Artificial intelligence has evolved from being a luxury to a necessity in today’s competitive market. A thorough grasp of the AI technology stack is advantageous and required for developing innovative approaches capable of transforming corporate processes. AI has revolutionized and upgraded how we engage with technology, and the AI tech stack is essential for this shift.
This article will go over every aspect of the AI tech stack, which can help users to generate new data similar to the dataset on which it was trained. Understanding the AI technology stack can provide significant benefits to businesses looking to develop novel AI applications. So, let’s get started!
The fundamental set of equipment, technologies, and infrastructure needed to create, implement, and oversee artificial intelligence systems is known as an AI Tech Stack. It is the foundation of AI initiatives that allow developers and companies to create intelligent solutions and optimize workflows.
From data processing and model building to deployment and monitoring, the generative AI tech stack covers a wide range of AI development activities. It offers a methodological way to incorporate AI capabilities into apps and guarantees capability, effectiveness, and flexibility in dynamic commercial settings. Organizations can simplify intricate AI processes, cut down on development time, and concentrate on addressing certain issues by utilizing an AI tech stack.
The tech stack for AI is a structural arrangement made up of interconnected layers, each of which plays an important role in ensuring the system’s efficiency and efficacy. Unlike a monolithic design, in which each component is closely connected and entangled, the AI stack’s layered structure promotes flexibility, scalability, and ease of troubleshooting. The fundamental elements of this architecture consist of APIs, machine learning algorithms, user interfaces, processing, storage, and data input. These layers serve as the core foundations that underpin an AI system’s complex network of algorithms, data pipelines, and application interfaces. Let’s go further into what these layers are all about!
The application layer is the topmost one and is the physical representation of the user experience. It includes everything from web applications to REST APIs that regulate data flow between client-side and server-side contexts. This layer is in charge of crucial functions such as using GUIs to collect input, dashboards to present visualizations, and API endpoints to provide insights based on data. Both Django for the backend and React for the frontend are widely utilized because of their respective advantages in tasks like data validation, user authentication, and routing API requests. As an entrance point, the Application Layer directs user queries to the machine-learning models underneath it while maintaining stringent security protocols to guarantee data integrity.
The Model Layer serves as the engine room for decision-making and data processing. This layer serves as an intermediate, receiving data from the Application Layer, doing computation-intensive activities, and then returning the insights to be presented or acted upon. TensorFlow and PyTorch are specialized libraries that provide a diverse toolbox for a variety of machine learning operations including natural language processing NLP applications, computer vision, and predictive analytics. This layer incorporates feature engineering, model training, and hyperparameter optimization. A variety of machine learning methods, from complex neural networks to regression models, are assessed using performance metrics like F1-score, accuracy, and recall.
The Infrastructure Layer plays an essential role in both model training and inference. This layer allocates and manages computing resources like CPUs, GPUs, and TPUs. This layer involves the use of orchestration technologies like Kubernetes for container management to build scalability, latency, and fault tolerance. The demanding computing can be handled on the cloud side by services like Azure’s AI-specific accelerators and AWS’s EC2 instances. This infrastructure is an ever-evolving system that is intended to allocate resources wisely, not just to passively receive requests. To meet the specific requirements of the aforementioned levels, load balancing, data storage options, and network latency are all made to ensure that processing capacity constraints do not become a roadblock.
