

Key Takeaways
- An AI tech stack is the complete ecosystem of tools, frameworks, infrastructure, data pipelines, APIs, and deployment layers required to build, train, deploy, and scale AI applications efficiently.
- In 2026, modern AI stacks are becoming more modular, combining LLMs, vector databases, orchestration frameworks, cloud infrastructure, MLOps tools, and AI agents into scalable enterprise ecosystems.
- Choosing the right AI tech stack depends on business goals, scalability needs, security requirements, data architecture, deployment preferences, and integration complexity.
- AI stack best practices include building flexible architectures, prioritizing security and compliance, implementing robust MLOps pipelines, and selecting scalable cloud-native infrastructure.
- Real-world AI deployments increasingly rely on hybrid ecosystems that combine proprietary AI models, open-source frameworks, cloud services, and custom enterprise integrations.
- SoluLab helps startups and enterprises build scalable AI ecosystems with expertise in AI architecture, GenAI development, AI agents, enterprise automation, and custom AI infrastructure solutions.
- With experience across enterprise AI deployments, SoluLab delivers tailored AI tech stack solutions designed for scalability, performance optimization, security, and faster time-to-market.
Artificial intelligence is no longer built on standalone models alone. In 2026, businesses are investing in complete AI tech stacks that combine data pipelines, vector databases, LLM orchestration, cloud infrastructure, AI agents, and real-time analytics into scalable ecosystems. From enterprise automation to generative AI development, the right architecture directly impacts performance, scalability, security, and deployment speed.
As AI adoption accelerates, companies are prioritizing AI development strategies that support faster model training, seamless integrations, lower infrastructure costs, and production-ready deployment. Understanding the layers, components, and best practices behind a modern AI tech stack is now essential for businesses looking to build reliable, future-ready AI solutions at scale.
What is an AI Tech Stack?
An AI Tech Stack is the set of technologies you use to build, deploy, operate, and improve AI-powered software. In practical terms, that means everything from compute and storage to models, vector databases, orchestration frameworks, observability, and safety controls.
If you have ever asked, what is an AI stack, the simple answer is this: it is the production system behind an AI feature. The model gets the attention, but the stack is what makes the model usable. Without the surrounding layers, even the strongest model turns into an expensive demo.
This is where most companies go wrong. They mistake an API integration for an artificial intelligence technology stack. That works for a prototype. It breaks in production. Once real users arrive, you need retrieval, caching, fallback logic, rate limiting, prompt versioning, evaluation workflows, and access controls. Frankly, the truth is that AI success is usually an architecture problem disguised as a model problem.
A good AI software stack also has to be modular. Models change quickly. Vendors change pricing. Compliance requirements tighten. If your architecture cannot absorb those changes without pain, you do not have a real stack. You have a temporary shortcut.
How Does an AI Tech Stack Differ from a Traditional Tech Stack?
An AI Tech Stack differs from a traditional tech stack because AI systems are probabilistic, data-hungry, and operationally noisy. You are not just serving deterministic business logic. You are managing outputs that can vary, drift, hallucinate, and become more expensive under load.
In a traditional application, the code path is mostly explicit. You define logic, test inputs and outputs, and deploy stable services. In an artificial intelligence stack, the behavior depends on model choice, prompt design, context quality, retrieval results, token budgets, and orchestration logic. That means software quality is no longer only a function of code quality.
Here is the practical difference: traditional systems fail in cleaner ways. AI systems fail in fuzzier ways. The response may look fluent while being wrong. An AI chatbot may sound confident while missing a critical policy rule. An agent may complete step one perfectly and still make a bad tool decision in step three. You need a stack that expects those failure modes.
| Dimension | Traditional Tech Stack | AI Tech Stack |
| Core logic | Deterministic business rules | Probabilistic model inference |
| Main data type | Structured records, transactions | Structured + unstructured + embeddings |
| Testing | Unit, integration, regression | Eval sets, prompt tests, model benchmarks |
| Performance focus | Throughput, uptime, query speed | Latency, token cost, answer quality, grounding |
| Failure mode | Errors are obvious | Errors can sound correct |
| Change driver | Code updates | Code, prompts, model versions, data freshness |
| Ops priority | Reliability and scaling | Reliability, safety, observability, cost control |
In my experience, this difference changes team design too. A traditional stack can be owned mostly by app engineers, platform teams, and DevOps. Modern AI tech stacks need tighter collaboration across software engineering, data engineering, product, security, and domain experts. If those teams work in silos, your AI layer will drift away from business reality.

