

Arabic is a complicated and multi-layered language with variations between Modern Standard Arabic (MSA) and regional dialects.
Although generic NLP models show good performance on MSA, they fail to comprehend local dialects of the UAE because of specific vocabulary, syntax, and cultural allusions. The drawback causes inaccurate text analysis, misinterpretation of chatbots, and bad user experiences with AI-powered applications.
Arabic NLP benchmarks offer standardized testing data, though the majority of them concentrate on formal Arabic, and the dialects of the region are not well represented.
Fills in this gap by collaborating with an AI development solutions provider and creating dialect-conscious datasets and fine-tuning models on UAE-specific texts and speech, as well as by adopting assessment models that can guarantee that AI systems perceive and react properly within the local context.
Key Takeaways
- The Problem: Generic Arabic NLP models are trained on Modern Standard Arabic (MSA) and do not recognize local UAE dialects, which results in chatbot misinterpretation, sentiment analysis, and voice assistant misinterpretation.
- The Solution: Dialect-conscious NLP benchmark and datasets reflect the special words, sentences, and expressions of Emirati Arabic. Refinement of models on such benchmarks helps in proper comprehension and practical application.
- How SoluLab Helps: SoluLab builds local NLP pipelines to dialects of the UAE based on local data collection, annotation, and fine-tuning. Their solutions enhance the accuracy of the models so that the businesses can deploy AI applications that can understand and react to the language used in the region.
What Are Arabic NLP Benchmarks?
Arabic NLP benchmarks refer to standardized data sets and evaluation models that can be applied to natural language processing (NLP) models to test their ability to comprehend and process the Arabic language.
Enterprise Arabic NLP assists the researchers and businesses in making comparisons on the model performances in various tasks such as text classification, sentiment analysis, named entity recognition (NER), question answering, and machine translation.
In contrast to English benchmarks, Arabic ones should take into consideration the rich morphology of the language, complicated grammar, and a large variety of dialects. Arabic has Modern Standard Arabic (MSA) and various regional dialects: Gulf, Egyptian, Levantine, and Maghrebi Arabic – all of which have dissimilar vocabulary, spelling, and structure.
Why They Matter?
- Compare generic and Arabic-specialized models.
- Test the accuracy of dialect understanding.
- Determine training statistical holes.
Enhance AI in chatbots, voice assistants, financial technologies, healthcare, and government services. Moreover, top models reach ~74% accuracy on dialect tasks even when large and region-adapted.
Why Generic Models Underperform UAE and Gulf Dialects?
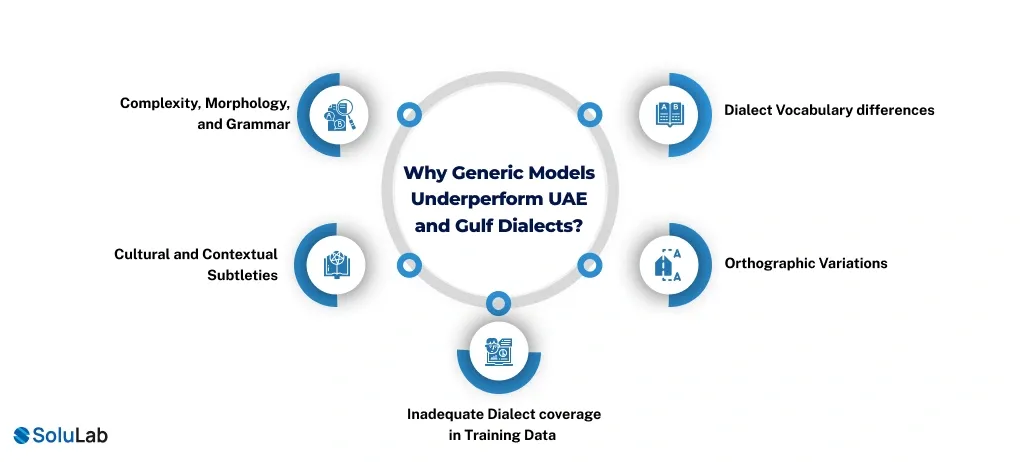
Due to the difference between the UAE and Gulf dialect and Modern Standard Arabic, generic NLP models are often ineffective in real-life use of Arabic and have difficulties with the accuracy of understanding the specifics, the accuracy of intent recognition, and decoding the situation.
1. Dialect Vocabulary differences: UAE and Gulf dialects apply the use of everyday expressions, slang, and borrowed words that are not frequently found in the Modern Standard Arabic datasets. Mechanical models that are mostly trained on formal text are unable to recognize these local words, making them less accurate in their interactions with customers and the conversational artificial intelligence.
2. Orthographic Variations: Social media and messaging platforms often use dialectal Arabic in writing that does not have spelling standards. Even the same word can be represented in several written forms, and this presents a puzzle to generic models that are based on structured and standardized training data.

