
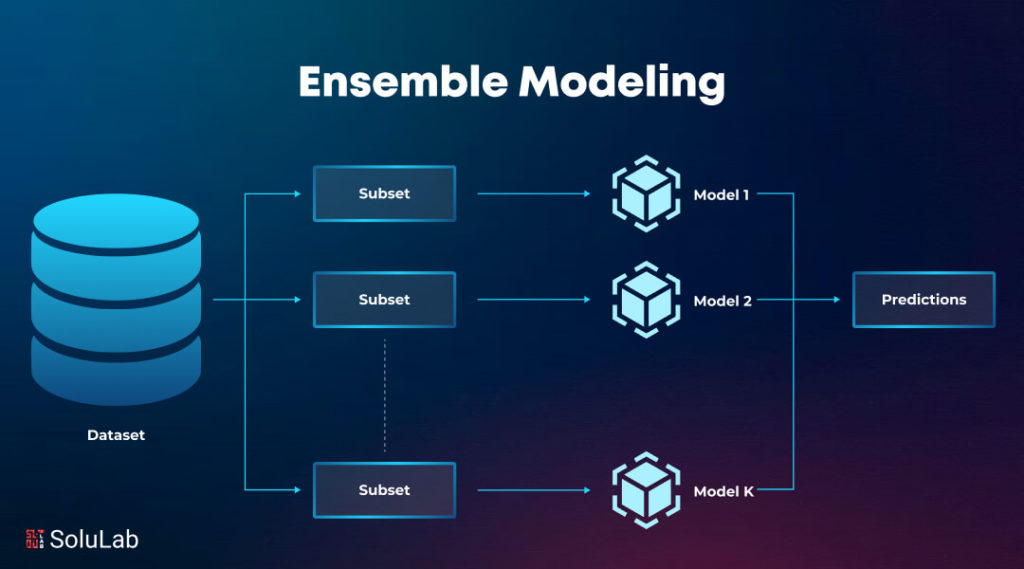
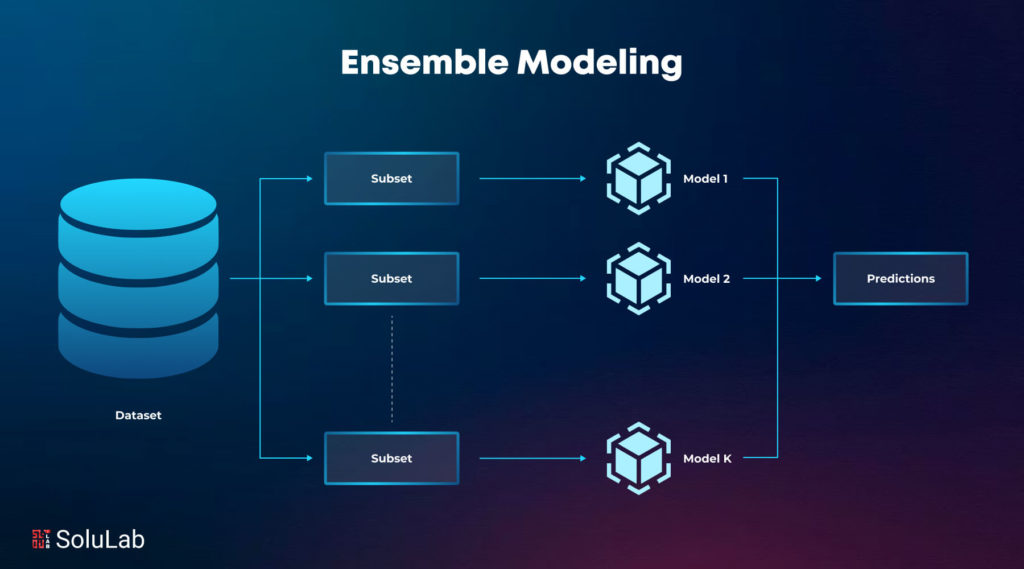
Enter the world of data science teamwork! Ensemble modeling is a major aspect of machine learning, and it is like a team of algorithms in data analysis. When the strengths of multiple models and predictive accuracy are combined, they make a powerful tool in machine learning. From bagging and boosting techniques to gradient boosting, ensemble learning in machine learning offers a versatile toolkit for data gathering.