The 5 Key Layers of a Modern AI Tech Stack
The five key layers of a modern AI technology stack are infrastructure, data, models, orchestration, and application/governance. If you understand these layers clearly, you can diagnose almost any architectural weakness in your system.
1. Infrastructure Layer
The infrastructure layer provides the compute, storage, networking, and AI deployment foundation for your AI system. This includes GPUs, TPUs, cloud inference services, container orchestration, serverless runtimes, API gateways, secrets management, and CI/CD pipelines.
For some teams, this layer is fully managed through hyperscalers. For others, especially enterprises with strict control requirements, it includes self-hosted inference clusters, Kubernetes, autoscaling policies, and private networking. The right answer depends on your volume, compliance needs, and in-house platform maturity.
If you are operating from cost-sensitive teams in Chandigarh, Bangalore, or Delhi, this layer matters more than most people admit. A bad compute decision can wipe out margin faster than any frontend mistake. Cheap architecture on paper often becomes expensive architecture at scale.
2. Data and Retrieval Layer
The data and retrieval layer feeds your models the right context at the right time. It includes ETL pipelines, document parsing, chunking, embeddings, vector storage, metadata filtering, ranking, and Retrieval-Augmented Generation, or RAG.
This layer matters because generic models are not your business. Your data is. If your retrieval pipeline is weak, your application becomes eloquent but shallow. If your chunking is poor, you lose context. If your metadata design is sloppy, your retrieval precision collapses.
What I have seen working with enterprise teams is simple: retrieval quality often matters more than model size. A well-grounded smaller model can outperform a larger one when the context is clean, current, and relevant.
3. Model Layer
The model layer is where you select, host, fine-tune, route, and serve the models that power your application. These may include foundation models, open-weight models, embedding models, rerankers, speech models, moderation models, and domain-specific classifiers.
In 2026, strong stacks rarely rely on one model for every task. They use model routing. A lightweight model handles classification, summarization, or extraction. A larger reasoning model handles complex analysis. A small local model may even handle private preprocessing before anything reaches a third-party API.
This is one of the biggest shifts in modern AI tech stacks. The smartest architecture is not the one with the biggest model. It is the one that sends each task to the cheapest model that can do it well.
4. Orchestration and Agent Layer
The orchestration and agent layer coordinates prompts, tools, workflows, memory, state, retries, and multi-step reasoning. If the model layer is the engine, orchestration is the transmission.
This is where prompt templates live. This is where you define tool-calling rules, session memory, human-in-the-loop checkpoints, fallback logic, and step sequencing. For agentic systems, this layer also decides when to plan, when to retrieve, when to call tools, and when to stop.
Most AI product failures are not caused by a weak model. They are caused by weak orchestration. The flow is unclear, tool permissions are too loose, or memory is polluted. When that happens, users blame the AI. The real issue sits one layer below.
5. Application and Governance Layer
The application and governance layer is where users interact with AI and where you enforce control. It includes the frontend, backend APIs, role-based access, audit logs, guardrails, observability, analytics, policy enforcement, and human review workflows.
You should treat governance as a product feature, not a legal afterthought. If your system handles sensitive data, regulated workflows, or customer-facing recommendations, governance is not optional. It is the difference between a deployable AI product and a risky science experiment.
