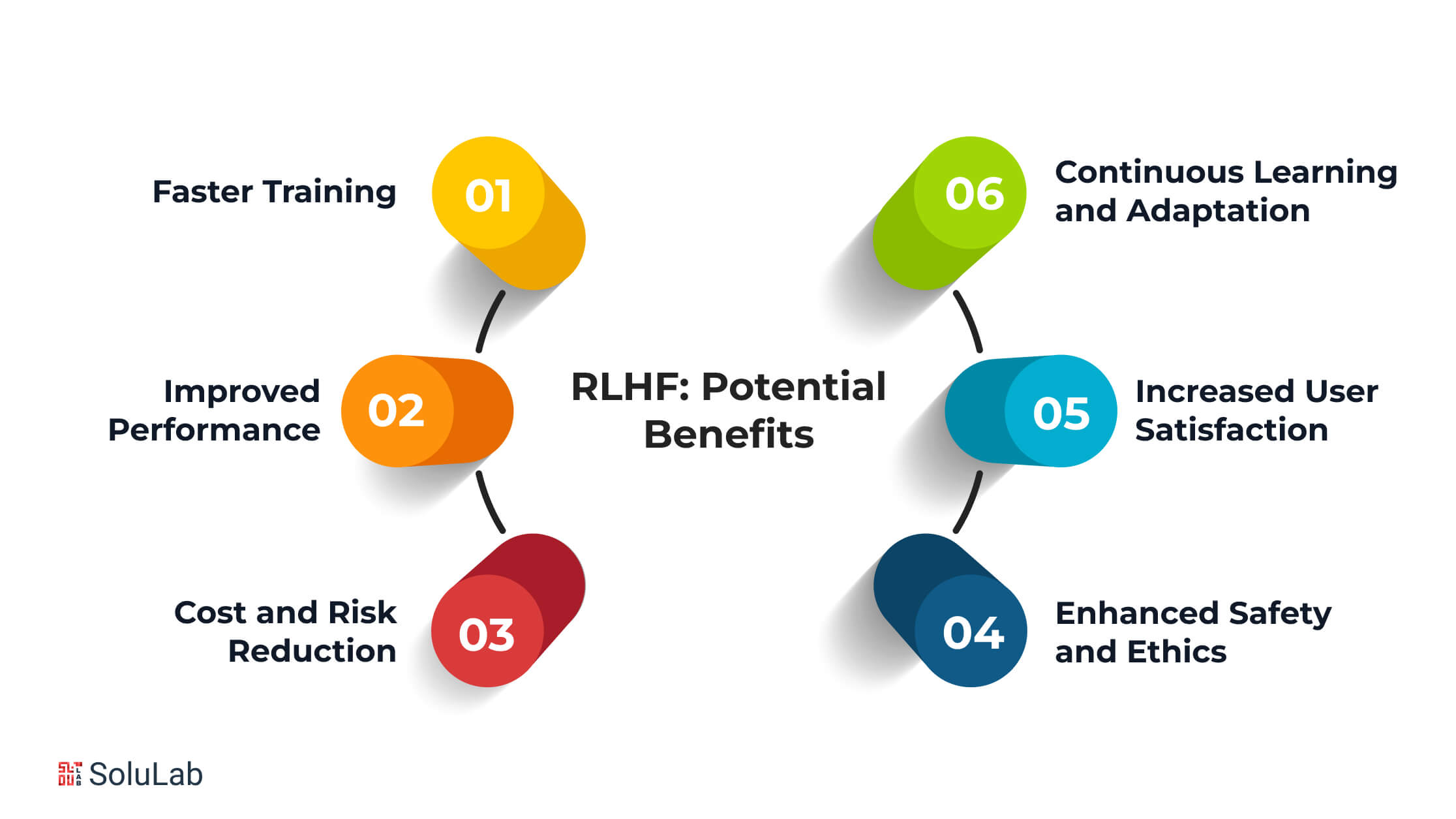
RLHF, or Reinforcement Learning with Human Feedback brings several advantages to businesses. It makes operations smoother, decisions wiser and overall enhances performance and efficiency. Let’s take a closer look at the benefits of RLHF in simpler terms:
- Faster Training
RLHF speeds up the training of reinforcement learning models. Using human feedback, skips the guesswork and accelerates the learning process. For instance, it can swiftly adapt AI summary generation to different topics or situations by incorporating human input.