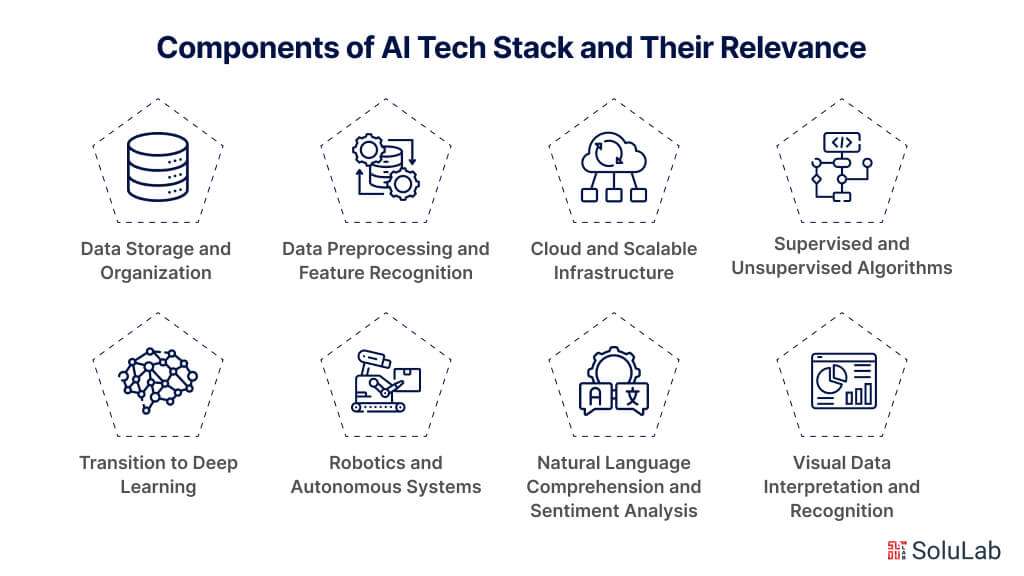
The architecture of artificial intelligence (AI) solutions consists of numerous modules, each focused on separate tasks yet cohesively interconnected for overall operation. From data input to ultimate application, this complex stack of technologies is crucial to developing AI capabilities. The Gen AI tech stack is made up of the following components:
The first stage in AI processing is to store data securely and efficiently. Storage solutions like SQL databases for structured data and NoSQL databases for unstructured data are critical. For large-scale data, Big Data solutions such as Hadoop’s HDFS and Spark’s in-memory processing are required. The kind of storage choice has a direct influence on the retrieval of information speed, which is critical for real-time data analysis and machine learning.
Following storage comes the tedious work of data preparation and feature recognition. Normalization, missing value management, and outlier identification are all part of preprocessing, which is done in Python with packages like Scikit-learn and Pandas. Feature recognition is critical for decreasing dimensionality and is carried out by utilizing methods such as Principal Component Analysis (PCA) or Feature Importance Ranking. These cleaned and reduced features are used as input for machine learning algorithms, resulting in higher efficiency and precision.
Once the preprocessed data is accessible, machine learning methods are used. Support Vector Machines (SVMs) for categorization, Random Forest for ensemble learning, and k-means for clustering all serve distinct functions in data modeling. The algorithm used has a direct influence on computing efficiency and predicted accuracy, thus it must be appropriate for the situation.

Traditional machine-learning techniques may fail to meet the increasing complexity of computing issues. This requires the usage of deep learning frameworks like TensorFlow, PyTorch, or Keras. These frameworks facilitate the design and training of complicated neural network topologies such as Convolutional Neural Networks (CNNs) for recognition of images and Recurrent Neural Networks (RNNs) for sequential data processing.
When it comes to reading human language, Natural Language Processing (NLP) libraries including NLTK and spaCy form the base. Transformer-based models, such as GPT-4 or BERT, provide more comprehension and context recognition for complex applications, such as sentiment analysis. These NLP tools and models are often included in the AI stack after deep learning parts for applications that need natural language interaction.
In the visual data space, computer vision technologies like OpenCV are essential. CNNs can be applied to complex tasks like object identification, facial recognition, and more. These computer vision components frequently collaborate with machine learning techniques to facilitate multi-modal analysis of information.
Sensor fusion methods are used in physical applications such as robotics and autonomous systems. Simultaneous Localization and Mapping (SLAM) and algorithms for making decisions such as Monte Carlo Tree Search (MCTS) are used. These features work in tandem with the machine learning and computer vision components to power the AI’s capacity to communicate with its environment.
The whole AI technology stack is frequently powered by cloud-based infrastructure such as AWS, Google Cloud, or Azure. As a facilitator, the cloud infrastructure makes it possible for all of the previously described elements to work together smoothly and efficiently. In cloud-first AI deployments, observability is critical for both performance and cost control. An AWS monitoring platform correlates metrics, logs, and usage data to surface savings opportunities and enable proactive optimization as workloads scale.
Read More: AI x Web3 Execution Playbook
AI frameworks serve as the foundation for future-proof applications, which enable them to learn, adapt, and improve over time. These frameworks allow developers to change how systems interact with data and make decisions by incorporating powerful computational intelligence into applications.
Computational intelligence is the basis of artificial intelligence applications since it lets systems learn from data and form decisions. Deep learning models and machine learning (ML) help apps to independently control challenging situations. TensorFlow, PyTorch, and Keras among other frameworks provide tools for apps to develop and train these models, therefore enabling tasks including predictive analytics and image and speech recognition. While deep learning models, including neural networks, help to tackle difficult, data-heavy tasks requiring pattern recognition, reinforcement learning allows systems to learn by trial and error technique, continuously improving decision-making.