Components of an AI Tech Stack
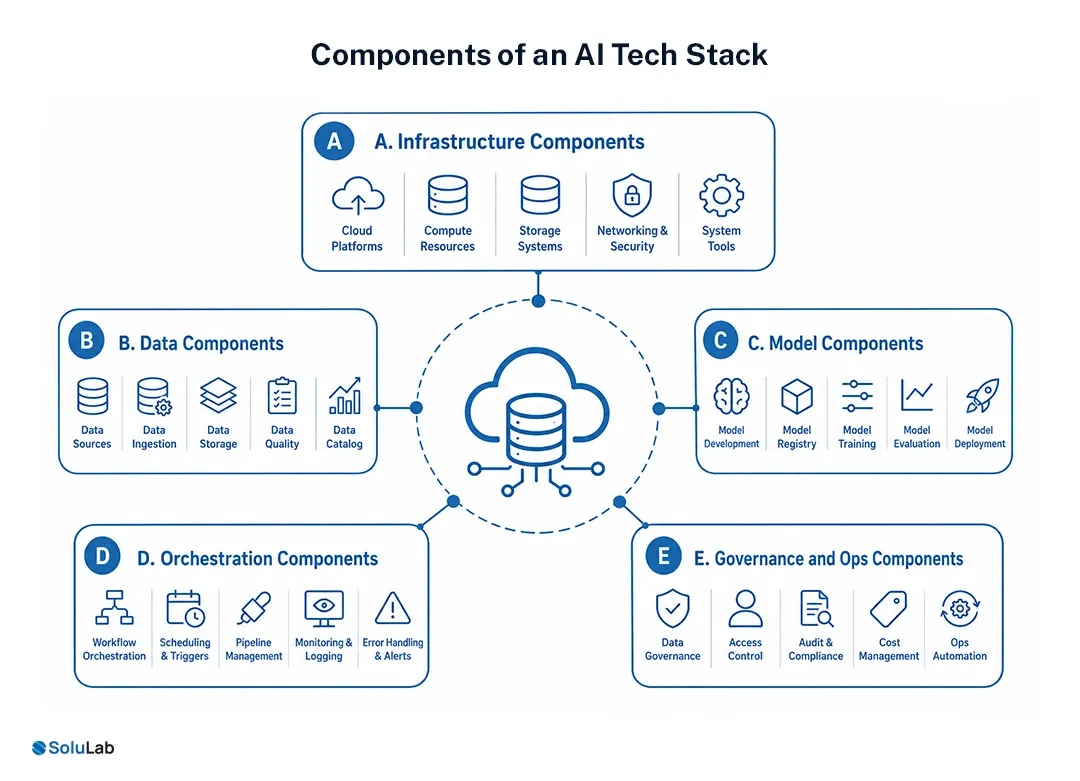
The core components of an AI tech stack are the actual tools, services, frameworks, and control systems inside those five layers. Once you map components clearly, architecture decisions become far easier.
A. Infrastructure Components
Common infrastructure choices include:
- Cloud compute: AWS, Azure, Google Cloud, and specialized GPU clouds for training and inference.
- Containers and orchestration: Docker and Kubernetes for repeatable deployments and scaling.
- Inference acceleration: GPU autoscaling, model quantization, and optimized serving layers.
- Secrets and identity: Vaults, IAM policies, token management, and service authentication.
- API management: Gateways for rate limiting, logging, caching, and failover.
If your product has unpredictable demand, managed inference is often the right early move. If your workload is stable and large, dedicated hosting or private inference can make more financial sense.
B. Data Components
Your data layer often includes:
- Operational databases: PostgreSQL, MySQL, MongoDB, or data warehouses.
- Vector databases: Pinecone, Weaviate, Milvus, Qdrant, or pgvector.
- Data pipelines: Airbyte, Fivetran, Kafka, Debezium, or custom ETL jobs.
- Document processing: OCR, parsers, chunking pipelines, metadata tagging, and cleaning.
- Feature stores: For ML-heavy systems with structured predictive features.
The truth is that vector search is only one part of retrieval quality. Good metadata, smart chunking, document freshness, and reranking usually matter just as much.
C. Model Components
This layer can include:
- Foundation models: Closed or open models for text, image, audio, code, or multimodal tasks.
- Embedding models: For semantic search and retrieval.
- Rerankers: To improve relevance after initial retrieval.
- Guard models: Toxicity filters, moderation models, and policy classifiers.
- Fine-tuning workflows: LoRA, adapters, or task-specific optimization pipelines.
- Model registry: Version control for models, prompts, and experiments.
For many teams, the winning architecture is hybrid. Use proprietary models where top-tier reasoning matters. Use open models where cost, sovereignty, or customization matters more.
D. Orchestration Components
Typical orchestration pieces include:
- Prompt management systems to version prompts and variables.
- Workflow engines to sequence steps, retries, and branching logic.
- Agent frameworks for tool use, memory, and planning.
- Session state stores such as Redis or database-backed memory.
- Fallback logic for retries, degraded modes, and safe responses.
If your AI feature performs more than one task, orchestration stops being optional. At that point, you are running a workflow engine whether you admit it or not.
E. Governance and Ops Components
As your stack matures, you will also find that responsible AI stops being a side topic and becomes part of how you design policies, choose models, and review outputs in production.