- Improved Performance
With RLHF, you can make your reinforcement learning models better using human feedback. This means fixing mistakes and enhancing the model’s choices. For example, in chatbots, human feedback can refine responses, making customers happier with the interaction.
- Cost and Risk Reduction
RLHF helps in avoiding the costs and risks associated with training reinforcement learning models from scratch. Human expertise allows you to bypass expensive trial and error, catching mistakes early on. In fields like drug discovery, RLHF can pinpoint promising molecules for testing, saving time and resources.
Related: What is an AI Copilot?
- Enhanced Safety and Ethics
Using human feedback, RLHF trains reinforcement learning models to make ethical and safe decisions. In medical scenarios, for instance, it ensures that treatment recommendations prioritize patient safety and values, promoting responsible decision-making.
- Increased User Satisfaction
RLHF allows you to customize reinforcement learning models based on user feedback and preferences. This personalization results in tailored experiences that meet user needs. For instance, in recommendation systems, RLHF improves suggestions by incorporating feedback from users.
- Continuous Learning and Adaptation
RLHF enables reinforcement learning models to continuously learn and adapt to human feedback. Regular feedback ensures that the models stay up-to-date with changing conditions. For example, in fraud detection, RLHF helps models adjust to new patterns of fraud, improving overall accuracy.
How Does the RLHF Work?
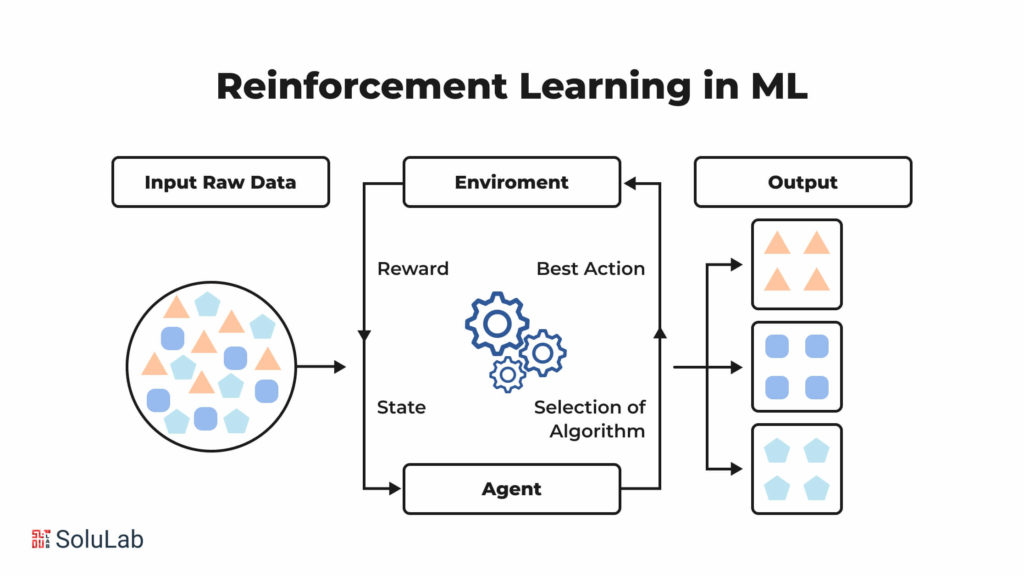
Unlike standalone methods, RLHF does not operate in isolation due to the potentially high costs associated with human trainers. Instead, it serves as a tool to fine-tune pre-existing models, optimizing their performance. Let’s delve into the process in simpler terms.
- Step 1 – Start with a Pre-trained Model
Begin by selecting a pre-trained model, such as ChatGPT derived from an existing GPT model. These models have already undergone self-supervised learning, possessing the ability to predict and generate sentences.
- Step 2 – Supervised Fine-tuning
Fine-tune the chosen pre-trained model to enhance its capabilities. Human annotators play a crucial role by preparing sets of prompts and corresponding results. This training guides the model to recognize specific patterns and align its responses. For instance, annotators might provide training data like:
Prompt: Write a simple explanation about artificial intelligence.
Response: Artificial intelligence is a science that…
- Step 3 – Create a Reward Model
Introduce a reward model, a large vision model tasked with sending a ranking signal to the original model during training. The reward model evaluates the foundational model’s output and provides a scalar reward signal. Human annotators create comparison data, generating prompt-answer pairs ranked according to preference. Despite subjectivity influenced by human perception, the reward model learns to produce a scalar signal representing the relevance of the generated response based on human preference. Once trained, the reward model autonomously ranks the RL agent’s output.