AI models heavily rely on high-quality data operations to perform effectively. Before AI models can make predictions or decisions, data must be properly prepared and processed. This includes:
For AI models to be reliable, they must undergo rigorous performance testing. Performance assessment ensures that AI models meet expectations and can operate under varying conditions. Key performance metrics include:
Therefore, testing is done using methods like cross-validation, where models are trained on different subsets of data to ensure they generalize well across various scenarios.
After training and testing, an AI model is ready to be implemented in practical applications. It is necessary to optimize the model for live performance in this step. In this last phase of the development lifecycle of an AI application, the solution is moved from the development environment to the actual world. This stage is important because it establishes how well the AI system works in real-time and connects with the infrastructure that already exists.
The importance of a precisely chosen technological stack in building strong AI systems cannot be emphasized. Machine learning frameworks, programming languages, cloud services, and data manipulation utilities all play important roles. The following is a detailed breakdown of these important components.
The construction of AI models needs complex machine-learning frameworks for inductive and training purposes. TensorFlow, PyTorch, and Keras are more than just libraries; they are ecosystems that provide a plethora of tools and Application Programming Interfaces (APIs) for developing, optimizing, and validating machine learning models. They also provide a variety of pre-configured models for jobs including natural language processing to computer vision. Such frameworks need to serve as the foundation of the technological stack, providing opportunities to alter models for specific metrics like accuracy, recall, and F1 score.
The selection of programming language has an impact on the harmonic equilibrium between user accessibility and model efficiency. Python is often used in machine learning due to its readability and extensive package repositories. While Python is the most popular, R and Julia are widely used, notably for statistical evaluation and high-performance computing work.
Generative AI models require significant computational and storage resources. The inclusion of cloud services into the technological stack provides these models with the necessary power. Services like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure provide configurable resources including virtual machines, as well as specific machine learning platforms. The cloud infrastructure’s inherent scalability means that AI systems can adapt to changing workloads without losing performance or causing outages.
Raw data is rarely appropriate for rapid model training; preprocessing techniques such as normalization, encoding, and imputation are frequently required. Utilities such as Apache Spark and Apache Hadoop provide data processing capabilities that can handle large datasets efficiently. Their enhanced data visualization feature supports exploration data analysis by allowing for the discovery of hidden trends or abnormalities within the data.
By systematically choosing and combining these components into a coherent technological stack, one may create not just a functioning, but also an optimal AI system. The resulting system will have increased precision, scalability, and dependability, all of which are required for the fast growth and implementation of AI applications.
The combination of these carefully picked resources creates a technological stack that is not only comprehensive but also important in obtaining the greatest levels of performance in AI systems.
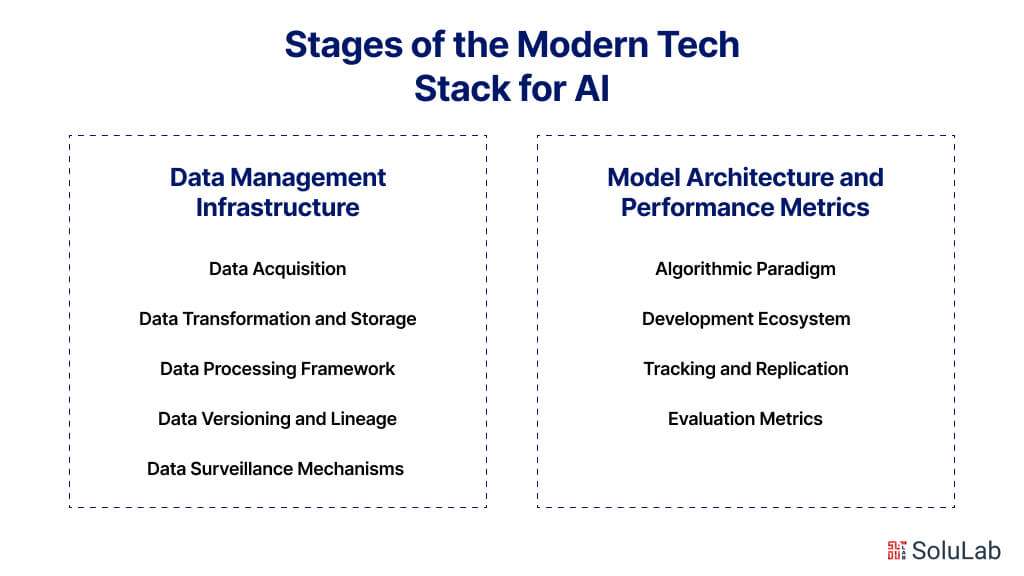
A methodical approach is essential for efficiently building, deploying, and scaling AI systems. This complicated framework serves as the foundation for AI applications, providing a tiered approach to addressing the various issues associated with AI development. This framework is often separated into phases, each tasked with handling a certain element of the AI life cycle, that includes data management, data transformation, and machine learning, among others. Let’s look at each phase to see how important each layer is, as well as the tools and approaches used.