A production-ready artificial intelligence stack also needs:
- Observability: traces, token usage, latency dashboards, model-level metrics.
- Evaluation pipelines: offline benchmarks, replay tests, and human review loops.
- Security controls: prompt injection defenses, content filtering, access logging, and encryption.
- Compliance tooling: consent records, data residency controls, and retention policies.
- Cost monitoring: per-feature, per-user, and per-model spend visibility.
This is the layer executives notice late. They should notice it early.

Common AI Tech Stack Examples
The best AI Tech Stack examples in 2026 are not universal templates. They are fit-for-purpose architectures matched to product goals, constraints, and operating realities.
Example 1: Enterprise Knowledge Assistant
If you are building an internal AI enterprise assistant, your stack might look like this:
| Layer | Common AI Tech Stack Choices |
| Infrastructure | AWS or Azure, managed identity, private networking |
| Data | SharePoint, Confluence, PDFs, CRM data, vector DB |
| Model | Enterprise-approved LLM, embedding model, reranker |
| Orchestration | RAG workflow, access-aware retrieval, citations |
| Governance | SSO, audit logs, PII controls, response monitoring |
This design works because accuracy and access control matter more than creative output. You need grounded answers, not flashy answers.
Example 2: AI Support Copilot
An AI-powered support stack usually combines:
- Ticketing and CRM data
- Retrieval over help docs and policies
- A response generation model
- Intent classification and escalation logic
- Human handoff when confidence drops
This is where most companies see fast ROI. But only if they connect the copilot to clean support content and measure resolution quality instead of just response speed.
For example; For go-to-market teams, the most durable wins come when the assistant is wired directly into AI-powered CRMs so it can see tickets, accounts, and past interactions instead of working in isolation.
Example 3: Agentic Workflow Automation
A more advanced AI-Powered Tech Stack for operations or back-office automation may include:
- Workflow triggers from ERP, CRM, or email systems
- Tool-calling agents with strict permissions
- Structured outputs for downstream system actions
- Approval checkpoints for sensitive actions
- Full trace logging for every decision step
This architecture is powerful, but risky if rushed. Agentic AI systems need boundaries. The second an agent can write, buy, approve, or trigger external actions, governance has to become precise.
Criteria for Selecting the Right AI Tech Stack
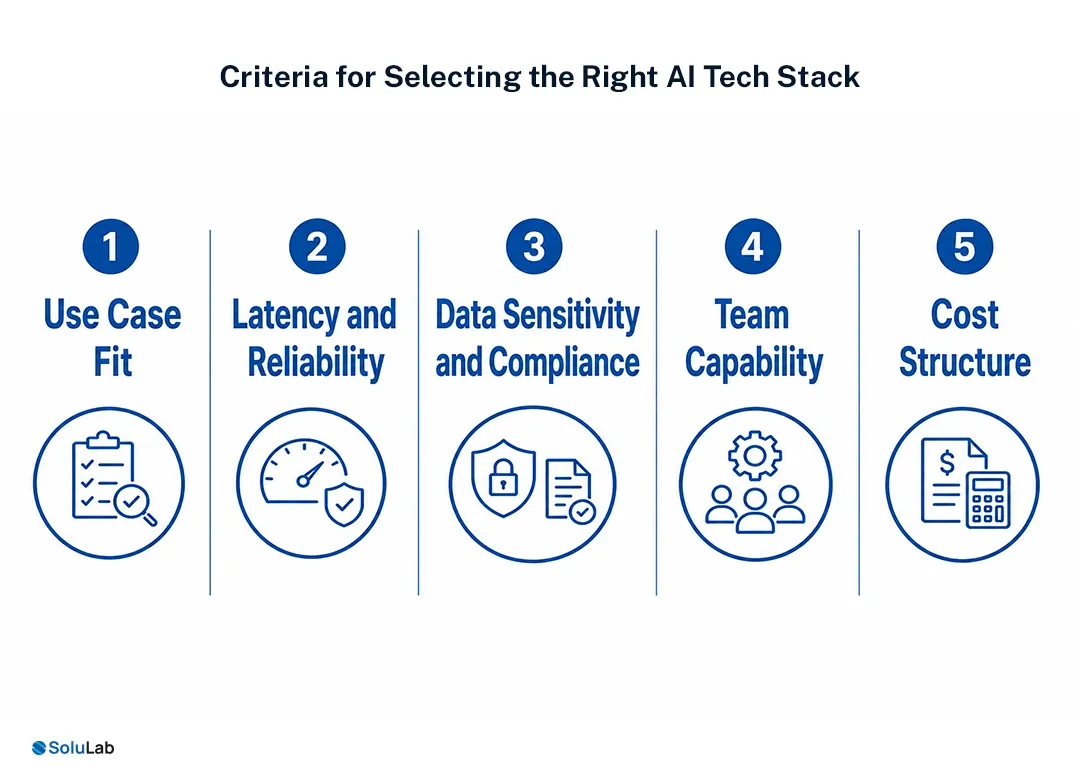
The right AI technology stack is the one that fits your use case, not the one that wins the most social media debates. Selection should start with workload reality.