- Step 4 – Train the RL Policy with the Reward Model
Establish a feedback loop to train and fine-tune the RL policy once the reward model is ready. The RL policy is a duplicate of the original model that adjusts its behavior based on the reward signal. Simultaneously, it sends its output to the reward model for evaluation.
Using the reward score, the RL policy generates responses it deems preferable, incorporating feedback from the human-trained reward system. This iterative process continues until the reinforcement learning agent achieves the desired level of performance.
RLHF: Approaches
The RLHF (Reinforcement Learning with Human Feedback) approaches are the methods that combine the cognitive strengths of humans with the computational capabilities of machines, fostering a symbiotic relationship for more effective and intuitive learning.

- Learn from Likes and Dislikes
In this approach, humans tell the machine what they like or dislike about its actions. Imagine teaching a robot to cook – you might say you like it when it stirs slowly but dislike it when it uses too much salt. The machine then adjusts its actions based on this feedback to improve over time.
- Watch and Imitate
Another way is to show the machine how to do things. Humans can demonstrate the right way, and the machine learns by imitating those actions. For example, if you’re teaching a virtual assistant to schedule appointments, you can demonstrate the process, and the machine learns to do it correctly by watching you.
- Correct Mistakes
Humans can also correct the machine when it makes mistakes. If a computer program is learning to play a game and makes an error, you can tell it what went wrong. The machine then adjusts its strategy to avoid the mistake in the future.
Related: AI and ML in data integration
- Guide with Rewards
Machines can also learn by receiving rewards for good behavior. If an AI is learning to navigate a maze, you can give it a “reward” when it finds the right path. This encourages the machine to repeat the actions that led to success.
- Mix Human and Machine Skills
Sometimes, humans and machines can work together as a team. Humans bring their knowledge, and machines contribute their computing power. It’s like having a teammate – you both bring different strengths to solve problems.
Limitations of RLHF
While Reinforcement Learning with Human Feedback models have shown success in training AI for complex tasks, they come with some challenges.
- Expensive Human Preference Data
Gathering first-hand human input for RLHF can be costly, limiting its scalability. Solutions like reinforcement learning from AI feedback (RLAIF) have been proposed by Anthropic and Google, replacing some human feedback with evaluations from another language model.
- Subjectivity in Human Input
Defining “high-quality” output is challenging as human annotators often disagree on what constitutes appropriate model behavior. This subjectivity makes it difficult to establish a definitive “ground truth” for assessing model performance.
- Fallible or Adversarial Human Evaluators
Human evaluators may make mistakes or intentionally provide misleading guidance to the model. Recognizing the potential for toxic behavior in human-bot interactions, there is a need to assess the credibility of human input and guard against adversarial data.
- Risk of Overfitting and Bias
If human feedback comes from a narrow demographic, the model may face performance issues when used by diverse groups or prompted on topics where human evaluators hold biases. This risk highlights the importance of obtaining feedback from a broad range of perspectives.