Data is the driving force behind machine learning algorithms, analytics, and, eventually, decision-making. Therefore, the first section of our AI Tech Sttalk focuses on Data Management Infrastructure, a critical component for gathering, refining, and making data usable. This phase is separated into multiple stages, each focused on a different component of data handling, such as data acquisition, transformation, storage, and data processing frameworks. We will deconstruct each level to offer a thorough grasp of its mechanics, tools, and relevance.
1.1 Data Aggregation
The data-collecting method is a complicated interplay between internal tools and external applications. These various sources combine to provide an actionable dataset for future operations.
1.2 Data Annotation
The collected data goes through a labeling procedure, which is required for machine learning in a supervised setting. Automation has gradually replaced this arduous job with software solutions such as V7 Labs and ImgLab. Nonetheless, manual verification is necessary owing to algorithmic limits in finding outlier occurrences.
Read Also: What is Data Annotation?
1.3 Synthetic Data Generation
Despite the large amounts of available data, gaps persist, particularly in narrow use cases. As a result, techniques like TensorFlow and OpenCV have been used to generate synthetic picture data. Libraries like SymPy and Pydbgen are used for expressing symbols and categorical data. Additional tools, such as Hazy and Datomize, provide interaction with other platforms.
2.1 Data Transformation Mechanisms
ETL and ELT are two competing concepts for data transformation. ETL emphasizes data refinement by briefly staging data for processing prior to ultimate storage. In contrast, ELT is concerned with practicalities, putting data first and then changing it. Reverse ETL has arisen as a method for synchronizing data storage with end-user interfaces such as CRMs and ERPs, democratizing data across applications.
2.2 Storage Modalities
Data storage techniques vary, with each serving a distinct purpose. Data lakes are excellent at keeping unstructured data, while data warehouses are designed to store highly processed, structured data. An assortment of cloud-based systems, such as Google Cloud Platform and Azure Cloud, provide extensive storage capabilities.
3.1 Analytical Operations
Following acquisition, the data must be processed into a consumable format. This data processing step makes extensive use of libraries such as NumPy and pandas. Apache Spark is an effective tool for managing large amounts of data quickly.
3.2 Feature Handling
Feature stores like Iguazio, Tecton, and Feast are critical components of effective feature management, considerably improving the robustness of feature pipelines among machine-learning systems.
Versioning is crucial for managing data and ensuring repeatability in a dynamic context. DVC is a technology-agnostic tool that smoothly integrates with a variety of storage formats. On the lineage front, systems such as Pachyderm allow data versioning and an extensive representation of data lineage, resulting in a cohesive data story.
Censius and other automated monitoring tools help preserve data quality by spotting inconsistencies such as missing values, type clashes, and statistical deviations. Supplementary monitoring technologies, such as Fiddler and Grafana, provide similar functions but add complexity by measuring data traffic quantities.
Modeling in the field of machine learning and AI is an ongoing procedure that involves repeated developments and assessments. It starts following the data has been collected, properly stored, examined, and converted into functional qualities. Model creation should be approached via the perspective of computational restrictions, operational conditions, and data security governance rather than merely algorithmic choices.
Machine learning libraries include TensorFlow, PyTorch, scikit-learn, and MXNET, each having its own selling point—computational speed, versatility, simplicity of learning curve, or strong community support. Once a library meets the project criteria, one may begin the normal operations of model selection, parameter tweaking, and iterative experimentation.
The Integrated Development Environment (IDE) facilitates AI and software development. It streamlines the programming workflow by integrating crucial components such as code editors, compilation procedures, debugging tools, and more. PyCharm stands out for its simplicity of handling dependencies and code linking, which ensures the project stays stable even when switching between engineers or teams.
Visual Studio Code (VS Code) comes as another dependable IDE that is extremely adaptable between operating systems and has connections with external tools such as PyLint and Node. JS. Other IDEs, like as Jupyter and Spyder, are mostly used throughout the prototype phase. MATLAB, a longtime academic favorite, is increasingly gaining traction in business applications for end-to-end code compliance.
The machine learning technology stack is fundamentally experimental, necessitating repeated testing spanning data subsets, feature engineering, and resource allocation to fine-tune the best model. The ability to duplicate tests is critical for retracing the research path and manufacturing implementation.