Join us as we unravel the intricacies and benefits of ensemble models in the dynamic world of data science and technology.
What is Ensemble Modeling?
Ensemble learning in machine learning is a technique that refers to the combination of numerous models as a single solution. It is said that if you combine several weak models they form a stronger model, and make a more accurate prediction. Combining various models can improve the models’ overall performance and show a reduction in errors. By integrating these models, often known as base and weak learners, ensemble methods can also reduce bias and variance.
Basic Techniques of Ensemble Modeling
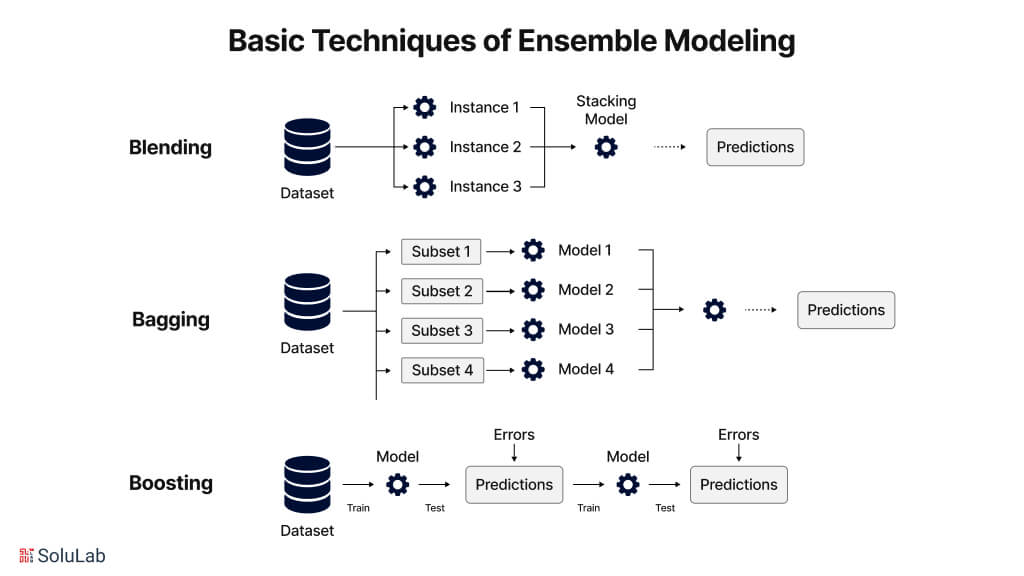
The most common primary approach to ensemble models machine learning includes bagging, boosting, slacking, voting, and averaging. Here is the breakdown of how these approaches work:
1. Bagging
Bagging is the commonly known term for Bootstrap aggregating, a method to merge the concepts of Bootstrap and aggregation to create a unified ensemble model. To indulge in this approach multiple subsets are generated from a data sample, and for each subgroup ansubgroupupidual decision tree is designed. When all the decision trees are in place they are put together using a specific algorithm for the integration of the output to build a effective predictive model.
2. Boosting
Boosting is mainly focused on training models for ensembling models, where every new model tries to correct the errors made by previous models. AdaBoost and Gradient Boosting are examples of boosting methods algorithms. Boosting was initially proposed before it was technically used, since then it has been evolving with many techniques. They begin with weak models and then keep on adding more weight. The learning models are focused on training data to keep learning from the previous ones.
3. Stacking
Stack generalization also known as Stacking is a method that combines multiple types of different predictive models to improve the overall performance. Multiple base learners are trained on the same data and then using meta learner to keep the predictions synthesized. This technique allowed the use of various types of machine-learning algorithms. Stacking is commonly known for its ability to utilize the foundation of multiple models for many advanced techniques in ensemble ML models.