Applications of Reinforcement Learning from Human Feedback
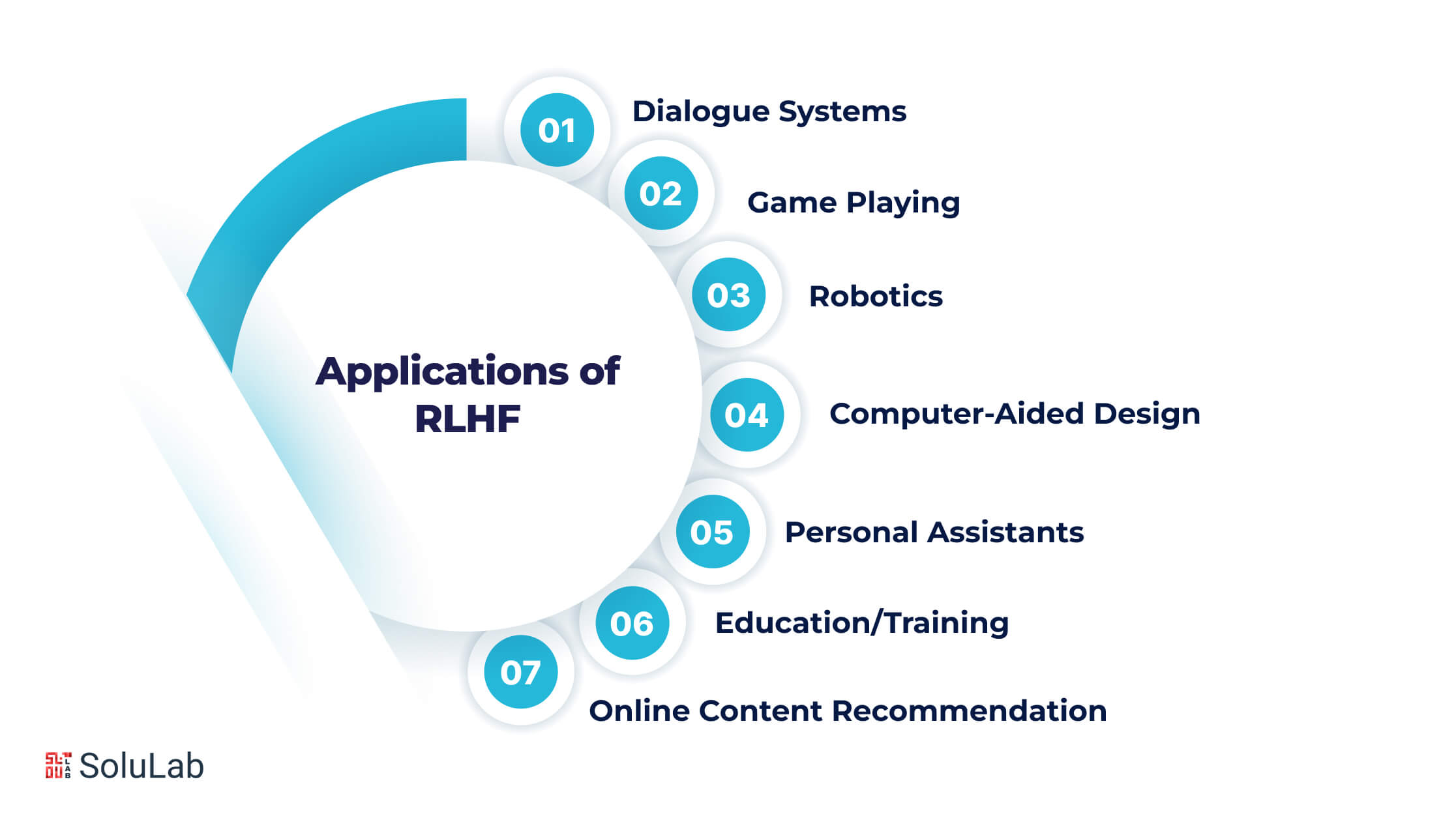
Reinforcement Learning (RL) techniques, which learn from human feedback, have various practical applications. Let’s explore some simple examples:
- Dialogue Systems
RL agents can engage in conversations with humans. By observing how people respond to the agent, it learns to have more natural and engaging conversations over time. This could improve virtual assistants or chatbots.
Related: How to Build an AI-Powered Chatbot For Your Business?
- Game Playing
Humans can provide feedback on wins and losses to teach agents to play games like Go, chess, or video games. An example is AlphaGo, which used RL guided by human experts to become a master at the game of Go.
- Robotics
Robots can perform tasks like picking up objects and then ask humans for feedback on their movements and grip. This feedback helps robots improve their ability to handle objects safely and effectively.
- Computer-Aided Design
RL agents can generate design concepts and prototypes, receiving feedback from human designers on aspects like aesthetics, usability, and manufacturability. This iterative process leads to the creation of better designs.
- Personal Assistants
Digital assistants like Alexa and Google Assistant can learn from implicit human feedback through continued usage. Completion of tasks, customer satisfaction surveys, and long-term usage patterns shape the assistant’s future behaviors, making them more helpful and responsive.
- Education/Training
Interactive learning and training applications can utilize RL guided by a human trainer or instructor to adapt based on student performance and feedback. This personalized approach enhances the learning experience for individuals.
- Online Content Recommendation
Websites can employ RL to optimize user engagement, satisfaction, and time spent on the site. Implicit feedback signals from human users, such as their behaviors and preferences, guide the recommendation algorithms, ensuring content relevance.
RLHF: Case-Studies
Reinforcement Learning from Human Feedback (RLHF) is revolutionizing the capabilities of natural language processing AI systems, transforming them from indiscriminate and aimless models into purposeful, intelligent, and safer applications.