Tools such as MLFlow, Neptune, and Weights & Biases make it easier to track rigorous experiments. At the precise same time, Layer provides one platform for handling all project metadata. This assures a collaborative environment that can adapt to scale, which is an important consideration for firms looking to launch strong, collaborative machine learning initiatives.
In machine learning, performance evaluation entails making complex comparisons across many trial outcomes and data categories. Automated technologies like Comet, Evidently AI, and Censius are quite useful in this situation. These tools automate monitoring, allowing data scientists to concentrate on essential goals rather than laborious performance tracking.
These systems offer standard and configurable metric assessments for basic and sophisticated use cases. Detailing performance difficulties with additional obstacles, such as data quality degradation or model deviations, is critical for root cause investigation.
Modern businesses are quite interested in using Artificial intelligence (AI) in their operations as it encourages technological advancement, for that picking the right AI technology stack is important. An AI tech stack consists of the tools, frameworks, libraries, and systems that facilitate data processing, models, and AI deployment. Making the right choice is essential to ensure effectiveness, scalability, and alignment with the business goals.
Before starting the selection of the AI tools and technologies, take a step back to assess your project’s needs first. For that ask yourself the following things:
Your answers to these questions will guide you in selecting the right tech stack that aligns with your specific business needs.
AI projects generally involve big datasets and require a good amount of computational capacity. To accommodate the ever-changing needs the chosen tech stack must be scalable enough. Frameworks like Apache Spark, facilitate distributed processing and can be useful when working with big datasets or when you need to grow fast. Also, make sure the stack you’ve selected supports optimization strategies that boost throughput and lower latency, especially if your application needs real-time processing.
The evolution of AI and machine learning technology necessitates flexibility for personalization. One should be able to modify and add additional methods with the selected stack. Some frameworks, like PyTorch, offer greater flexibility in the construction of model architectures, while others, such as Keras, offer higher-level abstraction for quicker prototyping but with fewer customization choices. Also, you should be able to easily link your stack with other services and systems.
Open-source frameworks are frequently used because they are inexpensive. Licensing fees and cloud service expenses may add up when using these on a large scale. Open-source tools (such as Scikit-learn, PyTorch, and TensorFlow) are popular and free to use, but may not have enterprise-level support. Paid options, like AWS AI or Microsoft Azure AI, offer more services and support but may have usage-based fees.
Security and compliance should be top priorities, especially for AI applications that handle sensitive data. For AI systems that manage sensitive data, security and compliance should come first. Make sure the stack you have selected complies with all applicable laws and offers sufficient safety features. Consider the technology that facilitates data encryption and adherence to regulations such as GDPR or HIPAA.
By embracing these emerging technologies and advancements, organizations can stay ahead of the curve and leverage the full potential of the AI tech stack to drive innovation and achieve business objectives.

To summarize, traversing the AI tech stack is like beginning a voyage across the limitless worlds of creativity and opportunity. From data collecting to model deployment and beyond, each tier of the stack brings unique problems and possibilities, influencing the future of AI-powered solutions across sectors. As we look ahead at developing trends and breakthroughs, it’s apparent that the growth of the AI tech stack will continue to drive revolutionary change, allowing organizations to reach new levels of efficiency, intelligence, and value creation.
If you want to start your AI experience or need expert coaching to traverse the intricacies of the AI tech stack, SoluLab is here to help. As a top AI development company, we provide a team of experienced individuals with knowledge in all aspects of AI technology and processes. Whether you want to hire AI developers to create unique solutions or need strategic advice to connect your AI activities with your business goals, SoluLab is your reliable partner every step of the way. Contact us today to see how we can help you achieve every advantage of AI and catapult your company into the future.
Artificial intelligence technology is a collection of technologies that provides computers the capacity to carry out a wide range of sophisticated tasks such as data analysis, making recommendations, speech, and text recognition.
An LLM, a means of supplying company information, AI guardrails, a simple user interface, and the capacity to guarantee security, privacy, and governance are all components of a GenAI full-stack platform
AI tech stack consists of key layers that include collecting data, storing the obtained data, making use of machine learning algorithms, modern layer, and infrastructure layer.
The tech stack in machine learning is a reference model that enumerates all of the infrastructure parts needed to develop, train, implement, and expand machine learning systems.
Simply reach out to us through our website or contact us directly to discuss your project requirements. Our team will work closely with you to understand your objectives, assess your needs, and recommend the best-suited experts for your project.