4. Voting
The following simple ensemble model deep learning is in most cases applied to classification problems. This technique makes the final prediction with the help of several models through a voting system. There exist two common formats for voting:
- Majority Voting: In this method, the final forecast is obtained by choosing the class that receives the maximum votes from all of the different models.
- Weighted voting: Similar to majority vote, but some models get more weight in the choice depending on how well they perform
5. Blending
One of the techniques of ensemble modeling is “blending,” which combines individual models to attain improved performance. Contrary to stacking, blending usually involves training a second-level model combining underlying model predictions with the help of a holdout set. This technique will help use different algorithms at their best and thus enable increasing accuracy and generality. By combining models, practitioners can identify several patterns in the data, producing a prediction that is more accurate and dependable.
Why Use Ensemble Modeling?
Ensembling models is a powerful technique in machine learning that combines multiple models for the most accurate outcome. Ensemble learning in machine learning offers accuracy and reliability to users, and here are more reasons to use ensemble models:
| Improved Accuracy By combining the strengths of different models, ensemble learning can capture more complex patterns and compensate for the weaknesses of other individual models. This factor led to improved accuracy in predictions with real-time data. For example: the ARIMA model and gradient boosting model can outperform either model alone. |
| Reduced OverfittingWhen a model is going well with the training data but fails to generalize to new or unseen data it is known as overfiting. Ensemble machine learning, like boosting and bagging establish regularity within such models to prevent overfitting. Decision trees with different limits play a role in identifying complex fraud patterns to avoid overfitting specific types of fraudulent transitions. |
| Adaptability Data can sometimes change its patterns over time like how the weather changes, model ensembles can adjust to these changes by updating models or using online learning. For example in weather forecasting the use of a mix of models can help predict the weather better with the changes it may follow |
| Easy to DeployEnsemble models are easy to deploy in systems with the use of distributed computing frameworks and processing. This in return allows for the efficient processing of high stacks of data and rapid generation of outcomes. For example: In recommendation systems, a collaborative AI models can be deployed on a cluster of machines to enable fast processing. |
| Increased Robustness Systems are supposed to be reliable for every possible event or data. Ensemble machine learning is more robust as they are a combination and provides predictions of multiple models, which also reduces the impact of individual model failures and biases. For instance, an ensemble model which is based on a technical indicator, sentiment analysis, and news events provides a more reliable signal than any other model. |
Examples of Ensemble Modeling
Ensemble modeling is another powerful technique of LLMops that boosts predictive performance through the use of multiple models. Experimental results in various practical scenarios have indicated the successful use of different strategies, such as bagging, boosting, stacking, and blending. A select critique focused on the ensemble model example follows as an empirical illustration of some of the potential ensemble methods for these diverse domains.
- Random Forest Healthcare: Disease Diagnostics
In the field of healthcare, the Random Forest technique, because of bagging ensemble learning, is used in identifying a lot of diseases. The Random Forest method classifies the disease conditions based on various features, for example, age, history, test results, etc. It uses different subsets of patient data to train several decision trees For instance, it has been used in the prediction of cardiovascular disorders based on CT and X-ray data. This reduces overfitting, increases accuracy, and hence makes diagnostic tools more reliable.
- Detection of Credit-Card Fraud: AdaBoost for Financial Fraud Detection
One popular boosting algorithm of ensemble ML models in the financial sector is known as AdaBoost, which is implemented to detect fraudulent transactions. AdaBoost enhances a model’s capability to catch small patterns associated with manipulation by training different weak classifiers on misclassified examples in past iterations. For instance, in detecting credit card fraud, it may combine the outputs of several classifiers, hence ensuring that even the minutest of suspicious transactions are further investigated in more detail. This has been pretty successful at minimizing false negatives, which is an important aspect of fraud prevention.