- Email Writing
In email composition, a non-RLHF model may struggle with a simple prompt like “Write an email requesting an interview.” Instead of crafting a coherent email, it might misinterpret the prompt as a to-do list, leading to a jumbled response. In contrast, a fine-tuned RLHF model understands user expectations, generating a polished email that engages with the intended purpose. This distinction highlights the practicality and user-friendliness of RLHF in simplifying everyday tasks.
- Mathematical Problems
While large language models excel at linguistic tasks, they may falter when faced with mathematical challenges. A non-RLHF model, prompted with “What is 5 + 5?”, might misconstrue it as a linguistic query and provide a non-mathematical response. In contrast, an RLHF model, specifically trained for arithmetic use cases, accurately interprets the question and offers a straightforward solution. This underscores the importance of RLHF in tailoring models for diverse applications, expanding their utility beyond linguistic tasks.
- Code Generation
Large language models are adept at coding, but their output may vary depending on training. A non-RLHF model prompted to “Write a simple Java code that adds two integers,” might diverge into unrelated instructions or provide incomplete code. On the other hand, a well-trained RLHF model excels in delivering precise code examples, accompanied by explanations of how the code functions and the expected output. This showcases the effectiveness of RLHF in refining models for specific tasks, enhancing their practical applicability.
RLHF: What is in the Future?
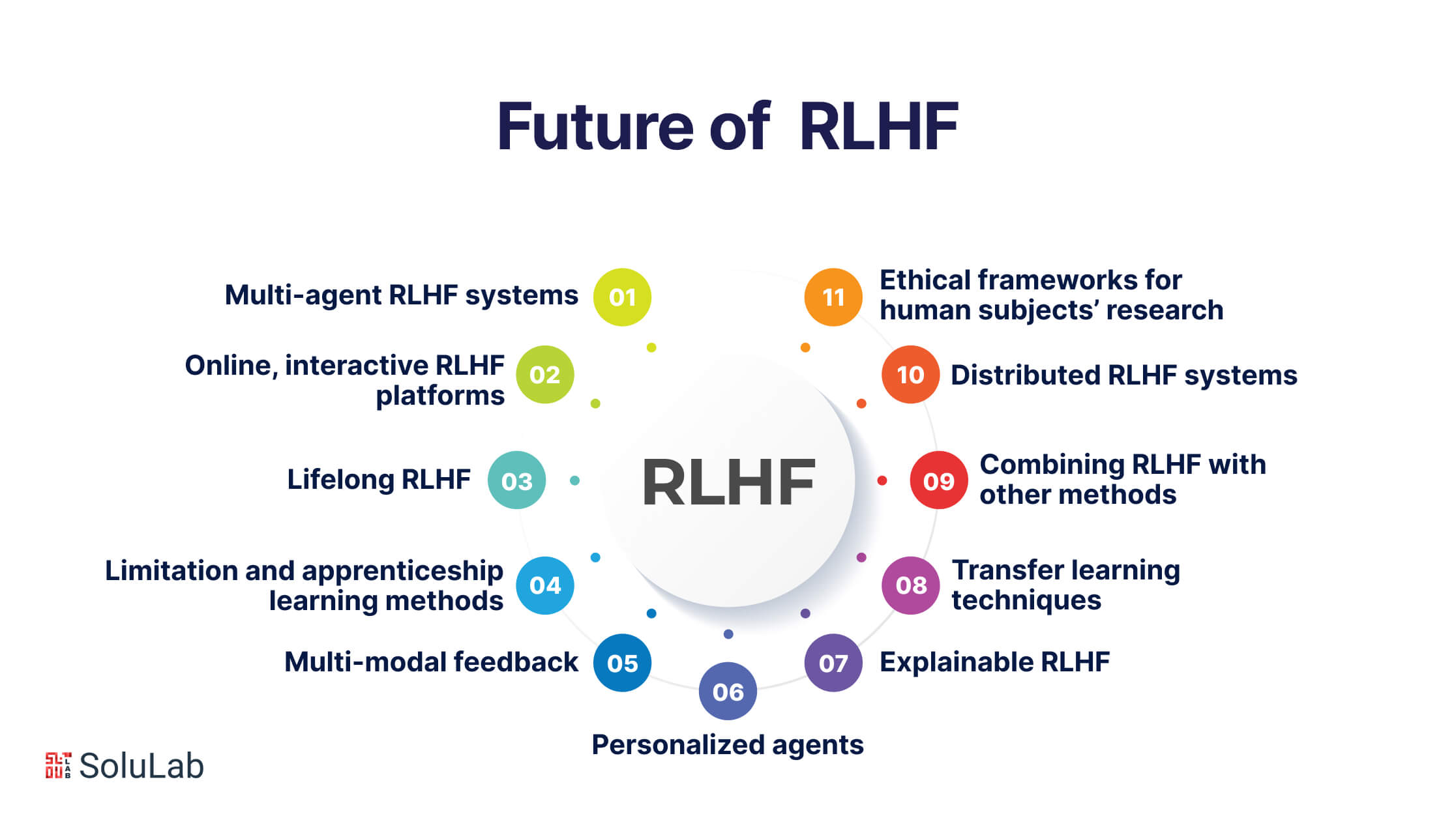
Using Human Feedback to Improve Learning in Artificial Intelligence (AI) has great potential to make a positive impact in various fields like healthcare and education. This approach aims to create AI systems that better understand and cater to human needs, leading to customized experiences and lower training costs. However, challenges arise in managing biases and handling unclear inputs to avoid unintended consequences.