3. Inadequate Dialect coverage in Training Data: The vast majority of big language models are trained on high-resource languages or formal Arabic corpora. There is a lack of Gulf dialect, which results in performance disparities in the event of models dealing with region-specific conversations, sentiment, or intent.
4. Cultural and Contextual Subtleties: The UAE language is characterized by references to the culture, regional humor, and norms. Chatbots, voice assistants, and automated support systems are prone to misinterpretation due to the missed subtle contextual details in generic models.
5. Complexity, Morphology, and Grammar: The Arabic dialects make grammar simple or alter it as opposed to the Modern Standard Arabic. Formal structure-based generic models have difficulty in parsing dialect sentence structure, which has a negative impact on translation, classification, and question-answer tasks.
How SoluLab Addresses These Challenges?
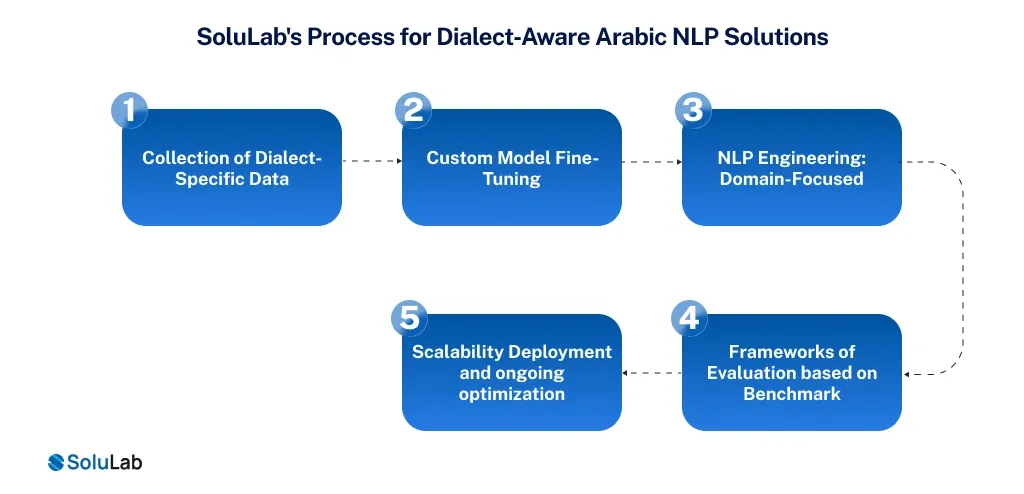
SoluLab uses a localization-first AI-led development approach to speech recognition, defense against dialect gap, data constraint, and benchmark flaws in Arabic NLP, designed specifically to apply to the linguistic and business context in the UAE.
1. Collection of Dialect-Specific Data
SoluLab collects and trains Emirati and Gulf Arabic data on the basis of real-world data, ensuring models learn authentic vocabulary, slang, spelling, and cultural subtleties that are usually absent in generic Arabic NLP training.
2. Custom Model Fine-Tuning
Rather than using the pre-trained generic models, SoluLab also fine-tunes large language models on local data to enhance intent recognition, sentiment accuracy, and contextual understanding across variations of the UAE dialect.
3. NLP Engineering: Domain-Focused
SoluLab fits models to particular industries (government, fintech, healthcare, and retail) to make sure that terminology, compliance requirements, and the way to communicate with customers are well-portrayed in AI results.
4. Frameworks of Evaluation based on Benchmark
To test the actual performance, the team constructs tailored evaluation pipelines with dialect-sensitive benchmarks that would help to eliminate the chances of inaccurate output due to MSA-only testing datasets.
5. Scalability Deployment and ongoing optimization
To create a continuous improvement cycle, monitor, and feedback loop, SoluLab deploys Arabic NLP systems to achieve constant improvement, support new dialect expressions, and High-scale performance.
Best Practices for Dialect‑Aware Arabic NLP
Standard models are not enough to make Arabic NLP systems effective. Dialect-conscious solutions are used in order to achieve real-world correctness through considering local vocabulary, morphology, and syntax, particularly in UAE Arabic and Gulf Arabic in enterprise systems.
- Collect Local Dialect Data: Utilize texts, speech, and social media sources that are unique to the UAE and Gulf Arabic. The models that are trained with the use of authentic local expressions get much better than those that are trained only on Modern Standard Arabic.
- Context and Semantics Annotation: Tag data with sentiment, intent, and named entities, factoring in dialect-specific peculiarities. When annotated properly, the level of misclassification is minimized, and chatbots and voice assistants gain a better comprehension.
- Fine-Tune Pretrained Models: Customize generic Arabic LLMs with dialect-specific data. Fine-tuning is useful in capturing the idiomatic expressions, orthographic, and syntax peculiar to the regional dialect.
- Constant Assessment using Dialect Benchmarks: Periodically evaluate models on dialect-oriented test sets, e.g, Emirati or Gulf Arabic test sets, to make sure they can be used in the real world, and to monitor the progress over time.
- Incorporate Feedback Loops: Gather user interactions and errors to refine models. The systems can be adjusted to the changing local language trends and slang with the help of feedback-related updates.

Conclusion
The Arabic dialects of NLP can be problematic because generic models are mostly trained on Modern Standard Arabic, and local-specific vocabulary, morphology, and cultural background do not receive attention.
This causes misunderstandings in chatbots and sentiment analysis, among other uses. Dialect-sensitive performance benchmarks on Emirati and Gulf Arabic demonstrate these gaps in performance, and thus, dialect-sensitive solutions are necessary.
SoluLab, an AI integration solution provider, addresses these issues by gathering local dialectal data, optimizing models, and deploying dialect-specific evaluation systems, thereby making them more accurate and useful. Book a free discovery call today to discuss further!
FAQs
Neha is a curious content writer with a knack for breaking down complex technologies into meaningful, reader-friendly insights. With experience in blockchain, digital assets, and enterprise tech, she focuses on creating content that informs, connects, and supports strategic decision-making.