- Multi-model Approach in E-commerce Application: Recommendation Systems
Product recommendation systems in e-commerce applications provide very useful applications of stacking. In simple words, stacking may bring improvement and better recommendations due to combining predictions from a lot of models: one demographic-based, one content-based, and one collaborative-filtering model. The metamodel learns how to blend the predictions most appropriately, while the base models describe different facets of user behavior and preference uniquely. Such inclusion of ensemble model deep learning further boosts user happiness because of tailored taste in recommendations that are most appreciated.
- Application of Computer Vision: Image Classification for Object Detection
Many computer vision applications will apply ensemble techniques, especially in object identification. A holdout validation set helps combine the predictions resulting from the many models trained on the same dataset, for instance: Convolutional Neural Networks, YOLO, and Faster R-CNN. This approach allows building one model to increase the general accuracy of object classification and localization inside images through the advantages of multiple designs. The ensemble model can do better than single models, as it grasps diversity in properties and trends in data.
- Sentiment Analysis in Social Media: Sentiment Classification
Sentiment analysis uses majority voting: a simple ensemble technique for classifying the sentiment of social media posts. Different classifiers like Naive Bayes, Support Vector Machine, and Logistic Regression are trained with the same dataset to predict whether a post conveys good, negative, or neutral sentiment. The final classification will depend on the majority vote of the classifiers stated above. This tends to strengthen the sentiment analysis system’s resilience, particularly in the handling of noisy and heterogeneous data from social media.
Benefits of Ensemble Modeling
One of the most influential machine learning techniques is ensemble modeling, working with several models at once to enhance predictive performance. Such ensemble methods can improve accuracy, reduce errors, and give more reliable forecasts by putting together the power of different algorithms. This works especially well in complex cases where it would be too hard for one model to identify all significant patterns present in the data. Some benefits of the ensemble model are as follows:
1. Improved Complementarity and Diversity
Ensemble models machine learning amalgamates a diversity of models. All these different models have some special advantages and disadvantages. In this way, ensemble learning comes up with a more complete and complementary depiction of the data since it makes use of many feature sets, training techniques, and model architectures. With this diversity, a much greater range of patterns and interactions is captured, improving performance all around.
2. Handling Complex Relationships
Complex, nonlinear interactions are the norm in real-world data, which is usually too complex to comprehensively be captured by any single model. However, ensemble models of machine learning have the potential to deal with such complex interactions efficiently by combining several different models. Examples include stacking and boosting. That is where the meta-model learns how to combine these predictions best to capture that complexity, while each of the base models may focus on a different aspect of the data.
3. Handling outliers and noise
In many applications, the datasets may be mixed with outliers or tainted with noise, which may reduce the performance of a model. Ensembling models approaches are resilient to these kinds of problems because they make use of the strength of a large number of models. If one model is grossly impacted by noise or outliers, other models in the ensemble may not be affected, and their prediction helps in reducing the impact of those data points.
4. Explainability and Interpretability
While ensemble models are complex, they can also obscure underlying patterns in data. By looking at how the different models contribute to, and are weighted within, the ensemble, a user will understand the relative importance of aspects and how these relate to one another. This may be useful in gaining general knowledge about the problem domain and in the communication of results to stakeholders.