1. Use Case Fit
Ask what the system must actually do. Search? Summarize? Generate code? Classify documents? Run autonomous workflows? The answer changes your stack dramatically.
Start by mapping the specific AI solutions you actually need to support automation, document understanding, analytics copilots, or agentic back‑office flows, and then assemble the minimum stack required to support those, instead of buying every new tool you see.
A support chatbot, an underwriting assistant, and a coding copilot should not share the same architecture by default. Too many teams start with tooling and only later define the work. An expert AI consulting service provider can help you in deciding the logic.
2. Latency and Reliability
If your users expect near-real-time responses, every layer has to support that target. Streaming helps. Caching helps. Smaller models help. Locality helps. Overengineered chains do not.
For voice, sales assistance, or live support, speed changes perceived intelligence. A mediocre answer in one second often feels better than a brilliant answer in twelve.
3. Data Sensitivity and Compliance
If you work in healthcare, finance, government, or enterprise IT, privacy requirements may eliminate half your options immediately. That is not a constraint to work around. It is a design input.
Data residency, audit trails, model hosting, and vendor contracts belong in the selection phase, not after procurement has already signed something expensive.
4. Team Capability
Be honest about what your team can run well. Self-hosting sounds powerful until no one wants to maintain GPU clusters, inference servers, prompt evaluations, and model updates.
Teams should buy complexity only when it becomes necessary. Until then, managed services are often the better strategic choice. For many organisations, the fastest way to de‑risk the first 12 months is to pair an in‑house product owner with an experienced AI development company that has shipped similar stacks before.
5. Cost Structure
Model cost is only one part of cost. You also pay for embeddings, vector storage, observability, retries, failed calls, engineer time, support load, and governance overhead.
If your internal team is still new to production AI, it is often smarter to bring in focused AI consulting services for the first architecture and roadmap, instead of learning expensive lessons in production.
The best stack is often the one with the clearest AI development cost visibility, not the cheapest unit price.
Best Practices for Building, Maintaining, and Scaling an AI Tech Stack
The best practices for maintaining and scaling an AI tech stack are modularity, evaluation discipline, observability, and cost control. Everything else sits downstream of those habits.
- Design for Replacement
Assume you will replace models. Assume you will change providers. Assume one layer will disappoint you. If your architecture cannot absorb change, it will age badly.
Use interfaces, abstraction layers, and provider-agnostic workflows where practical. Not everywhere. Just at the points most likely to change.
- Build Evaluation Before You Scale
Do not wait until launch to measure quality. Create a test set early. Include happy paths, edge cases, adversarial prompts, and domain-specific failure cases.
This is where strong teams separate themselves. They do not ask, “Does it feel good?” They ask, “Does it consistently meet the quality bar on known tasks?”
- Use Model Routing
One model for everything is lazy architecture. Route easy tasks to cheap models. Route sensitive tasks to safer models. Route deep reasoning tasks to stronger models.
That single move can reduce cost, improve response times, and create your AI software stack far easier to defend to finance leaders.
- Ground Answers in Data
If your system answers factual or policy-heavy questions, retrieval should be standard. Prompt-only systems are fragile. Grounded systems are more useful, easier to audit, and easier to improve.
If an answer affects revenue, compliance, customer trust, or internal operations, you should be able to trace where it came from.
- Instrument Everything
Track latency, token usage, retrieval hit rates, answer quality, fallbacks, user feedback, and failure modes. If you cannot see the chain, you cannot fix the chain.