Here are some possible future trends and advancements in using human feedback to enhance reinforcement learning (RLHF):
1. Multi-agent RLHF systems: Agents working together or competing to accomplish tasks based on collective human guidance.
2. Online, interactive RLHF platforms: Platforms that allow continuous, real-time human feedback to guide ongoing agent learning.
3. Lifelong RLHF: Agents capable of autonomously seeking and applying human feedback over extended periods to gradually improve their skills.
4. Limitation and apprenticeship learning methods: Combining human demonstrations with feedback to efficiently train complex skills.
5. Multi-modal feedback: Using various feedback sources like language, gestures, facial expressions, and emotions, in addition to rewards.
6. Personalized agents: Customizing RLHF training for individualized, one-to-one relationships between agents and users.
7. Explainable RLHF: Creating interpretable, transparent models to communicate the progress and decisions of learning agents.
8. Transfer learning techniques: Allowing agents to generalize feedback experiences across related environments or tasks.
9. Combining RLHF with other methods: Enhancing RLHF with additional approaches like self-supervised learning, generative models, theory of mind, etc.
10. Distributed RLHF systems: Utilizing cloud and edge computing for large-scale, collaborative human-AI training initiatives.
11. Ethical frameworks for human subjects’ research: Implementing guidelines to ensure privacy, autonomy, and well-being in the extensive applications of RLHF.

Take Away
RLHF shows a lot of promise for making AI systems that can learn well from everyday human interactions. By combining human judgment with data-driven algorithms, RLHF aims to create agents that are more personalized, reliable, and able to handle complex tasks. Even though there are challenges like data requirements, interpretability, and ongoing learning, RLHF lays the groundwork for forming cooperative partnerships between humans and AI. As the field progresses, using reinforcement learning with human feedback could unlock new opportunities in areas such as robotics, education, healthcare, and beyond. In summary, RLHF is moving us closer to developing genuinely helpful forms of artificial intelligence.
Connect with our team to discover how SoluLab- an AI development company, excels in producing top-notch training data for RLHF systems. Enhance your AI models with high-quality human feedback, ensuring personalized and effective learning. We’re here to discuss your needs and explore the potential of reinforcement learning guided by human input. Elevate your projects in domains like robotics, education, healthcare, and more. Let SoluLab be your partner in advancing AI capabilities. Hire an AI developer and elevate your projects to new heights!
FAQs
– Bias and fairness: Ensure human feedback is diverse and representative to avoid reinforcing biases in the AI system.
– Transparency and interpretability: Develop mechanisms to understand how human feedback influences the AI’s decision-making process.
– Privacy and security: Protect user data and ensure responsible collection and use of human feedback.
– Human-AI interaction and control: Clearly define the roles and responsibilities of humans and AI in the system and maintain human oversight where necessary.
Shipra Garg is a tech-focused content strategist and copywriter specializing in Web3, blockchain, and artificial intelligence. She has worked with startups and enterprise teams to craft high-conversion content that bridges deep tech with business impact. Her work translates complex innovations into clear, credible, and engaging narratives that drive growth and build trust in emerging tech markets.