Future of Ensemble Modeling with Machine Learning
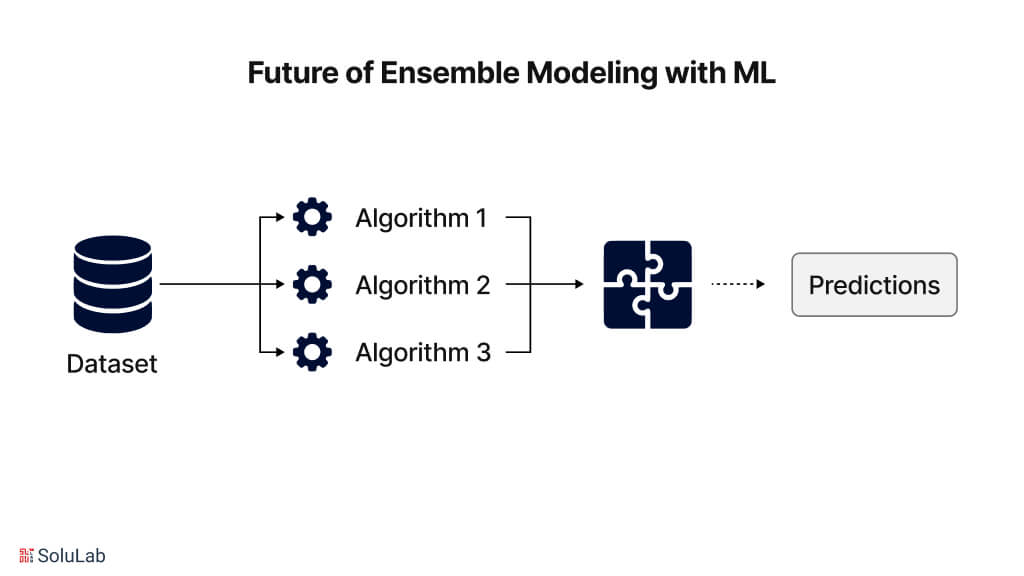
It is expected that, with the advancement in LLM, ensemble modeling is going to get more important, as this can spur creativity and increase the accuracy of prediction. Ensemble methods are becoming a necessity in the big data era since meaningful patterns need to be extracted from the rapidly growing data. Ensemble modeling will become necessary as data grows in both volume and complexity and begins to reveal links heretofore unidentified.
Ensemble approaches are already, quite often, applied in such fields as healthcare, finance, and cybersecurity today to help solve complex problems. As these disciplines continue to generate huge volumes of data, calling for more complex analysis than ever before, ensemble modeling will become necessary for driving innovation. For instance, in the healthcare domain, ensemble models can help pool insights across multiple sources of data and models to risks related to illness, optimization of treatment programs, and fasten the discovery of new drugs. So, the more information sources combined, the better the result will be in many industries. One of the central challenges of machine learning is the models’ interpretability and explainability, especially for sophisticated neural networks.
For example, ensembles of decision trees may show the relative relevance of features and their interactions, thus bringing more model interpretability. Ensemble modeling will play a critical role in making a model accurate, transparent, and understandable with the growing need for explainable AI agent use cases. This would increase the confidence level in the adoption of machine learning solutions for key domains. It is also very well aligned with ensemble approaches since their architecture by design is distributed and parallel. One can train several models independently and then combine them using ensemble approaches, therefore working with federated and edge computing.
Finally, there is interest in integrating ensemble model deep learning. Much of the work on ensemble techniques has been developed to work with shallower models, but recent work on deep ensembles and neural network bagging has also shown some very promising results in improving robustness and measurement of uncertainty in deep models. Ensemble approaches can be used to enhance the dependability and credibility of these models by pairing up with an AI agent development company.

Take Away
An important development in LLMops is ensemble modeling, providing a very solid way to increase prediction accuracy and dependability. Techniques like bagging, boosting, stacking, and mixing make use of the outputs of several models to harness the combined power of several algorithms. These have been applied across a broad expanse of important domains and have rigorously been able to prove their mettle in solving predicting problems.
As machine learning advances in the future, the methods that employ ensembles could be seen as indispensable for building predictive models with improved performance throughout countless industries. To know whether these methods, and innovations will be led to make a difference in the real world you can Hire an AI developer.
SoluLab is developing the most advanced solutions specifically adapted to organizational needs. Explore how data can become your backer for making decisions with an insightful team.
FAQs
Shipra Garg is a tech-focused content strategist and copywriter specializing in Web3, blockchain, and artificial intelligence. She has worked with startups and enterprise teams to craft high-conversion content that bridges deep tech with business impact. Her work translates complex innovations into clear, credible, and engaging narratives that drive growth and build trust in emerging tech markets.


![Top 10 MLOps Consulting Companies in the USA [2026]](https://www.solulab.com/wp-content/uploads/2025/12/Top-MLOps-Consulting-Companies-in-USA.webp)