Observability is not glamorous. It is also the part that saves you when executives ask why costs doubled after launch.
- Keep Humans in the Loop Where It Matters
Not every workflow should be fully autonomous. Put approvals around high-risk actions, financial decisions, legal wording, or customer-impacting changes.
The strongest stacks do not remove humans everywhere. They remove humans where judgment is repeatable and preserve them where accountability matters.
Challenges and How to Overcome Them
The biggest challenges in modern AI tech stacks are hallucinations, cost drift, latency, security exposure, and operational complexity. None of these are unsolved, but all of them punish careless architecture.
| Challenge | Why it happens | How to overcome it |
| Hallucinations | Weak grounding, poor prompts, no validation | Use retrieval, structured outputs, citation checks, and fallback responses |
| High latency | Large models, long chains, slow retrieval | Cache aggressively, shorten context, route tasks, optimize retrieval |
| Cost sprawl | Overuse of premium models, retries, token waste | Add budget visibility, route models, compress prompts, monitor usage |
| Prompt injection | Untrusted inputs manipulate tool behavior | Use input sanitization, permission boundaries, output validation |
| Data leakage | Sensitive context reaches the wrong model or user | Enforce access control, PII masking, secure logging, tenant isolation |
| Workflow brittleness | Too many chained steps and hidden dependencies | Simplify flows, test each node, build fallback paths |
The truth is that most of these problems show up slowly. Teams think the pilot is working, then scale exposes the weak points. That is why architecture reviews matter before traffic ramps, not after.

Future Trends in AI Tech Stacks for 2026–2027
The next phase of the AI Tech Stack is moving toward modular, multimodal, governed, and increasingly agentic systems. You will still see bigger models, but the more important trend is better system design around them.
Over the next 12–18 months, many high-value workflows will shift from single-channel chatbots to multimodal AI agents that can reason across text, documents, screenshots, and even short video clips inside the same task.
- Smaller Models Will Keep Winning More Work
Large language models will remain important, especially for deep reasoning. But many production tasks will shift toward smaller, cheaper, specialized models because the economics are better and latency is lower.
That means your future stack will likely become more heterogeneous, not less.
- Retrieval Will Become More Structured
RAG is maturing from “dump documents into a vector database” to cleaner knowledge pipelines with metadata discipline, reranking, freshness logic, and hybrid search. This is a healthy shift.
As stacks mature, retrieval quality will become a competitive moat rather than a checkbox.
- Agent Governance Will Tighten
As AI agents gain more permissions, companies will demand stricter policy enforcement, richer traceability, and clearer approvals. Agent freedom without control will not survive enterprise buying cycles.
Expect governance tooling to become a standard part of the artificial intelligence technology stack, not an add-on.
- Multimodal Architectures Will Become Normal
Text-only systems will increasingly feel incomplete. Teams will combine text, voice, image, and document intelligence in one workflow.
That changes storage, retrieval, latency planning, and evaluation. Your stack needs to be ready for that convergence.
FAQs
Conclusion
A strong AI Tech Stack is not the flashiest collection of tools. It is the system that gives you dependable output, reasonable cost, operational control, and room to evolve. Done well, your AI Tech Stack becomes the backbone of your AI software development efforts, not just a one‑off experiment attached to a single feature.
If you are designing for 2026, focus on the key layers of an AI technology stack, keep your components modular, and make evaluation part of the product, not a side task. In the real world, the teams that win are not the teams with the loudest AI narrative. They are the teams with the cleanest architecture, the clearest business fit, and the discipline to keep improving after launch.
Done well, your AI Tech Stack becomes the backbone of your AI software development efforts, not just a one‑off experiment attached to a single feature.
If you are auditing your current AI technology stack right now, start with three questions: which layer is causing the most friction, which feature is generating the most model cost, and where are users losing trust? Fix those first. That is usually where the real leverage sits.
Shipra Garg is a tech-focused content strategist and copywriter specializing in Web3, blockchain, and artificial intelligence. She has worked with startups and enterprise teams to craft high-conversion content that bridges deep tech with business impact. Her work translates complex innovations into clear, credible, and engaging narratives that drive growth and build trust in emerging tech markets.

![How to Build an AI Agent With OpenAI? A Business Guide [2026]](https://www.solulab.com/wp-content/uploads/2026/06/Roadmap-to-Developing-AI-Agents-with-OpenAI.webp)
